
Metodo per la progettazione di un sistema Line Array per la sonorizzazione di un’area di ascolto.
Quanto segue è parte integrante dell’articolo: Appunti per P.A. Manager.
Ascolto immersivo (3D)
Posizionare una cassa in alto, a destra o a sinistra, davanti o dietro e mandargli un segnale audio non è un tipo di ascolto 3D o immersivo, rimane all’interno del contesto sorgenti sonore, ed è solo un bilanciamento sulla provenienza di un suono dalla sorgente stesse, un po’ come avviene per i mix in surround classici.
Per ottenere un ascolto immersivo è necessario un motore di rendering (Object Based Engine), che sia un processore dedicato o tramite PC via Software, inserendo il numero di sorgente sonore utilizzate e qualche altro dato di riferimento (dipende dal software utilizzato), l’algoritmo processerà ampiezza, fase e tempo in modo indipendente per ognuna di queste sorgenti e definirà la precisa posizione in cui l’oggetto sonoro verrà sentito, e lo farà in tempo reale seguendo gli spostamenti che si deciderà di dare all’oggetto sonoro (la nostra sorgente sonora), con una latenza che dipenderà dal tipo di processamento e buffering del segnale audio cosi impostato.
I metodi di panning 3D più utilizzati in campo audio 3D sono quello di ricreare un suono immersivo con un numero definito di canali a disposizione attorno ad un ascoltatore (N.Channels), quello di creare un suono immersivo indipendente dal numero di canali ma attraverso una manipolazione del segnale audio in ingresso (Ambisonic), quello di creare un suono immersivo da un ascolto in cuffia (Binaural), e quello di creare un suono immersivo attraverso un campo sonoro indipendente dal numero e posizione degli ascoltatori (WFS).
Note: Per definire un oggetto più vicino o più lontano, il motore di rendering lavora non solo sul livello e tempo ed eventuale riverberazione ambientale aggiunta (generalmente a scelta dell’utente), ma anche sull’assorbimento dell’aria ed effetto doppler se si considera anche un movimento dello stesso.
Come base di partenza ci vuole come detto il motore di rendering (il software), a questo punto sarà necessario creare un ambiente virtuale (stanza) da cui partire, al cui centro sarà automaticamente posizionata la testa dell’ascoltatore (quindi il riferimento del punto di base per definire la posizione degli oggetti sonori).
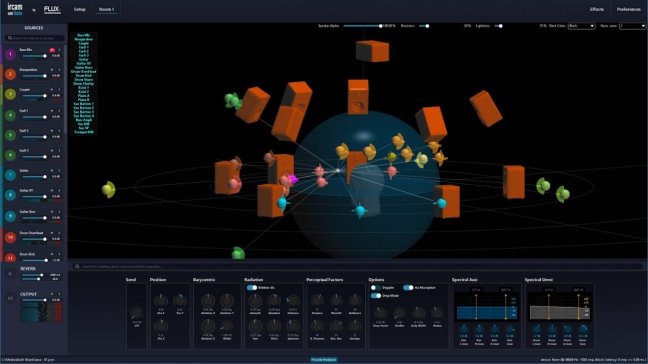
Nell’immagine di figura 1 (presa dal software Flux Spat Revolution) la testa grigia (Sweet Spot) siamo noi che ascoltiamo il suono, i diffusori virtuali arancioni sono i nostri diffusori reali, quindi dovremo impostare il software tale da considerare e gestire tutti i diffusori reali che vogliamo utilizzare e allo stesso modo dobbiamo interfacciare con il software tutti i canali di ingresso che vogliamo mixare in un contesto 3D (non entriamo nel merito tecnico dei collegamenti di interfacciamento tra software e scheda/mixer audio che vedremo in altri articoli).
Le sfere sono i nostri oggetti virtuali (ad esempio gli strumenti musicali da mixare in ambiente immersivo), se il loro colore è azzurro la loro percezione è planare alla nostra testa, se portiamo un oggetto sonoro ad essere percepito in alto diventa rosso, se lo portiamo in basso diventa grigio. Più allontaniamo un oggetto sonoro dallo Sweep Spot e più questo verrà percepito lontano, quindi la posizione degli oggetti sonori in relazione allo Sweep Spot va a definire dove la sorgente sonora verrà percepita.
In alcuni software è possibile modificare la posizione dello Sweep Spot creando un offset sulla percezione 3D, ed è inoltre possibile non far dipendere il processamento da uno Sweep Spot quindi definire arbitrariamente la posizione degli oggetti sonori o addirittura modificare la grandezza dello Sweep Spot stesso.
Fig. 1

Vedremo più in dettaglio in altri articoli come settare un processore per suono immersivo.
Progettazione
La progettazione di un ascolto immersivo non è diversa da quella appena vista, solo sarà necessario aggiungere elementi appositamente distanziati secondo lo standard seguito per ottenere una percezione 3D realistica.
Una delle configurazioni 3D più utilizzate è quella WFS (fig. 2) di più facile installazione in un contesto di concerto live all’aperto dove i ricettori sono spaziati all’interno di una grande Audience Area ma anche in ambiente chiuso di più facile installazione su di una linea orizzontale di sorgenti, c’è poi N Channels (fig. 2) con un installazione di sorgenti in modalità surround limitata al contesto teatrale e ambienti al chiuso per via della tipologia di installazione avendo la possibilità di avere un pubblico centrale e distribuirgli attorno un numero N di sorgenti sonore per l’ascolto spaziale.
Fig. 2

Fig. 3 

Come linea generica si può dire che il WFS è un sistema 3D di più facile installazione con un numero di sorgenti “da distribuire” relativamente più contenuto rispetto al N Channels per ottenere l’effetto spaziale desiderato basandosi sulla differenza di tempo e livello per far capire provenienza e dimensione del suono percepito, tanto è vero che in questo caso si parla di oggetti sonori e non sorgenti sonore, in quanto che l’effetto spaziale non dipende relativamente dalla posizione della sorgente stessa. L’N Channel invece è un più simile al contesto classico con sorgenti dispiegate attorno al ricettore e attivando l’una piuttosto che l’altra si da l’esatta posizione e dimensione del suono percepito, quindi in questo caso si utilizzano direttamente i livelli delle sorgenti per definire l’ascolto spaziale.
Il sistema WFS rispetto a quella N Channel ha il vantaggio che non essendo dipendente dalla posizione fisica del diffusore quando sposto una sorgente nello spazio tutti sentiranno quella sorgente in quel punto dello spazio, mentre nel sistema N Channel che è invece dipendente dalla posizione fisica del diffusore, se ad esempio sposto la sorgente sonora a sinistra chi si troverà ad ascoltare a sinistra sentirà questa sorgente provenire da sinistra con un più alto livello e grande dimensione di chi si trova ad ascoltare più lontano e a destra.
C’è da dire però che di contro il più attuabile sistema WFS per un contesto Live Pro ha che avendo più sorgenti ravvicinate rispetto ad un sistema N Channels (anche se questo dipende sempre dal numero di elementi che si vuole installare), incombe in maggiori interferenze che alzano la varianza minima come visto nella tabella di comparazione di figura 18 e 19 nella parte I di questa serie di articoli, ancor più se utilizzato con la matrice originaria che prevede l’utilizzo di 32 sistemi ad una distanza di circa 20 cm l’una dall’altra, tra l’altro cosa irrealizzabile a livello professionale per via delle dimensioni dei box diffusori stessi e le cui elevate interferenze per via degli ampi angoli orizzontali dei sistemi Array degraderebbero fortemente la risposta tonale del sistema.
Fino a quando non si riuscirà a creare un sistema 3D spaziale sulla base di un installazione Stereo, la soluzione migliore è quella di utilizzare il sistema WFS con il minimo numero di sistemi necessari (5) a distanze ottimizzate, per avere cosi la più bassa varianza minima possibile.
Il principio di analisi però non cambia, si parte da un limite dettato dall’algoritmo su cui si basa il processo di creazione e gestione dell’effetto spaziale, ad esempio da 5 sistemi in linea minimo per il WFS a salire.
Come si può intuire aggiungendo elementi distanziati la qualità finale della varianza minima e risposta in frequenza si ridurranno (soprattutto per la versione N Channel avendo elementi In Fill laterali e a soffitto), a vantaggio della percezione di un suono più realistico in termini di localizzazione e dimensione.
In entrambi i casi le sorgenti distanziate sono molteplici e anche se il segnale essendo 3D potrebbe non interessare contemporaneamente tutte le sorgenti insieme è da considerare sempre il caso peggiore, quindi l’ampiezza spaziale che interessa il maggior numero di sorgenti, e quindi ci mettiamo tutte le sorgenti.
Il numero di diffusori, distanza e posizionamento per una corretta percezione spaziale sono oggetto di continue ricerche e modifiche, per cui il fattore distanza è da sperimentare e da cui rilevare la possibile varianza minima in relazione al numero di sorgenti che devono essere contenute all’interno dello spazio di installazione. Come vedremo più avanti ci saranno poi in aiuto altri parametri di analisi legati maggiormente alla corretta percezione di un suono 3D.
Nel 3D sarà necessario mediare sulla varianza minima in relazione alla posizione della sorgente, in quanto la sua posizione sarà fondamentale per la corretta percezione tonale e di livello di un suono nello spazio, e questo come visto anche per il sistema L/R è degradante per il mantenimento di una bassa varianza minima, utilizzando un numero diverso di sorgenti rispetto a quello di taratura avremo un aumento della varianza minima come si vede dalla figura 4.
Fig. 4

Considerando i soli satelliti e lo stesso livello energetico, spostando la sorgente nello spazio tale da interessare un differente numero di sorgenti si nota un aumento della varianza minima, come in questo caso di esempio di figura 4 in comparazione di utilizzo di tutti e 5 i sistemi rispetto ad utilizzare sono i due laterali Left rispetto ai due laterali Right rispetto ai tre centrali. Variando poi il livello energetico varia ulteriormente la varianza minima. Con la presenza ulteriore dei Sub come già visto anche per il caso Left e Right verrà a meno la calibrazione effettiva del sistema spostando la varianza minima verso un aumento.
Satelliti
In contesto di progettazione pratica una volta trovata la distanza tra le sorgenti esterne che continuiamo a definire L ed R continuiamo ad aggiungere altri 3 sistemi in copia distribuiti sulla linea di asse simmetrica del P.A. con equa distanza (fig. 5).
Fig. 5

Analizzando la varianza minima complessiva e divisa per bande (fig. 6), si può notare che nell’insieme il sistema WFS offre una più bassa varianza minima rispetto allo stereo, ma analizzando attentamente il comportamento diviso in bande è prettamente dovuto ad un migliore accoppiamento in bassa frequenza, tanto è vero che medie ed alte sono a più alta varianza minima. L’abbassamento della varianza in bassa frequenza per il sistema WFS come detto anche per il caso a due sistemi Left e Right sarà poi un fattore chiave in fase di scelta frequenza di crossover con il sistema Sub.
Fig. 6


Variando numero elementi e distanza (fig. 7) all’aumentare del numero di elementi in base alla distanza tra essi varia il valore di varianza minima che per il caso di esempio (7 rispetto a 9) risulta più basso in media e più alto in bassa ed alta, nel complesso più bassa varianza per i 9, dettato maggiormente da un più ravvicinato centro asse in media frequenza (quindi una possibile valutazione da fare per la scelta del numero di elementi e per cui poi si dovrà settare il processore WFS). Se riprendiamo la configurazione con 5 elementi e quindi più distanziamento, abbiamo valori di varianza minima più bassi sia in meda che in alta frequenza a confermare che per sistemi distanziati meno elementi è meglio.
Fig. 7


Se distanzio gli elementi (es. 10 metri tra L ed R), in comparazione della versione a 5 elementi, il valore di varianza minima aumenta invece che calare come visto nella versione L/R (fino ad un punto per cui la troppa distanza porterà anche in questo caso ad un calo verso il valore di varianza minima del singolo elemento), e questo è ancora più chiaro per la versione WFS con L/R distanziato 15 metri (fig. 8). Il fenomeno inverso è dovuto alla presenza di più sorgenti distanziate in prossimità che guardando il comportamento del sistema L/R distanziato nella parte I di questa serie di articoli, nei primi metri ha il medesimo comportamento di innalzamento della varianza minima fino ad un punto in cui si inverte la direzione.
Fig. 8


In caso di configurazione 3D WFS è poi possibile sperimentare gli effetti di angolazione dei sistemi sulla varianza minima, ma in questo caso essendovi molti più sistemi distanziati in linea generale l’effetto è controproducente per via dei molteplici angoli acuti che si andrebbero a creare.
Inclinazione Satelliti
Anche in considerazione di un progetto 3D è importante calcolare il grado di inclinazione da dare ai satelliti per avere varianza minima, solo che in questo caso è da considerare anche l’inclinazione dei sistemi più centrali, ed essendo un ascolto di tipo immersivo, l’inclinazione porterà anche ad una variazione di sensibilità di posizione percepita da ottimizzare poi attraverso il Panning.
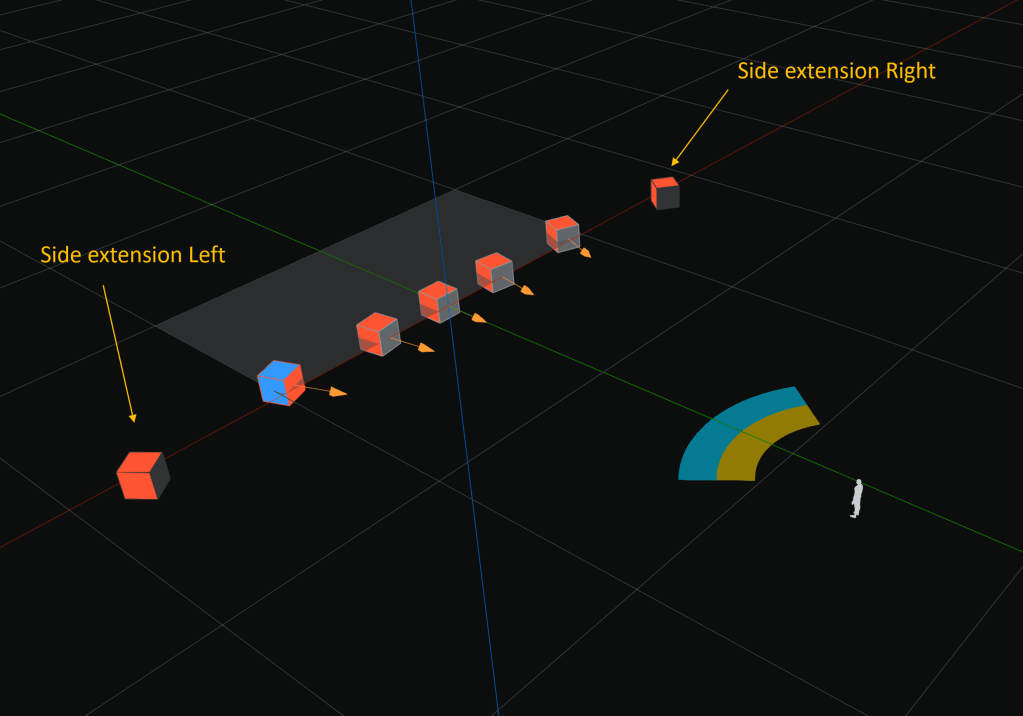
Alcune soluzioni possono inoltre prevedere estensioni oltre i 5 elementi di base definiti prima (fig. 9), per ottenere un immagine spaziale ancora più aperta e per ottimizzare l’ascolto immersivo per una più vasta area di ricettori sul piano orizzontale. In ogni caso sono elementi da considerare nella varianza minima, come distanza ed inclinazione, sono dei veri e propri In Fill.
Per l’inclinazione vale sempre la legge che verso il centro offre una varianza minima più bassa.
Fig. 9
Attraverso l’inclinazione è possibile quindi gestire il grado di estensione da dare alla percezione 3D, come risultato come prima accennato sarà da mediare la varianza minima con la percezione immersiva, e per quanto riguarda il grado di percezione sono in aiuto alcuni tools che vedremo più avanti.
Anche la stessa distanza determina un cambiamento a livello di percezione immersiva, ad esempio se i 3 sistemi centrali sono maggiormente ravvicinati rispetto al Left e Right invece che essere tutto equidistante ci sarà un incremento della percezione verso il centro, al contrario se maggiormente posizionati verso l’esterno. Ma questo dipende molto anche dal mix in base a dove si vuole dare più energia e presenza.
Configurazioni Miste
Si può pensare anche di creare un progetto a varianza minima Left e Right e poi utilizzare come elementi centrali un numero più ridotto di sistemi a favore di una varianza minima più bassa, questo però andrebbe a sbilanciare l’energia distribuita in fase di pannaggio 3D sfasando cosi la corretta percezione, quindi da valutare in base alle reali esigenze.
Sub
Che sia WFS o N Channel il setup di progettazione Sub non cambia, se si ha la possibilità per la versione N Channels è possibile sperimentare anche un cerchio di Sub a contornare e seguire il posizionamento dei Satelliti al fine di bilanciare a livello Broadband il posizionamento percepito della sorgente (“se il vento soffia da sinistra bisogna sentirlo da sinistra”).
A livello WFS invece mantenere sempre il contesto frontale che sarà poi processato a livello spaziale.
Per quanto riguarda l’applicazione di ritardi e livello, seguire sempre il metodo per cui il sistema che arriva prima sarà quello che subirà della base di ritardo per essere in fase e per cui le altre sorgenti saranno da offsettare di conseguenza.
In un sistema a configurazione multicanale come quello WFS è ancora più importante di quello L/R il mantenimento del rapporto e delle linee di via tra Sub e Satelliti (Sub L con Sat. L, Sub LC con Sat. LC, Sub R con Sat. R e cosi via).
Quindi ogni elemento satellite array avrà il suo numero di sub, ad esempio per un array di 4 elementi, che se per il WFS sono 5 sistemi avremo un totale di 20 satelliti e 20 sub divisi adeguatamente su vie separate ogni 4 Sub per ogni 4 Satelliti. Cosi facendo se ad esempio sposto la cassa da Batteria o Basso nello spazio, percepirò lo spostamento della Cassa o Basso nella sua tonalità Broadband con mantenimento del livello energetico, mentre se mantenessi i Sub in Mono come si vede in molte configurazione L/R, ci sarebbe un allungamento ed errore di localizzazione Broadband dello strumento con una deviazione della risposta tonale in bassa frequenza, la cui parte bassa o medio-bassa secondo la frequenza di taglio data, rimane ad un livello di percezione centrale ed a più alto livello. Problema presente anche nel solo L/R per questo tipo di configurazione con Sub Mono ma più ridotto per via di una percezione spaziale limitata al piano orizzontale e ad un ottimizzazione del livello su 2 vie (L/R), mentre nel caso WFS sarebbe ben più complesso e poco efficiente dovendo ottimizzare sulle variabili di livello di almeno 5 vie (L/R/C/LC/RC).
Per quanto riguarda la distribuzione delle vie, un po’ come per L/R i Sub più verso destra saranno nella via R quelli più verso sinistra nella via L, quelli più centrali nella via C, quelli più in mezzo a destra nella via RC, quelli più in mezzo a sinistra nella via LC e cosi via.
In questo caso il pannaggio è più estremo rispetto a quello L/R e quindi ha più valore l’aumento della varianza minima, il principio però rimane lo stesso, rimanere contenuti nell’intorno dei +/- 4 dB per gli strumenti che riproducono anche le basse frequenze.
Side, Front, Down Fill e Delay Tower
Per il caso N Channels se correttamente progettato non ci sarà bisogno di Out Fill e Delay Tower in quanto che le sorgenti sono già distribuite intorno ai ricettori e nel caso ve ne siano al di fuori del fuoco spaziale, questi potranno essere bilanciati con ulteriori sorgenti ma con una percezione spaziale più limitata, tendente al mono. I Front Fill e Down Fill continueranno invece ad essere utili per bilanciare i ricettori di più prossimità, anche se in un sistema multicanale progettato a varianza minima avendo anche la presenza di elementi array nella posiziona frontale, se i ricettori non sono troppo ravvicinati al palco ed è possibile installare un adeguata lunghezza dell’array come da progetto, non sarà necessaria la presenza di Front Fill e Down Fill.
Per il caso WFS anche qui dipende molto da quanti elementi si riesce ad installare in base alle dimensioni dell’array, peso sopportabile dalla struttura, limiti di installazione, dimensioni e forma del palco, ecc.., in quanto che per grandi sistemi è facile che i centrali possano risultare invadenti e coprire la corretta visione centrale del palco, musicisti, scenografia.
Di fatti al momento è un tipo di configurazione che risulta limitata in base alla pressione sonora massima e conseguente varianza minima accettabile che si riesce a dare, limitati dal numero di elementi installabili.
Oltre a questo il limite di utilizzo direttamente correlato al precedente è dato dalla dimensione dell’area da sonorizzare, l’effetto spaziale è percepibile correttamente solo all’interno di una determinata area, quell’area che rimane sotto il fuoco dei +/- 6 dB del sistema Main fronte palco, i 5 elementi array.
Chi si troverà nel fuoco delle linee di riempimento Out Fill e Delay Tower avrà un attenuazione progressiva della percezione spaziale che diventerà sempre più Monofonica e centrata verso l’asse del sistema di riproduzione interessato, e questo è tanto maggiore tanto più si esce dal fuoco dei +/- 6 dB del sistema Main. Come per il caso N Channel una corretta installazione dell’array, grazie alla presenza di sistemi centrali può facilmente coprire anche i ricettori di prossimità di tutto il piano orizzontale senza la necessità di Front e Down Fill a favore di una più corretta percezione spaziale ed un abbassamento della varianza minima.
Per quanto riguarda le linee di compensazione Front Fill e Downfill questi sono esclusivamente un estensione del Main atti a bilanciare il livello di prossimità e quindi se correttamente bilanciati hanno un potenziale di deviazione di localizzazione molto basso.
Come linee di collegamento si segue quello di installazione del sistema Main, quindi Side L avrà una copia del Main L, Side R una copia del sistema Main R, Front Fill C una copia del sistema Main centrale, Front Fill LC una copia del sistema Main LC, Front Fill RC una copia del sistema Main RC. La loro presenza e quantità va sempre considerata da progetto, è facile ad esempio che possa essere necessaria solo la parte Front Fill C e non quella L, R, LC, RC.
Per quanto riguarda il Delay Tower questi sono sistemi di riempimento e quindi non hanno un riferimento spaziale in linea con il sistema Main, ma come visto vanno a “tappare” i buchi presenti nell’area da sonorizzare ed il loro riferimento è la linea che vanno a coprire, quindi se Left avranno la linea Left, se Right Right, se centrale Centro, ecc…
In caso di limitazioni sulle dimensioni dell’array centrale, si potrebbe pensare anche di creare un ibrido con L-R di adeguate dimensioni come da progetto e poi in misura più limitata o stessa misura ma divisa in due colonne ravvicinate i sistemi centrali, ma questo verrebbe a scapito della corretta percezione spaziale, perdendo energia e deviazione di percezione spaziale per le sorgenti con posizione che interessa sia il sistema centrale che quello laterale (ci deve essere un equa distribuzione energetica su tutti e 5 gli elementi array).
Note di Progettazione
Software come EASE fornisce alcuni tool per la verifica di un corretto montaggio e calibrazione di un sistema per ascolto immersivo, ad esempio il parametro Loudspeaker Coverage con diagramma polare invertito garantisce una visione migliore della distribuzione dell’energia SPL nello spazio, che anche per il caso 3D deve essere più omogenea possibile per avere una minore distorsione di localizzazione possibile (fig. 10)
Fig. 10

Un altro elemento importante è la distorsione di deviazione della localizzazione, e questa è calcolata attraverso il grafico di analisi della localizzazione spaziale (fig. 11).
Fig. 11
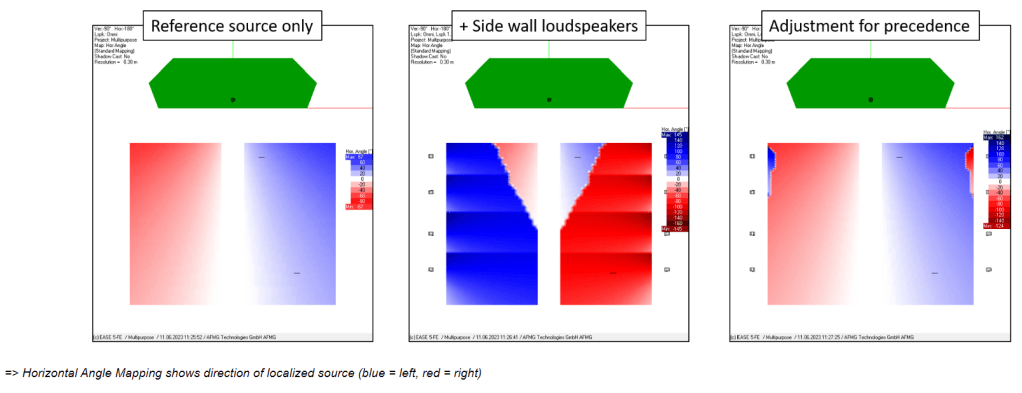
Questo parametro dice quanta deviazione di percezione c’è, e questa deviazione è causata dall’elevato numero di sorgenti distanziate con quindi differenti tempi di arrivo ad ogni ricettore in differenti posizioni di ascolto. Attraverso la regolazione del tempo di ritardo e livello delle sorgenti, si deve consentire di percepire un suono più possibile centrale indipendentemente dalla posizione degli altoparlanti. Questo consentirà di avere una più bassa distorsione di localizzazione.
FIR Maker
Alcuni software presentano la possibilità di calcolare in modo automatico non solo la corretta distribuzione (angolazione tra gli elementi) dell’array come visto negli articoli precedenti ma anche il calcolo automatico dello Steering.
Utilizzando filtri FIR è possibile definire il piu delle volte manualmente ma in certi casi come in EASE Focus anche automaticamente, la corretta impostazione dei parametri di Livello, Fase, Eq. per ottenere la risposta in frequenza, livello spl, copertura omogenea desiderata.
Il sistema automatico è in grado di generare un impostazione ottimale in pochi secondi, utile quando i lunghi e costosi tempi di progetto non sono una strada percorribile, o per chi non è esperto nel Sound Design o per semplice comparazione rispetto ad una progettazione manuale senza utilizzo di FIR Marker.
Una volta definito o calcolato i migliori parametri, questi potranno essere esportati come file e caricati all’interno del DSP integrato nei diffusori amplificati o nei processori esterni cosi da avere già il sistema ottimizzato. In alcuni casi è possibile anche integrare il DSP del processore o diffusore con il software di generazione Filtro FIR (come ad esempio EASE Focus con i processori della Lake), ed inviargli direttamente il filtro senza doverlo salvare su file per poi salvarlo su chiavetta o collegarlo tramite usb e caricarlo nuovamente. Quindi un processo piu rapido ed immediato.
A livello di progettazione in EASE Focus, si necessità quindi di un diffusore con sistema DSP che può gestire/importare filtri FIR di terze parti. Alcuni produttori generano i propri filtri FIR e li integrano nei loro diffusori e questi non sono modificabili, non possono essere generati ed importati altri, e le uniche opzioni sono quelle di controllo di preset che forniscono eventualmente angoli di copertura differenti, prestazioni SPL ed Eq. differenti.
Questo diffusore è da caricare all’interno del progetto o se è un DSP esterno si necessità che questo sia collegato e riconosciuto dall’applicazione.
Fig. 12
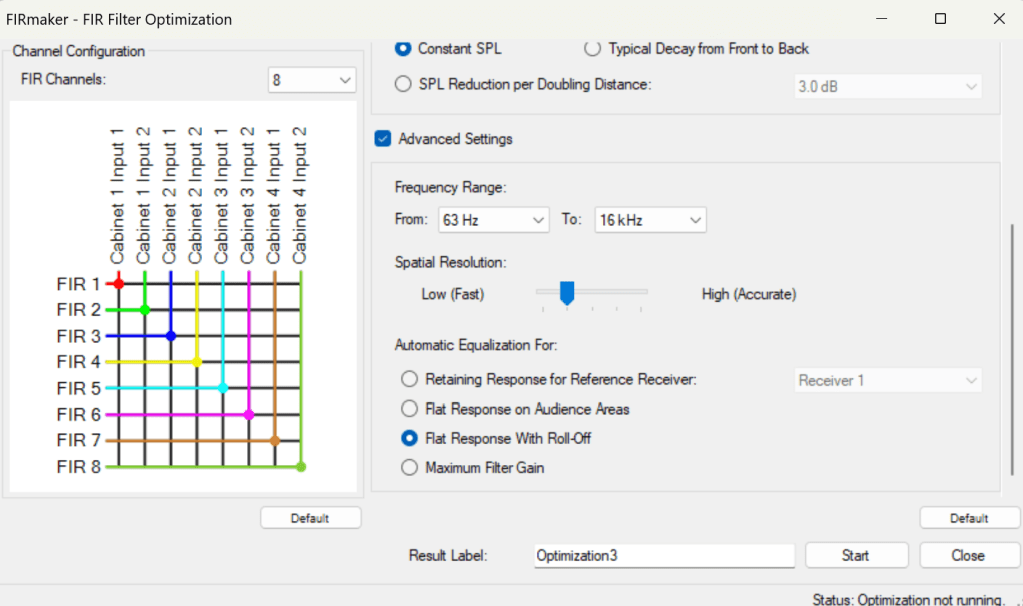
Una volta caricato il diffusore o DSP con la possibilità di gestire il FIR sarà possibile cliccare su Compute FIR Preset…(fig. 12) che abiliterà la finestra di editing del filtro FIR (fig. 13).
Fig. 13

Come si vede in figura 13 nella finestra che appare ci saranno le impostazioni su cui è possibile agire. Nella parte di destra sarà possibile decidere su quali filtri andare a lavorare e questo è limitato al numero di filtri presenti nel DSP del diffusore o processore. In questo caso ogni singolo elemento diffusore ha 2 filtri FIR uno per l’ingresso 1 ed uno per l’ingresso 2. Se avessimo 4 sistemi potremmo agire su 8 filtri FIR indipendenti (fig. 14). Possiamo agire su quelli che vogliamo dalla selezione FIR Channel, ogni modifica ad un filtro FIR darà una risposta ed un comportamento diverso del diffusore che è possibile vedere tramite la risposta SPL, frequenza e Mapping in EASE FOCUS.
Fig. 14

Nella parte di destra è invece possibile scegliere che tipo di ottimizzazione automatica dare al filtro.
Quindi in questo caso deve essere ottimizzata l’Audience Area. Poi è possibile scegliere la priorità di settaggio, quali mantenere alta la potenza, una distribuzione bilanciata, alta uniformità del livello SPL nello spazio, ecc…, infine è possibile scegliere il tipo di decadimento del livello SPL, se costante oppure dare soluzioni di maggiore attenuazione ad esempio per ridurre l’impatto sonoro su superfici riflettenti.
Una volta definito il tutto si clicca sul pulsante Start ed il sistema esegue il calcolo automatico del migliore settaggio, lavorando sulle impostazioni dei filtri selezionati che vanno a controllare tempo, fase, livello e risposta di ogni diffusore.
A fine processo sarà possibile valutare la copertura del sistema senza modifica al FIR (fig. 15) e con modifica (fig. 16).
Fig. 15


Fig. 16


Come si vede dalla comparazione del due soluzioni l’applicazione del filtro ha migliorato l’omogeneità di copertura di livello (e questo in pochi secondi di calcolo).
Cliccando su Advanced Setting nelle impostazioni del FIR sarà possibile definire ulteriori parametri (fig. 17), quali il range di frequenze di ottimizzazione, la precisione del filtro (piu è alto e piu impieghera tempo), il valore di equalizzazione automatica per essere la più lineare possibile nei vari punti dell’area o ad un ricevitore specifico, o ancora per ottenere il massimo valore di guadagno possibile con una coerente risposta in frequenza.
Fig. 17
Una volta comparato vare soluzioni sarà possibile cliccando sul pulsante Export FIR File esportare la soluzione selezionata come file pronto da essere importato all’interno del DSP (fig. 18).
Fig. 18
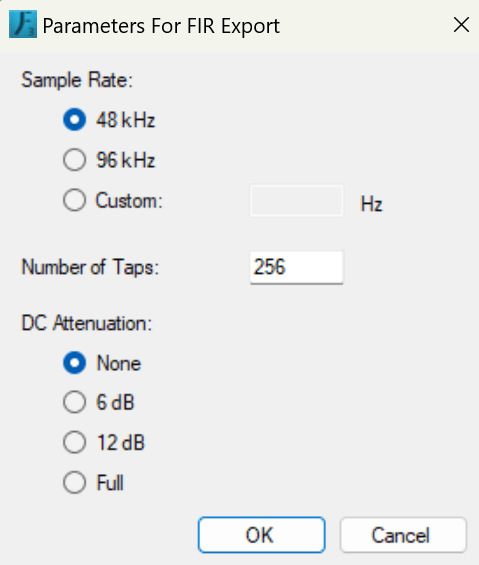
Come parametri di esportazione (fig. 19), sarà necessario scegliere la frequenza di campionamento di lavoro del DSP (altrimenti non sarà leggibile), e cosa importante è il numero di Taps, più è alto il valore e più il filtro sarà preciso e rispecchierà le impostazioni di progetto che danno quel risultato ma a scapito di una più alta latenza, al contrario Taps piu bassi avranno un filtro meno preciso ma piu veloce. Per questo è bene conoscere i massimi e minimi livelli di Taps che il filtro del DSP può leggere per non incombere in errori. C’è anche da fare una valutazione sulla precisione dei filtri FIR che con bassi valori di Taps tendono ad essere meno precisi sulle basse frequenze, e l’accuratezza e limiti del processamento sono comunque dati dal tipo di processore e diffusore oltre che ambiente in cui verrà riprodotto il suono.
Fig. 19
Il valore di attenuazione DC (simile alla correzione del DC Offset nei programmi di Mastering per ridurre l’offset di registrazione indotto da un mal funzionamento della corrente o del registratore stesso), influisce sui valori di attenuazione artificiale in bassa frequenza e piu il Taps ha bassi valori e maggiore attenuazione servirà in quanto che si possono creare artefatti nel processo di lettura del Filtro dal DSP.
Cliccando invece su Transfer FIR Filter sarà possibile trasferire il filtro direttamente al software del DSP e questo deve essere connesso allo stesso PC in cui è utilizzato EASE e lo si deve vedere all’interno del software del DSP stesso. In questo caso sarà richiesto solo il livello di DC Attenuation in quanto che il software gestirà in modo automatico l’ottimizzazione del Taps e della frequenza di campionamento.
Fig. 20

Considerazioni
Il FIR Maker è un assistente per velocizzare il processo di ottimizzazione. Ma questo non si sostituisce al lavoro del System Designer, in quanto che per funzionare ha bisogno di dati e si basa sulla posizione di partenza del sistema, quindi se lasciamo l’array tutto a 0 gradi, troppo in alto, troppo in basso, ecc..darà risultati differenti e faticherà a dare quella che potrebbe essere la migliore soluzione in generale, ma solo la migliore soluzione per quella configurazione dell’array.
Rimane quindi il fatto di utilizzare il metodo per trovare la varianza minima cosi da avere la distribuzione ottimale del sistema, per poi provare con il FIR Maker a valutare se si riesce ad ottenere un livello superiore di precisione.
In allegato una tabella Excel come linea guida di inserimento dati:
Altro su System Designer – Line Array
System Designer – Line Array – Part – I (Array di satelliti, Processo e Considerazioni)
System Designer – Line Array – Part – II (Sub Woofer, Ottimizzazione Fase, Scelta Frequenza di Crossover)
System Designer – Line Array – Part – III (Out Fill, Front e Down Fill, Delay Tower, Concetti Psicoacustici)
Acquista Attrezzature Audio dai principali Store


