
 Consiste nel far analizzare parti di audio/rumore ( se possibile solo rumore ) al plugin, al fine di identificare la risposta in frequenza del rumore cosi da impostare una linea di processamento ( risposta in frequenza ) che tramite threshold va poi ad attenuare il livello desiderato con quel tipo di andamento ( fig. 2 ).
Fig. 2
Consiste nel far analizzare parti di audio/rumore ( se possibile solo rumore ) al plugin, al fine di identificare la risposta in frequenza del rumore cosi da impostare una linea di processamento ( risposta in frequenza ) che tramite threshold va poi ad attenuare il livello desiderato con quel tipo di andamento ( fig. 2 ).
Fig. 2  In figura 2 si nota la linea rossa che rappresenta lo spettro tonale del segnale audio ( rumore ) in ingresso al processore, linea bianca che rappresenta lo spettro memorizzato all’interno del plugin ( fingerprint ), linea verde che rappresenta invece lo spettro tonale del segnale audio dopo il processamento. Attraverso un controllo threshold sarà possibile alzare o abbassare la risposta fingerprint in relazione al livello del segnale audio in ingresso ( linea verde ), e attraverso un controllo di riduzione del rumore sarà possibile dire al plugin quanto questa risposta fingerprint dovrà agire in fase di processamento sul segnale audio di ingresso, cosi da produrre in uscita un segnale audio processato ( linea rossa ).
Avendo un controllo di attenuazione sul rumore con stesso spettro ( quello che si decide di memorizzare sul plugin ), il risultato in molti casi è garantito al 100%, mentre se si utilizza uno spettro di riduzione lineare ( es. linea bianca in figura 1, che identifica uno spettro non ancora memorizzato ), è molto probabile che tutto il rumore che supera tale soglia non venga correttamente attenuato ( fig. 3 – 4 ).
Fig. 3
In figura 2 si nota la linea rossa che rappresenta lo spettro tonale del segnale audio ( rumore ) in ingresso al processore, linea bianca che rappresenta lo spettro memorizzato all’interno del plugin ( fingerprint ), linea verde che rappresenta invece lo spettro tonale del segnale audio dopo il processamento. Attraverso un controllo threshold sarà possibile alzare o abbassare la risposta fingerprint in relazione al livello del segnale audio in ingresso ( linea verde ), e attraverso un controllo di riduzione del rumore sarà possibile dire al plugin quanto questa risposta fingerprint dovrà agire in fase di processamento sul segnale audio di ingresso, cosi da produrre in uscita un segnale audio processato ( linea rossa ).
Avendo un controllo di attenuazione sul rumore con stesso spettro ( quello che si decide di memorizzare sul plugin ), il risultato in molti casi è garantito al 100%, mentre se si utilizza uno spettro di riduzione lineare ( es. linea bianca in figura 1, che identifica uno spettro non ancora memorizzato ), è molto probabile che tutto il rumore che supera tale soglia non venga correttamente attenuato ( fig. 3 – 4 ).
Fig. 3  In figura 3 un esempio di scarsa efficienza per sistemi No Fingeprint.
Fig. 4
In figura 3 un esempio di scarsa efficienza per sistemi No Fingeprint.
Fig. 4  In figura 4 un esempio di efficienza per sistemi Fingerprint, è chiaro come lo spettro di rumore ( linea rossa ) sia maggiormente e più finemente attenuato con la tecnica Fingerprint.
L’effettiva potenzialità del sistema Fingerprint è ottenibile se si fa analizzare un campione di audio con molto rumore ( meglio registrare qualche secondo di rumore a parte “rumore presente nel file audio” ed analizzare quello, per poi determinare l’impronta spettrale ( e da qui fingerprint ) nel plugin, altrimenti si rischia solo di far prelevare una risposta in frequenza con una grande presenza di audio pulito, ed il plugin producendo una linea di intervento con andamento spettrale più di audio che di rumore, lavorerà troppo pesantemente in attenuazione più sulla parte audio che rumore, in quel caso meglio No Fingerprint, quindi un qualunque altro sistema di riduzione del rumore.
Oltre ai parametri di gestione Threshold e Reduction come nei plugin appena analizzati, abbiamo sempre il Difference per il pre-ascolto del segnale processato, livello del segnale di uscita post-processamento, alcuni parametri Dynamics nella gestione dell’attacco e del rilascio per gestire interventi di processamento più morbidi o più decisi ed immediati. Abbiamo un semplice circuito di equalizzazione ( generalmente High Shelving, concentrato quindi in medio alta ed alta frequenza ), per definire un intervento manuale di riduzione del rumore ( fig. 5 ), ( può essere usato a volte non solo in attenuazione ma anche in amplificazione, in modo da risaltare eventuali parti di spettro perse, una sorta di noise reduction inverso o un equalizzatore vero e proprio ).
Fig. 5
In figura 4 un esempio di efficienza per sistemi Fingerprint, è chiaro come lo spettro di rumore ( linea rossa ) sia maggiormente e più finemente attenuato con la tecnica Fingerprint.
L’effettiva potenzialità del sistema Fingerprint è ottenibile se si fa analizzare un campione di audio con molto rumore ( meglio registrare qualche secondo di rumore a parte “rumore presente nel file audio” ed analizzare quello, per poi determinare l’impronta spettrale ( e da qui fingerprint ) nel plugin, altrimenti si rischia solo di far prelevare una risposta in frequenza con una grande presenza di audio pulito, ed il plugin producendo una linea di intervento con andamento spettrale più di audio che di rumore, lavorerà troppo pesantemente in attenuazione più sulla parte audio che rumore, in quel caso meglio No Fingerprint, quindi un qualunque altro sistema di riduzione del rumore.
Oltre ai parametri di gestione Threshold e Reduction come nei plugin appena analizzati, abbiamo sempre il Difference per il pre-ascolto del segnale processato, livello del segnale di uscita post-processamento, alcuni parametri Dynamics nella gestione dell’attacco e del rilascio per gestire interventi di processamento più morbidi o più decisi ed immediati. Abbiamo un semplice circuito di equalizzazione ( generalmente High Shelving, concentrato quindi in medio alta ed alta frequenza ), per definire un intervento manuale di riduzione del rumore ( fig. 5 ), ( può essere usato a volte non solo in attenuazione ma anche in amplificazione, in modo da risaltare eventuali parti di spettro perse, una sorta di noise reduction inverso o un equalizzatore vero e proprio ).
Fig. 5 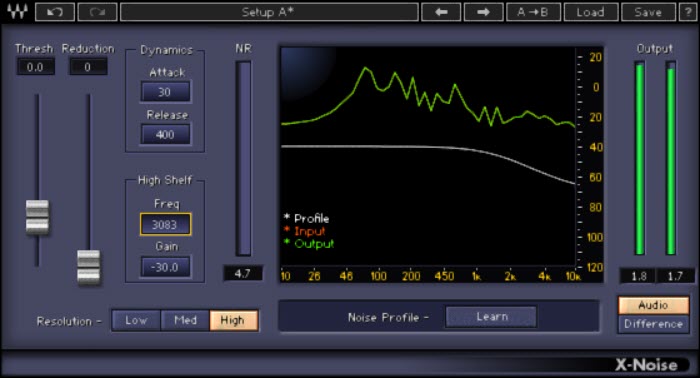 Questa equalizzazione può interagire in modo indipendente o insieme alla Fingerprint ( fig. 6 ).
Fig. 6 ( 1 solo Fingerprint, 2 Fingerprint + equalizzazione ).
Questa equalizzazione può interagire in modo indipendente o insieme alla Fingerprint ( fig. 6 ).
Fig. 6 ( 1 solo Fingerprint, 2 Fingerprint + equalizzazione ).
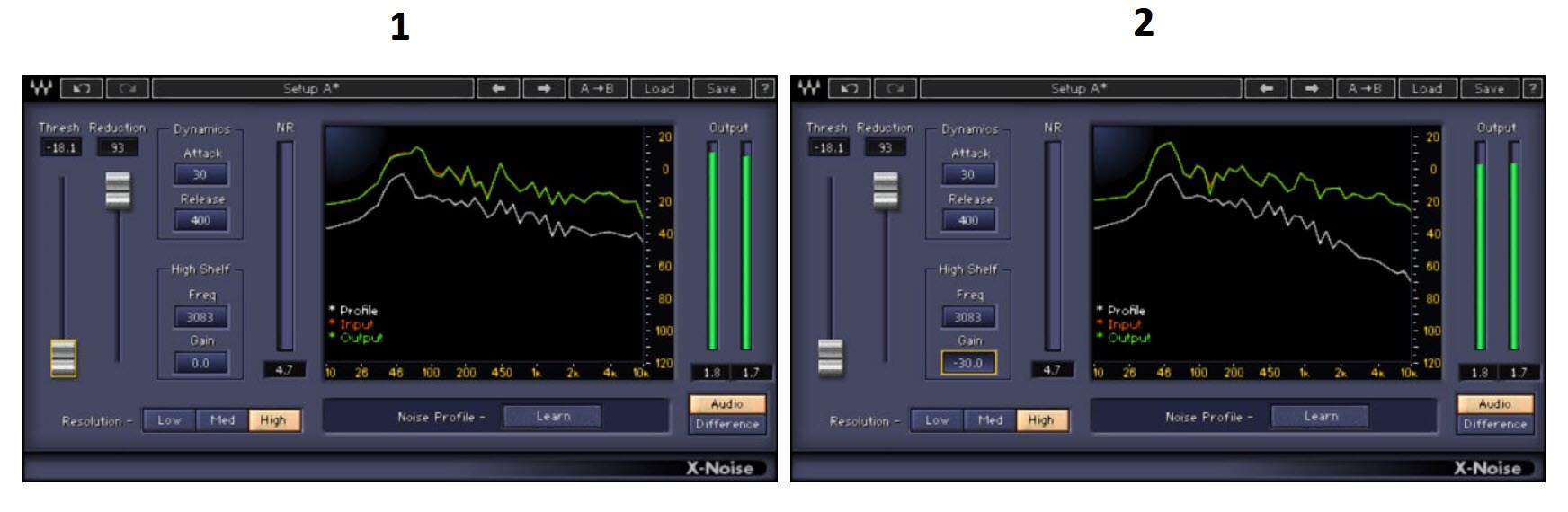 Come si nota il grafico di visualizzazione è sempre in dominio frequenza/ampiezza in quanto la sua principale funzione è quella di monitorare l’andamento energetico spettrale del rumore.
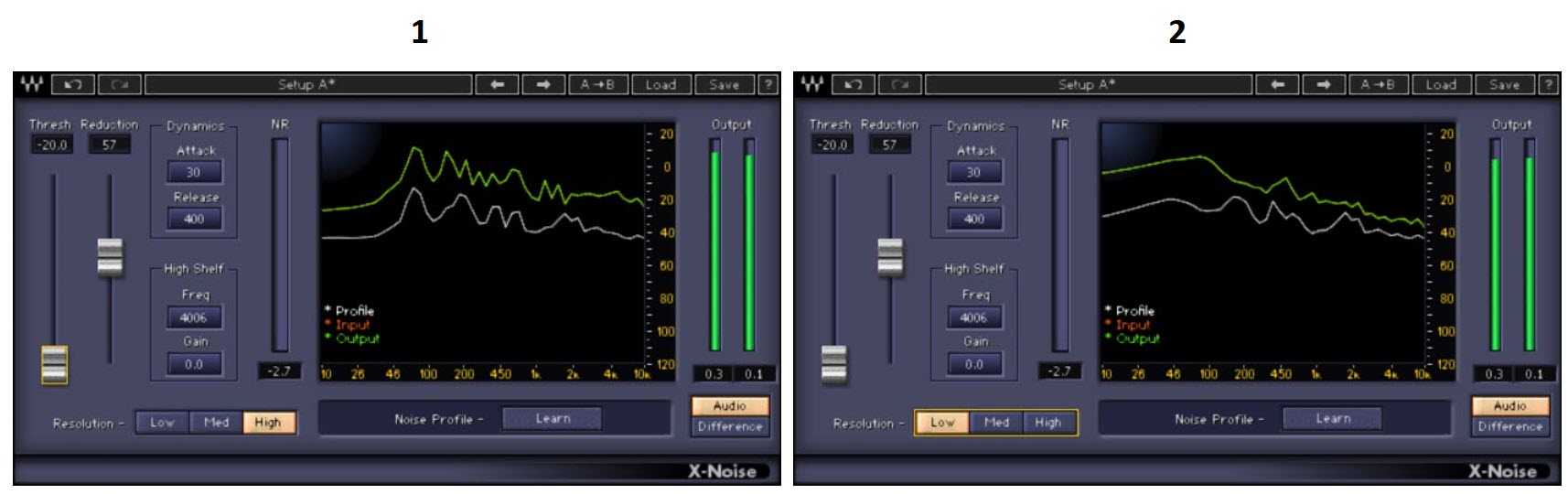
Vi è anche la possibilità di scegliere il grado di precisione per la fase di processamento ( rilevante soprattutto quando il plugin è utilizzato con Fingerprint attivo ), ( Resolution ), utilizzare sempre il massimo, calare solo in caso che il proprio computer non abbia un processore abbastanza prestante e che induca a fenomeni di distorsioni e scatti sul segnale audio in riproduzione ( fig. 7 ).
Fig. 7 ( 1 alta precisione, 2 bassa precisione ).
Come si nota il grafico di visualizzazione è sempre in dominio frequenza/ampiezza in quanto la sua principale funzione è quella di monitorare l’andamento energetico spettrale del rumore.
Vi è anche la possibilità di scegliere il grado di precisione per la fase di processamento ( rilevante soprattutto quando il plugin è utilizzato con Fingerprint attivo ), ( Resolution ), utilizzare sempre il massimo, calare solo in caso che il proprio computer non abbia un processore abbastanza prestante e che induca a fenomeni di distorsioni e scatti sul segnale audio in riproduzione ( fig. 7 ).
Fig. 7 ( 1 alta precisione, 2 bassa precisione ).
 Cliccando Learn è possibile far analizzare lo spettro audio al plugin e cliccandolo nuovamente impostarlo così da determinare l’impronta ( Fingerprint ) dello spettro di rumore da ridurre ( fig. 8 ). E’ un processo ripetibile quante volte lo si vuole, cosi da poter eventualmente gestire differenti spettri per differenti rumori all’interno ad esempio di una stessa traccia, un plugin può generalmente gestire un solo Fingerprint, per più di uno simultaneo ( ad esempio per differenti spettri da sentire in tempo reale ) è necessario utilizzare ulteriori plugin De Noiser Fingerprint.
Fig. 8
Cliccando Learn è possibile far analizzare lo spettro audio al plugin e cliccandolo nuovamente impostarlo così da determinare l’impronta ( Fingerprint ) dello spettro di rumore da ridurre ( fig. 8 ). E’ un processo ripetibile quante volte lo si vuole, cosi da poter eventualmente gestire differenti spettri per differenti rumori all’interno ad esempio di una stessa traccia, un plugin può generalmente gestire un solo Fingerprint, per più di uno simultaneo ( ad esempio per differenti spettri da sentire in tempo reale ) è necessario utilizzare ulteriori plugin De Noiser Fingerprint.
Fig. 8 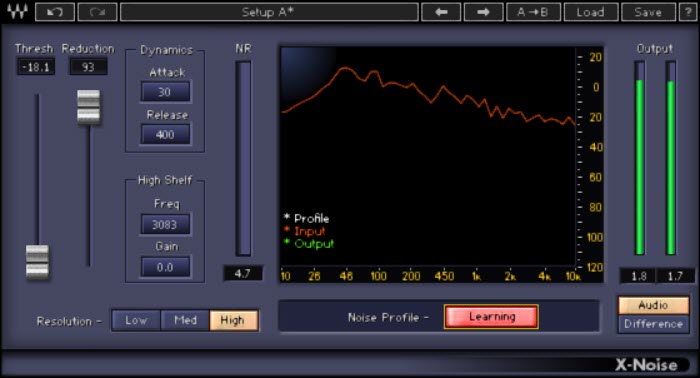 Il tutto per determinare il giusto contributo del processamento con la minore alterazione possibile dello spettro audio utile.
Ogni versione può presentare comunque parametri differenti con più o meno opzioni, come il plugin in figura 9 in cui è possibile agire con un circuito di equalizzazione a più bande e più finemente attraverso il controllo della campanatura Q ( equalizzatore peaking ). E’ possibile agire con maggiori parametri dinamici, come il Knee che identifica il grado di intervento del processamento ( più morbido o più immediato ), molto simile a quello di intervento dei processori compressori che vedremo in altre argomentazioni.
Fig. 9
Il tutto per determinare il giusto contributo del processamento con la minore alterazione possibile dello spettro audio utile.
Ogni versione può presentare comunque parametri differenti con più o meno opzioni, come il plugin in figura 9 in cui è possibile agire con un circuito di equalizzazione a più bande e più finemente attraverso il controllo della campanatura Q ( equalizzatore peaking ). E’ possibile agire con maggiori parametri dinamici, come il Knee che identifica il grado di intervento del processamento ( più morbido o più immediato ), molto simile a quello di intervento dei processori compressori che vedremo in altre argomentazioni.
Fig. 9 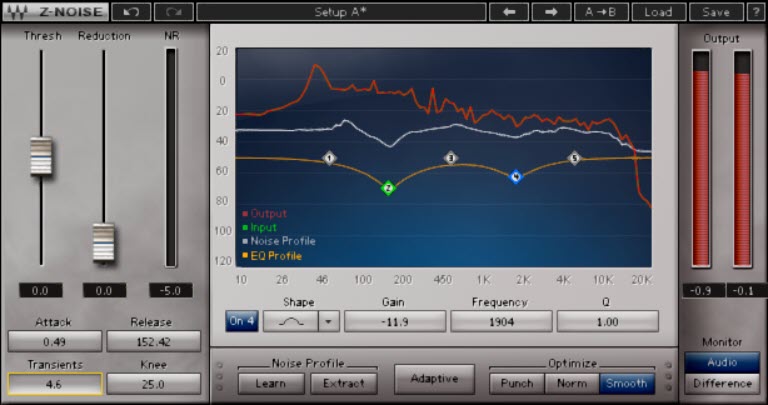 Ci sono anche parametri come il Transient con il quale è possibile ridurre l’enhanced ( aumento improvviso ) di determinate frequenze, dovuto al processo di riduzione del rumore ( come vedremo più in dettaglio quando parleremo di psicoacustica e mascheramenti, un attenuazione eccessiva delle alte frequenze può portare ad una percezione maggiore del contributo energetico in bassa frequenza e viceversa ), questo parametro consente appunto di ottimizzare la percezione psicologica di incremento energetico in determinate frequenze, lavorando sull’attacco del segnale audio post-processato.
Insieme al Learn per il rilevo dell’impronta ( Fingerprint ) dello spettro audio, può esserci anche Extract che ha una funzione molto simile al quella del Learn solo che il Learn è un algoritmo più efficiente sul rilievo esclusivo di parti di rumore, mentre Extract è un algoritmo in grado di estrarre la forma d’onda del rumore da parti audio pulite ( necessita comunque di avere una traccia audio con un buon contributo di rumore, e tanto più alto è e tanto più finemente agirà ).
Sia la modalità Learn che Extract una volta improntate rimangono stabili nel tempo, per cui sono particolarmente efficienti se il rumore non cambia la sua forma d’onda e il suo contributo energetico.
Un’ulteriore funzione ritrovabile è quella Adaptive in cui partendo dalla forma d’onda improntata ( Fingerprint ) tramite Learn o Extract, il processamento si adatta e monitora costantemente il rumore cosi da adattare il processamento alle variazioni di spettro ed intensità del rumore potendo agire ulteriormente più efficacemente sul rumore senza intaccare l’audio pulito.
Il parametro Optimize che si vede in figura 10 è l’equivalente del Resolution di figura 7 in cui è possibile gestire come detto la risoluzione di processamento. In questo caso però l’algoritmo lavora sul rapporto tra la risoluzione di processamento nel dominio del tempo e risoluzione di processamento nel dominio della frequenza. Se impostato su Smooth si avrà la massima risoluzione di processamento nel dominio della frequenza, questo causa una maggiore e più precisa riduzione del rumore ma a scapito di un impoverimento dell’attacco in caso ci siano parti audio pulite processate ( non adatto quindi a strumenti percussivi ). Se Punch invece si ha il contrario, e cioè l’ottimizzazione delle prestazioni nel dominio del tempo, quindi meno risoluzione di processamento ma con un’ottimizzazione dell’attacco e quindi più adatto in caso che l’audio presenti suoni percussivi ( come anche quello del pianoforte ). Norm è una via di mezzo come compromesso tra Smooth e Punch.
Fig. 10
Ci sono anche parametri come il Transient con il quale è possibile ridurre l’enhanced ( aumento improvviso ) di determinate frequenze, dovuto al processo di riduzione del rumore ( come vedremo più in dettaglio quando parleremo di psicoacustica e mascheramenti, un attenuazione eccessiva delle alte frequenze può portare ad una percezione maggiore del contributo energetico in bassa frequenza e viceversa ), questo parametro consente appunto di ottimizzare la percezione psicologica di incremento energetico in determinate frequenze, lavorando sull’attacco del segnale audio post-processato.
Insieme al Learn per il rilevo dell’impronta ( Fingerprint ) dello spettro audio, può esserci anche Extract che ha una funzione molto simile al quella del Learn solo che il Learn è un algoritmo più efficiente sul rilievo esclusivo di parti di rumore, mentre Extract è un algoritmo in grado di estrarre la forma d’onda del rumore da parti audio pulite ( necessita comunque di avere una traccia audio con un buon contributo di rumore, e tanto più alto è e tanto più finemente agirà ).
Sia la modalità Learn che Extract una volta improntate rimangono stabili nel tempo, per cui sono particolarmente efficienti se il rumore non cambia la sua forma d’onda e il suo contributo energetico.
Un’ulteriore funzione ritrovabile è quella Adaptive in cui partendo dalla forma d’onda improntata ( Fingerprint ) tramite Learn o Extract, il processamento si adatta e monitora costantemente il rumore cosi da adattare il processamento alle variazioni di spettro ed intensità del rumore potendo agire ulteriormente più efficacemente sul rumore senza intaccare l’audio pulito.
Il parametro Optimize che si vede in figura 10 è l’equivalente del Resolution di figura 7 in cui è possibile gestire come detto la risoluzione di processamento. In questo caso però l’algoritmo lavora sul rapporto tra la risoluzione di processamento nel dominio del tempo e risoluzione di processamento nel dominio della frequenza. Se impostato su Smooth si avrà la massima risoluzione di processamento nel dominio della frequenza, questo causa una maggiore e più precisa riduzione del rumore ma a scapito di un impoverimento dell’attacco in caso ci siano parti audio pulite processate ( non adatto quindi a strumenti percussivi ). Se Punch invece si ha il contrario, e cioè l’ottimizzazione delle prestazioni nel dominio del tempo, quindi meno risoluzione di processamento ma con un’ottimizzazione dell’attacco e quindi più adatto in caso che l’audio presenti suoni percussivi ( come anche quello del pianoforte ). Norm è una via di mezzo come compromesso tra Smooth e Punch.
Fig. 10 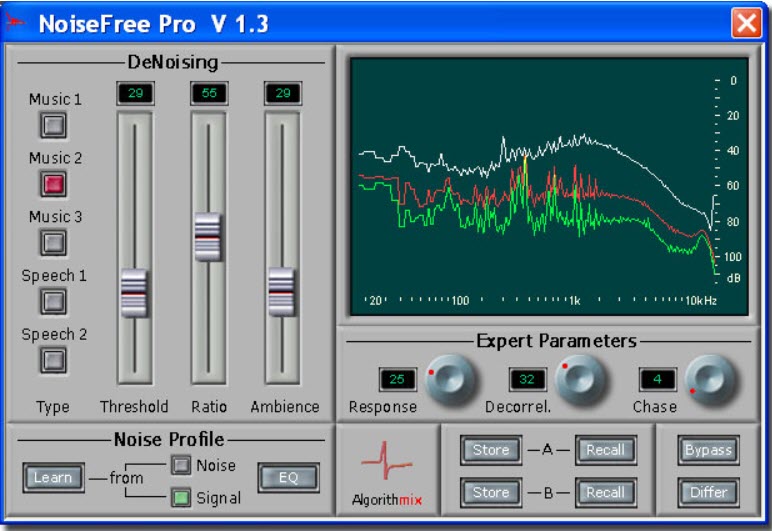 In figura 10 un Denoiser Fingerprint simile ai precedenti con suoi specifici parametri di settaggio come anche il controllo Ambience per la riduzione di riverbero e rumore ambientale. Diversi parametri di riduzione rumore pre-impostati come la riduzione del rumore nel parlato ( esempio registrazioni di telefonate, narrazioni, ecc.. ), ma anche riduzione del rumore presente in tracce audio musicali. Parametro Differ per la comparazione segnale processato e segnale non processato ( diversi parametri posso avere stesse funzioni di altri plugin ma con diversi nomi ).
Alcuni presentano anche una sezione di equalizzazione grafica per agire più finemente su di un particolare range di frequenze, processamento che può lavorare anche in questo caso insieme al Fingerprint ( fig. 11 ).
Fig. 11
In figura 10 un Denoiser Fingerprint simile ai precedenti con suoi specifici parametri di settaggio come anche il controllo Ambience per la riduzione di riverbero e rumore ambientale. Diversi parametri di riduzione rumore pre-impostati come la riduzione del rumore nel parlato ( esempio registrazioni di telefonate, narrazioni, ecc.. ), ma anche riduzione del rumore presente in tracce audio musicali. Parametro Differ per la comparazione segnale processato e segnale non processato ( diversi parametri posso avere stesse funzioni di altri plugin ma con diversi nomi ).
Alcuni presentano anche una sezione di equalizzazione grafica per agire più finemente su di un particolare range di frequenze, processamento che può lavorare anche in questo caso insieme al Fingerprint ( fig. 11 ).
Fig. 11 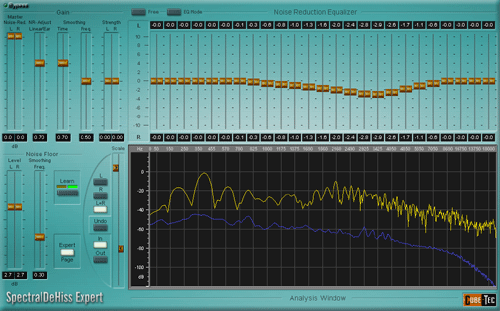 Anche plugin per la riduzione di rumori impulsivi ed occasionali possono avere tecnologia Fingerprint come quello in figura 12, anche se ripeto essere più efficiente per rumori continui e stazionari, mentre per rumori occasionali un costante processamento quando non necessario anche se rimane sotto una determinata soglia porta sempre anche se piccole colorazioni del segnale audio utile.
Fig. 12
Anche plugin per la riduzione di rumori impulsivi ed occasionali possono avere tecnologia Fingerprint come quello in figura 12, anche se ripeto essere più efficiente per rumori continui e stazionari, mentre per rumori occasionali un costante processamento quando non necessario anche se rimane sotto una determinata soglia porta sempre anche se piccole colorazioni del segnale audio utile.
Fig. 12 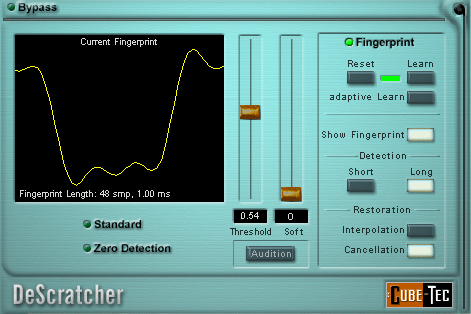 In figura 12 si nota un plugin per la riduzione di rumori impulsivi con la possibilità di utilizzare la tecnologia Fingerprint attraverso i processi di Learn ed Adaptive Learn come visto prima. Presenta anche la gestione della tipologia di rilevamento e correzione, quindi tramite interpolazione oppure semplice rimozione. Visualizzazione monitorata al campione con riferimento temporale.
De-Noiser No Fingerprint
In un contesto generale qualsiasi plugin di Noise Reduction che non preveda tecnica Fingerprint è No Fingerprint.
I plugin De-Noiser No Fingerprint come si deduce non prevedono l’utilizzo di impronte spettrali per il processamento di riduzione del rumore, se da un lato non sono efficienti nella riduzione del rumore broadband, sono invece più precisi e qualitativi nella riduzione di rumori tonali come Hiss, Buzz, Hum in quanto sono processamenti selettivi, quindi lavorano solo sulla frequenza o range di frequenze prese in esame, non alterando al 100% il segnale audio al di fuori di quello processato e soprattutto se il plugin è a fase lineare.
Sono quasi tutti equalizzatori ottimizzati per questo processo, come l’Hum Removal di figura 13.
Fig. 13
In figura 12 si nota un plugin per la riduzione di rumori impulsivi con la possibilità di utilizzare la tecnologia Fingerprint attraverso i processi di Learn ed Adaptive Learn come visto prima. Presenta anche la gestione della tipologia di rilevamento e correzione, quindi tramite interpolazione oppure semplice rimozione. Visualizzazione monitorata al campione con riferimento temporale.
De-Noiser No Fingerprint
In un contesto generale qualsiasi plugin di Noise Reduction che non preveda tecnica Fingerprint è No Fingerprint.
I plugin De-Noiser No Fingerprint come si deduce non prevedono l’utilizzo di impronte spettrali per il processamento di riduzione del rumore, se da un lato non sono efficienti nella riduzione del rumore broadband, sono invece più precisi e qualitativi nella riduzione di rumori tonali come Hiss, Buzz, Hum in quanto sono processamenti selettivi, quindi lavorano solo sulla frequenza o range di frequenze prese in esame, non alterando al 100% il segnale audio al di fuori di quello processato e soprattutto se il plugin è a fase lineare.
Sono quasi tutti equalizzatori ottimizzati per questo processo, come l’Hum Removal di figura 13.
Fig. 13 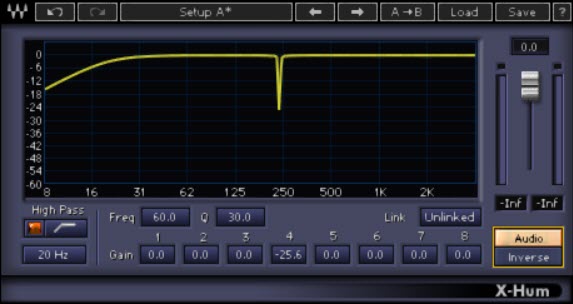 Presenta diverse bande di equalizzazione su cui è possibile agire ( 8 in questo caso, definite anche “bande di armoniche” in quanto che si va a definire che ogni banda deve essere utilizzata per la riduzione di ogni armonica di rumore presente ), per ogni banda è possibile definire solo il grado di attenuazione tramite controllo del gain ed il livello di campanatura ( Q ). E’ possibile attivare un filtro passa alto con frequenza di taglio selezionabile non chè attraverso la funzione Link gestire il processamento indipendente o simultaneo di tutte le frequenze interessate al processamento, se Unlinked ogni banda di frequenze è indipendente dall’altra, se Linked muovendo il gain di una banda di frequenza selezionata si muovono anche tutte le altre con stesso rapporto di attenuazione, se Odd/Even tutte le bande dispari ( 1 – 3 – 5 – 7 ) si muoveranno insieme, quindi se muovo il gain della banda 1 si muoveranno con stesso rapporto anche la banda 3 – 5 – 7, lo stesso per le bande pari ( 2 – 4 – 6 – 8 ), ( il tutto utile per effettuare test di riduzione del rumore in modo più preciso o più pratico ). Ogni banda superiore è l’armonica della precedente ed è fissa e non regolabile ( questo sempre per il principio di riduzione dell’Hum e delle sue armoniche, in alternativa utilizzare un normale equalizzatore a più bande ), per esempio con riferimento per un Hum a 50 Hz avremo che la prima banda ( quella più a sinistra ) sarà appunto la fondamentale 50 Hz, la seconda banda ( quella subito vicino alla sua destra ) sarà la prima armonica a 100 Hz, la terza 150 Hz, la quarta 200 Hz, la quinta 250 Hz, la sesta 300 Hz, la settimana 350 Hz, l’ottava 400 Hz, i parametri di frequenza e campanatura Q sono sempre linkati per tutte le bande utilizzate e non selezionabili in modo indipendente, per cui muovendo la frequenza e/o Q di una banda si muoveranno in rapporto anche tutte le altre. I parametri Frequency e Q saranno sempre in riferimento alla prima banda ( la fondamentale ), tutto il resto delle altre bande seguirà in rapporto alla prima.
E’ possibile invertire il processo di equalizzazione ( tramite Inverse ) per enfatizzare la parte attenuata cosi da capire meglio se effettivamente si sta lavorando sul rumore e non sul segnale audio pulito ( fig. 14 ).
Fig. 14
Presenta diverse bande di equalizzazione su cui è possibile agire ( 8 in questo caso, definite anche “bande di armoniche” in quanto che si va a definire che ogni banda deve essere utilizzata per la riduzione di ogni armonica di rumore presente ), per ogni banda è possibile definire solo il grado di attenuazione tramite controllo del gain ed il livello di campanatura ( Q ). E’ possibile attivare un filtro passa alto con frequenza di taglio selezionabile non chè attraverso la funzione Link gestire il processamento indipendente o simultaneo di tutte le frequenze interessate al processamento, se Unlinked ogni banda di frequenze è indipendente dall’altra, se Linked muovendo il gain di una banda di frequenza selezionata si muovono anche tutte le altre con stesso rapporto di attenuazione, se Odd/Even tutte le bande dispari ( 1 – 3 – 5 – 7 ) si muoveranno insieme, quindi se muovo il gain della banda 1 si muoveranno con stesso rapporto anche la banda 3 – 5 – 7, lo stesso per le bande pari ( 2 – 4 – 6 – 8 ), ( il tutto utile per effettuare test di riduzione del rumore in modo più preciso o più pratico ). Ogni banda superiore è l’armonica della precedente ed è fissa e non regolabile ( questo sempre per il principio di riduzione dell’Hum e delle sue armoniche, in alternativa utilizzare un normale equalizzatore a più bande ), per esempio con riferimento per un Hum a 50 Hz avremo che la prima banda ( quella più a sinistra ) sarà appunto la fondamentale 50 Hz, la seconda banda ( quella subito vicino alla sua destra ) sarà la prima armonica a 100 Hz, la terza 150 Hz, la quarta 200 Hz, la quinta 250 Hz, la sesta 300 Hz, la settimana 350 Hz, l’ottava 400 Hz, i parametri di frequenza e campanatura Q sono sempre linkati per tutte le bande utilizzate e non selezionabili in modo indipendente, per cui muovendo la frequenza e/o Q di una banda si muoveranno in rapporto anche tutte le altre. I parametri Frequency e Q saranno sempre in riferimento alla prima banda ( la fondamentale ), tutto il resto delle altre bande seguirà in rapporto alla prima.
E’ possibile invertire il processo di equalizzazione ( tramite Inverse ) per enfatizzare la parte attenuata cosi da capire meglio se effettivamente si sta lavorando sul rumore e non sul segnale audio pulito ( fig. 14 ).
Fig. 14 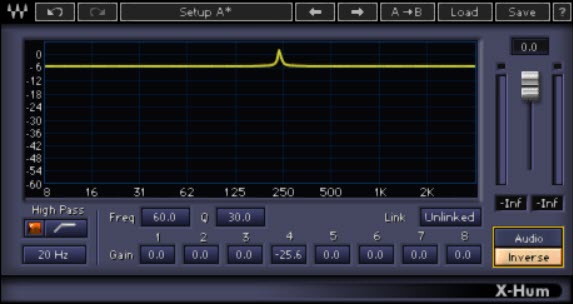 Altri plugin per l’Hum, Buzz, Hiss removal possono presentarsi come quello in figura 15.
Fig. 15
Altri plugin per l’Hum, Buzz, Hiss removal possono presentarsi come quello in figura 15.
Fig. 15 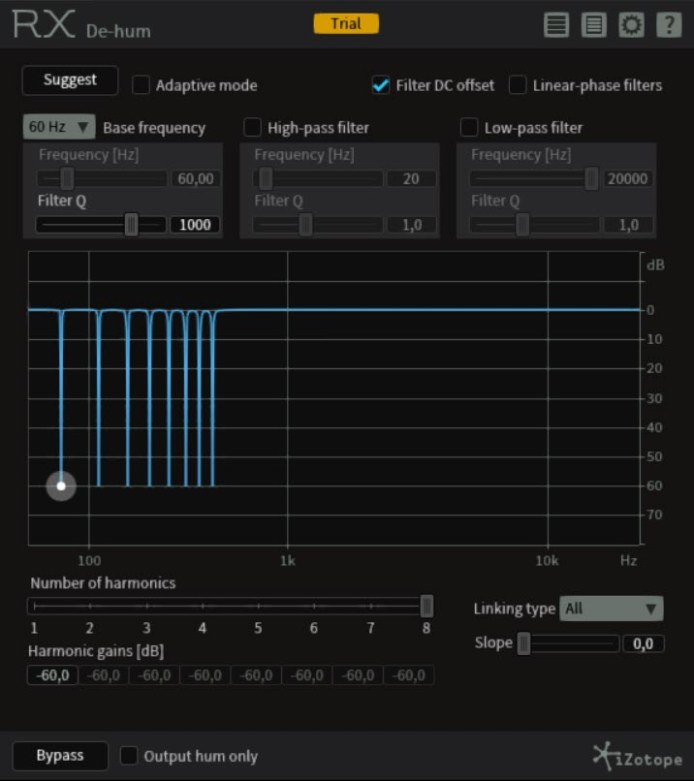 In cui anche qui è possibile selezionare fino ad 8 filtri di equalizzazione, un filtro passa alto ma anche un filtro passa basso entrambi con Q variabile, la possibilità di scegliere se utilizzare una funziona di processamento a fase lineare ( più qualitativa in quanto non altera la fase dello spettro audio e realizzata tramite filtro FIR, ma con un peso sul processore ed un tempo di ritardo superiore, non adatto quindi ad un mixaggio in tempo reale con altre tracce ), o a fase minima ( meno qualitativa in quanto altera la fase dello spettro audio e realizzata tramite filtro IIR, più rapido ma meno qualitativo del FIR, analizzeremo più in dettaglio i filtri FIR ed IIR in altre argomentazioni, il processamento a fase minima è più leggero e con latenza di ritardo prossima allo 0 ). Correzione automatica del DC Offest ( problemi di corrente elettrica del convertitore A/D che può portare un’alterazione e sfasamento dello spettro audio causa di ulteriore rumore Hum ). Funzione Bypass, funzione Output Hum Only che presenta all’uscita solo il segnale audio interessato dal processo di equalizzazione. Funzione Linking per modificare simultaneamente il valore di tutte le frequenze interessante al processamento, indipendentemente, simultaneamente, pari e dispari come precedentemente visto. Impostare una frequenza di base ( la fondamentale ) fissa a 50 Hz ( Hum europeo ) o 60 Hz ( Hum Stati Uniti ), oppure a libera scelta dell’utente.
La funzione Slope regola la pendenza del filtro di ogni banda cosi da renderla più dolce, quindi meno distorcente sul segnale audio che l’attraversa ma con conseguenti maggiori errori di fase in quanto due bande ravvicinate si possono facilmente incrociare, oppure più ripida con maggiore distorsione ma una anche una maggiore precisione con meno errori di fase per ogni singola banda.
Vi è poi la funzione Suggest, grazie alla quale è possibile far analizzare la parte di rumore al plugin che automaticamente rileverà la fondamentale del rumore ed imposterà il filtro di conseguenza.
La modalità Adaptive Mode invece consente di analizzare costantemente la traccia audio ed il plugin si imposta automaticamente sulla fondamentale rilevata ad ogni variazione di rumore nel tempo.
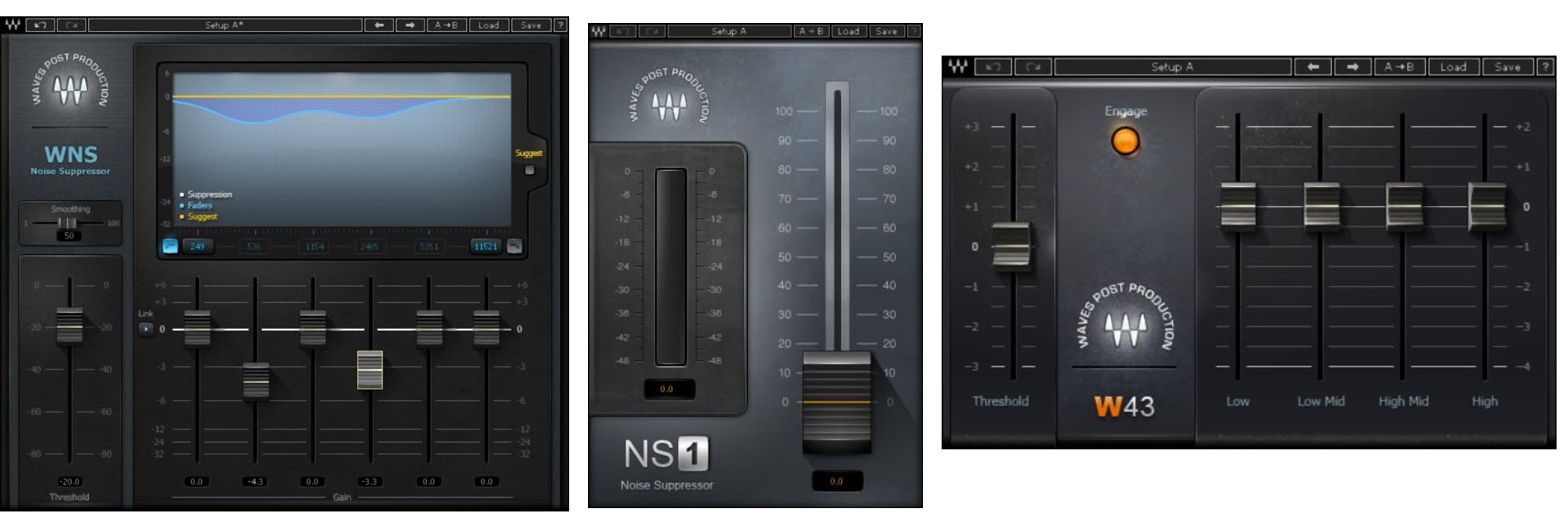
Ci sono anche altri plugin per il De Noiser No Fingerprint ognuno con la sua interfaccia grafica e le sue impostazioni come quelli in figura 16, è bene quindi prima di utilizzare un qualsiasi plugin studiarne bene le sue funzioni per capire bene come sfruttarlo e quale scegliere per le proprio esigenze.
Fig. 16
In cui anche qui è possibile selezionare fino ad 8 filtri di equalizzazione, un filtro passa alto ma anche un filtro passa basso entrambi con Q variabile, la possibilità di scegliere se utilizzare una funziona di processamento a fase lineare ( più qualitativa in quanto non altera la fase dello spettro audio e realizzata tramite filtro FIR, ma con un peso sul processore ed un tempo di ritardo superiore, non adatto quindi ad un mixaggio in tempo reale con altre tracce ), o a fase minima ( meno qualitativa in quanto altera la fase dello spettro audio e realizzata tramite filtro IIR, più rapido ma meno qualitativo del FIR, analizzeremo più in dettaglio i filtri FIR ed IIR in altre argomentazioni, il processamento a fase minima è più leggero e con latenza di ritardo prossima allo 0 ). Correzione automatica del DC Offest ( problemi di corrente elettrica del convertitore A/D che può portare un’alterazione e sfasamento dello spettro audio causa di ulteriore rumore Hum ). Funzione Bypass, funzione Output Hum Only che presenta all’uscita solo il segnale audio interessato dal processo di equalizzazione. Funzione Linking per modificare simultaneamente il valore di tutte le frequenze interessante al processamento, indipendentemente, simultaneamente, pari e dispari come precedentemente visto. Impostare una frequenza di base ( la fondamentale ) fissa a 50 Hz ( Hum europeo ) o 60 Hz ( Hum Stati Uniti ), oppure a libera scelta dell’utente.
La funzione Slope regola la pendenza del filtro di ogni banda cosi da renderla più dolce, quindi meno distorcente sul segnale audio che l’attraversa ma con conseguenti maggiori errori di fase in quanto due bande ravvicinate si possono facilmente incrociare, oppure più ripida con maggiore distorsione ma una anche una maggiore precisione con meno errori di fase per ogni singola banda.
Vi è poi la funzione Suggest, grazie alla quale è possibile far analizzare la parte di rumore al plugin che automaticamente rileverà la fondamentale del rumore ed imposterà il filtro di conseguenza.
La modalità Adaptive Mode invece consente di analizzare costantemente la traccia audio ed il plugin si imposta automaticamente sulla fondamentale rilevata ad ogni variazione di rumore nel tempo.
Ci sono anche altri plugin per il De Noiser No Fingerprint ognuno con la sua interfaccia grafica e le sue impostazioni come quelli in figura 16, è bene quindi prima di utilizzare un qualsiasi plugin studiarne bene le sue funzioni per capire bene come sfruttarlo e quale scegliere per le proprio esigenze.
Fig. 16
Acquista Attrezzatura Audio dai principali Store


