

Di seguito alcune linee guida indicative secondo miei personali studi, esperienze sul campo e test eseguiti nel corso degli anni, cosi da ottenere le basi per poter raggiungere un alto livello di conoscenza al fine di gestire il segnale audio e la percezione uditiva nel migliore dei modi per poter ottenere un suono di qualità.
Alcune di queste indicazioni sono spiegate più in dettaglio in argomenti già trattati nel blog, mentre altre verranno approfonditamente viste più avanti.
Per una maggiore comprensione si consiglia lo studio dei seguenti argomenti:
- Pscicoacustica
- Equalizzatori
- Noise Reduction
- Pre-Amplificatori Audio
- Decibel e Meter
- Microfoni
- Splitter e Sommatori
- D.I. Box
- Cavi Audio Analogici
LIVELLO DI ASCOLTO
Non esporsi a pressioni sonore sopra ai 100 dB sia per un avvicinamento alla soglia del dolore che per intervento del Riflesso Aurale da parte del nostro orecchio, che per inizio trasmissione sonora via ossea con conseguente aumento vertigini, disorientamento, mancata concentrazione occasionale da vibrazione cranio.
Utile quindi tenere monitorato il livello di pressione sonora in cui il livello dB MAX deve essere inferiore ai 100 dBC.
Se il rumore ambientale lo permette abbassare il livello entro gli 85 dBC per rientrare sotto l’intervento del Riflesso Aurale che porta una naturale compressione del suono, riducendo l’effettiva dinamica del suono incidente nel nostro timpano soprattutto per una prolungata esposizione ad alti livelli SPL (indicazione molto soggettiva).
Utilizzare sempre diffusori e strumentazione di qualità con bassi valori di distorsione armonica (sembra scontato), alti livelli di distorsione armonica portano a generare battimenti (quindi percezione di oscillazioni).
Limitare il livello di Distorsione Aurale. La distorsione aurale è derivata dalle armoniche di distorsione naturali dell’orecchio e hanno più valore tanto più è alto il livello SPL incidente, soprattutto 2nd e 3nd armonica e soprattutto in medio-alta e alta frequenza. Per questo è importate non superare i valori limite definiti prima e non enfatizzare eccessivamente le medio-alte ed alte frequenze.
Limitare lo Stress di Ascolto. Lo stress di ascolto definisce il tempo per il quale riusciamo ad essere concentrati prima di avere un calo delle capacità psichiche acustiche, questo tempo è di circa 3 ore e più oggetti e luci ci sono in movimento ed in relazione anche alla loro intensità e più questo tempo cala. Limitare quindi l’ascolto continuo e costante di un suono entro le 3 ore.
Che sia in Studio o Live è importante testare il Loudness (LUFS) del brano musicale, cosi da rapportare adeguatamente i livelli massimi di Loudness nel rispetto dei limiti dB Max precedentemente considerati. Per fare questo è consigliato fare il check sound con il brano di maggiore livello per determinare il loudness massimo e rapportare cosi tutto il resto dei brani.
Mentre per il Live è fondamentale creare il giusto mix per quel tipo di evento in quel tipo di location, per lo Studio e Mastering è buona norma ottimizzare un tipo di ascolto medio, ascoltando il mix con diversi sistemi di riproduzione sonora e a diverse tipologie di “volume”, in quanto che il livello di pressione sonora a cui verrà ascoltato sarà probabilmente differente da utente a utente, da location a location, da impianto audio a impianto audio, da cuffia a cuffia, da sistemi consumer a pro, per cui viene a meno il rispetto dei limiti dBMax precedentemente visti, più dedicato ad un ascolto ed utilizzo professionale in contesto Live, ma applicabile anche per una taratura di Mix di base da cui partire per un mix in studio.
AMPLIFICAZIONE (Gain e Fader)
Utilizzare sempre Preamplificatori (fisici) con risoluzione di guadagno < 0,5 dB. Amplificare o Attenuare con passi da < 0,5 dB consente di processare il segnale il più trasparente possibile, in quanto che 0,5 dB è la risoluzione minima delle nostre orecchie per variazioni di pressione sonora. Al contrario se amplificassimo con risoluzioni maggiori percepiremmo chiaramente “step” di processamento più difficili da gestire e calibrare precisamente.
A livello di Preamplificazione è molto importante amplificare il minimo necessario in quanto che soprattutto a livello analogico più si amplifica e più aumenta il livello di distorsione armonica e di fase introdotta.
In considerazione di un mix, è comunque regola amplificare a dovere fino a garantire un utilizzo dei Fader di controllo dei canali input e output a 0 dB, sempre al fine di mantenere basso il livello di distorsione armonica e fase introdotta dagli stessi Fader, che è maggiore in amplificazione rispetto all’attenuazione, soprattutto a livello analogico (per fare questo può essere molto di aiuto se non essenziale, il corretto dimensionamento ed installazione dell’impianto audio, altrimenti può risultare sotto o sovra dimensionato), quindi tutti i controlli e dispositivi di processamento – amplificazione – diffusione oltre che di qualità devono essere considerati in un progetto a regola d’arte.
La filosofia di base per un suono di qualità è sempre quella di: Meno si amplifica e meglio è.
Se si utilizzano Sub Group, DCA o VCA è da fare attenzione a non sommare le distorsioni dei Fader/Canale NON a 0 dB con le eventuali distorsioni date dai Master Fader dei Sub Group, DCA, VCA non a 0 dB. Quindi almeno i Fader/Canale è bene che si trovino a 0 dB e poi il mix lo si effettua con i Master Fader Sub/DCA/VCA. Come linea generale un corretto Mix nell’utilizzo di Fader (canale o master) è buona norma lavorare in attenuazione tra una soglia di 0 e 3/5 dB, che è la risoluzione minima necessaria per percepire un suono più forte o più attenuato, più presente o più lontano rispetto all’altro garantendo il minimo delle distorsioni possibili.
Per quanto riguarda l’invio di un segnale audio ad un ingresso di Preamplificazione, amplificazione, processamento, recording, è stato stimato che a livello analogico per avere minima percezione di distorsione armonica e fase connessa alla non linearità dei sistemi qui elencati, il livello del segnale audio deve essere circa – 24 dB rispetto al picco stimato dal produttore.
Mentre in dominio digitale (quindi un trasporto In/Out di segnale audio in dominio digitale) è possibile gestire il livello di segnale fino allo 0 dBFS, meglio qualche dBFS prima del clip a 0 dBFS, -1 dBFS l’ideale per limitare le distorsioni di processamento del convertitore D/A, e dei vari circuiti digitali di Ingresso e Uscita.
Non utilizzare il Trim di amplificazione digitale senza prima aver preamplificato adeguatamente il livello di segnale audio in ingresso in quanto che dal Trim il livello di amplificazione viene dato digitalmente, ma avendo di base un basso livello di segnale per mancata Preamplificazione porterà risultati scadenti con bassi range di amplificazione e alto rumore di fondo, soprattutto se si utilizzato encoder scadenti. Al contrario invece si ottimizzerà il livello di segnale audio per la conversione.
In pratica il Preamplificatore amplifica la forma d’onda mantenendo un alto rapporto segnale/rumore mentre il Trim alza semplicemente il livello di ingresso aumentando di conseguenza anche il rumore di fondo.
Anche i Makeup Gain dei circuiti dei processori Dinamici sono essenzialmente dei Trim, per questo è bene utilizzare il Makeup Gain o Auto MakeUp Gain per i sistemi automatici solo ed esclusivamente si si vuole amplificare la parte dinamica bassa dello spettro (armoniche, boost di uno specifico range di frequenze, ecc…), facendo sempre attenzione a quale rumore e risonanza porta ad essere percepito.
GESTIONE EQUALIZZATORE E FILTRI
Per trasparenza e qualità utilizzare sempre equalizzatori digitali/software, per armoniche e sonorità tipiche analogiche utilizzare equalizzatori analogici.
La maggior parte dei plugin interni nei mixer audio è IIR, preferire quindi se possibile l’utilizzo di equalizzatori e filtri plugin esterni FIR (in contesto Live è da valutare la latenza).
In utilizzo di filtri di taglio è da considerare che lo spettro armonico di uno strumento musicale copre una sempre più ampia Bandwidth tanto più il livello di pressione sonora emessa è maggiore, in quanto che prendono forza e vigore anche le armoniche più attenuate. Questo si traduce che impostando una determinata frequenza di taglio per un livello di segnale in ingresso ridotto, questa non è più valida per un livello di segnale in ingresso più elevato. Oltre a questo la pendenza naturale di taglio passa-basso e passa-alto dello strumento stesso varia al variare dell’intensità percussiva, in cui tanto più percussivo ed intenso è il suono emesso dallo strumento e tanto più ripida è la pendenza di taglio dipendente dallo smorzamento stesso della corda, pelle, ecc.. producente il suono (strumenti melodici ed armoniosi avranno pendenza più dolci, mentre strumenti percussivi come ad esempio batteria acustica e percussioni, tanto più si “picchia” con la bacchetta sulla pelle e tanto più ripida diventerà la pendenza di taglio avendo una maggiore separazione tra le fondamentali ed armoniche di valore rispetto alle armoniche spurie e di risonanza).
In considerazione di un equalizzazione trasparente nel rispetto dello spettro tonale dello strumento da processare, impostare la frequenza di taglio al livello di taglio più basso (indicativamente in quanto dipende molto anche dai rientri soprattutto in contesto live), così da consentire la piena espressione tonale sia ai livelli dinamici più bassi che a quelli più alti, con l’accortezza di tagliare l’opportunamente frequenze risonanti ed indesiderate.
Per quanto riguarda la pendenza di taglio, anche qui per il mantenimento di una corretta distribuzione tonale è utile utilizzare la pendenza che considera la maggiore ripidità espressiva, cosi da evitare per pendenze più dolci di tagliare l’espressione soprattutto della fondamentale quando la maggiore intensità e quindi ripidità di taglio si presenta.
È opportuno durante il mixaggio monitorare l’andamento dello spettro dello strumento cosi da bilanciare correttamente l’eventuale spostamento del valore utile prima definito per la frequenza di taglio e pendenza del filtro.
Se l’equalizzatore lo consente, utilizzare lo Shift per variare la posizione delle frequenze e ascoltare se cosi facendo escono fuori armoniche, risonanze, maggiore o minore presenza di particolari toni e strumenti. Questo perché un errata impostazione dei filtri può portare alla percezione di mascheramenti, battimenti, ma anche far risaltare risonanze e Comb Filter dall’interazione di più segnali audio in un mix.
Se l’equalizzatore lo consente utilizzare uno Scale o Inverter per invertire proporzionalmente la curva di equalizzazione fatta, questo può essere utile sempre per capire bene se si è agito troppo o troppo poco su particolari frequenze, se si è lavorato precisamente sul tono di interesse e sempre se il cambiamento porta a mascheramenti, risonanze, battimenti, ecc..
(Shift and Scale)

CONDIZIONI AMBIENTALI ED ELETTRONICHE
Nell’ambiente in cui viviamo il suono viene percepito per via aerea e si trasmette attraverso il fluido Aria, questo fluido non è lineare e presenta viscosità, per cui resistenza intrinseca, umidità, pressione atmosferica, vento, pioggia, campi elettromagnetici, inversione termica (di mattina il suono tende ad andare verso il basso in quanto che il terreno è più fresco rispetto all’aria soprastante che via via tende a riscaldarsi per l’arrivo del sole, di sera invece il suono tende ad andare verso l’alto in quanto l’asfalto rimane più caldo essendo stato irradiato dai raggi solari tutto il giorno e l’aria soprastante diventa sempre più fredda per via del calo del sole e l’arrivo della sera), il suono tende sempre ad andare verso zone di maggiore inerzia, quindi verso a perdere energia, tutti questi fattori faranno variare i parametri acustici direzionali, tonali e dinamiche delle sorgenti sonore.
In più fattori di Riflessione, Diffrazione e Trasmissione sonora (presenti soprattutto in ambienti al chiuso) deviano ed alterano il suono propagante sempre nei tre parametri acustici quali Direzione, Tono e Dinamica con aggiunta di Risonanze e problemi di Fase, oltre a come questo viene percepito per via dell’anatomia e risoluzione del nostro apparato uditivo come ampiamente visto in argomento Psicoacustica con Battimenti, Echi, Mascheramenti, ecc…
Anche i rumori esterni ambientali o artificiali “HVAC” incidono sulla corretta percezione del suono, favorendo distrazione di ascolto, mascheramenti, battimenti, effetti di risonanza e controfase.
Per questo prima di mixare un qualsiasi brano sonoro sarà importante aver prima fatto un progetto ottimizzando l’ascolto sonoro in considerazione anche del rumore di fondo e rumore ambientale, quindi una simulazione e poi realizzazione dell’ottimale configurazione dell’impianto audio in ambiente live, di una realizzazione ad hoc di una sala di musica, sala di recording, ambiente di ascolto.
In caso di vento, forti livelli di umidità, ambienti molto riverberanti e riflettenti, è opportuno utilizzare filtri anti-vento (wind filter) sulle capsule microfoniche per limitarne gli effetti indesiderati.
Per quanto riguarda invece l’elettronica dei componenti utilizzati, soprattutto gli Altoparlanti, il loro riscaldamento da un continuo lavoro (essendo perennemente attraversati da tensione elettrica che genera fenomeni di induzione e trasformazione dell’energia elettrica in calore, quantomeno per gli altoparlanti a bobina mobile), il loro rendimento cala con il tempo e quindi si genera un’attenuazione del livello di pressione sonora in uscita (Power Compression), con anche possibili alterazione sulla risposta in frequenza e dinamica.
Anche l’amplificatore finale stesso è indice di fenomeni di Power Compression verso l’Altoparlante a cui è collegato in quanto dipende molto da come questo amplificatore gestisce il carico e quindi la tensione inviata, oltre che il tutto dipendere anche dalla potenza di erogazione.
Nella scelta di un Finale di Potenza, un Damping Factor più alto è sicuramente una buona scelta per minimizzare fattori di distorsione Amplificatore-Altoparlante.
Ad oggi con le nuove tecnologie di finali ed altoparlanti il fenomeno della Power Compression è limitato a circa 3 – 4 dB nell’arco di 2 – 3 ore di funzionamento continuo.
Il fenomeno di attenuazione Power Compression deve essere considerato nel mix, può essere buona norma partire con un livello master fader a circa – 5 dB per poi aumentare quando necessario fino ad arrivare al massimo a 0 dB, che rappresenta lo standard di riferimento per un pulito livello di segnale.
Il monitoraggio dello spettro RTA e livello SPL dell’impianto audio via software attraverso appositi tool di analisi spettrale è quindi altamente consigliato.
DISTANZA DI ASCOLTO
Minima: È importante trovarsi con l’ascolto al di fuori del campo vicino dell’impianto audio (soprattutto in considerazione di frequenze omnidirezionali e in altoparlanti a radiazione diretta) così da evitare le riflessioni, diffrazioni ed interferenze, non ché turbolenze soprattutto in bassa frequenza generate dalle dimensioni fisiche dell’impianto stesso (e questo dovrebbe essere ottimizzato in fase di simulazione acustica nell’installazione dell’impianto audio).
A discapito del credo comune non è necessaria una distanza ottimale in base alla frequenza (si dice che per sentire le basse frequenze bisogna trovarsi a distanze oltre meta della lunghezza d’onda), in realtà il nostro apparato uditivo percepisce sempre tutte le frequenze e la loro percezione va in base all’intensità sonora e alla risoluzione del nostro orecchio.
Massima: La distanza di ascolto massima è in relazione al progetto acustico, tale da consentire un’omogenea copertura (SPL, risposta in frequenza, dinamica) dell’area destinata all’ascolto.
È importante poi trovarsi nel centro del fuoco dell’impianto audio, tale da percepire una corretta fase, un suono mono percepito perfettamente centrale, così da poter gestire al meglio un mix di mediazione nell’immagine e dinamica (difficile in ambiente Live dove i ricettori sono nelle più svariate posizioni e qui il progetto acustico è di fondamentale importanza per poter permettere a tutti di percepire un suono chiaro e presente).
In un ambiente riverberante è importante che il campo riverberante sia il più lontano possibile.
Per quanto riguarda il pannare o non pannare strumenti musicali soprattutto in ambiente live dove spesso il ricettore di ascolto è diretto verso un lato dell’impianto audio e a cui non arriva il contributo del resto del sistema audio percependo esclusivamente un suono mono e rischiando quindi se pannato lo strumento sul lato opposto di perderne il fuoco e la percezione dello strumento stesso, si può dire che il pan anche in queste situazioni può essere largamente utilizzato se pur mantenendo un contenimento superiore rispetto ad un ascolto puro stereofonico (quindi da valutare caso per caso in base alla posizione dei ricettori e alla distanza tra i vari sistemi di ascolto), questo perché il nostro orecchio come spiegato in Psicoacustica agisce tramite modalità Ventriloquo, e cioè per una sorgente vista lontana il nostro cervello si aspetta un suono più scuro e riverberante, meno definito e per cui il deficit sulla focalizzazione e localizzazione è contenuto, mentre al contrario se gliela rendiamo più chiara e presente tende ad essere percepita come poco naturale.
OTTIMIZZAZIONE DELLA CATENA AUDIO
Analogico vs Digitale
Alternare processi di conversione A/D – D/A non porta buoni risultati ma solo rumore ed errori di conversione, per questo è buona norma effettuare tutti i processamenti analogici insieme e digitali insieme, o tuttalpiù lasciare il processo analogico all’inizio e alla fine della catena audio.
È molto importante la stabilità della tensione-corrente elettrica soprattutto in utilizzo di convertitori e processamento digitale, causa DC Offset con riduzione dinamica ed un più vicino livello Max prima della distorsione.
n.b. Strumenti con naturale ampia dinamica come la voce sono i primi a risentirne, soprattutto quando all’impianto audio viene richiesta molta energia.
Utilizzare per cui sempre stabilizzatori di corrente-tensione, amplificatori finali con tecnologia di assorbimento modulare es. Classe D (quindi assorbe corrente-tensione solo quando viene richiesto). Nel caso ci si trovi in queste situazioni senza possibilità di soluzione è consigliato mantenere bassi livelli di tensione-corrente (un impianto più efficiente può essere la soluzione).
In ambito analogico è importante il rispetto delle impedenze in cui ZOut < ZIn fino a limiti legati al grado di attenuazione e amplificazione per cui una troppo elevata impedenza di ingresso catturerà si meglio il segnale audio ma offrirà anche una maggiore attenuazione poi da recuperare amplificando maggiormente rispetto a come se ci fosse un’impedenza di ingresso più bassa. Per questo e perché più si amplifica e più si introducono distorsioni armoniche ed inarmoniche la qualità del Preamplificatore è fondamentale.
Per comparazione un dispositivo analogico preso singolarmente può ottenere dinamiche superiori a quelle digitali (fino a 24 bit), ma all’interno di una catena audio in cui si gioca con le impedenze ed interferenze esterne, diventerà sempre più povero e meno qualitativo.
In più il livello di distorsione armonica introdotta sul segnale audio analogico rispetto a quello digitale è distribuito su tutto il percorso di amplificazione-processamento, tanto più ci si avvicina al livello Max prima di distorsione dichiarata come standard dal produttore e tanto più le armoniche e livelli di distorsione cresceranno.
Nel dominio analogico la maggior parte dei rumori oltre che per un non corretto rapporto di impedenza in cui se quella di ingresso è troppo bassa si generano perdite in medio-alta ed alta frequenza ed incremento armonico di distorsione, è dato anche da un impoverimento dei condensatori e VCA che tendono a generare un rumore bianco a volte oscillatorio.
In dominio analogico come già anticipato, per la gestione del livello di segnale da inviare ad un circuito di ingresso o di uscita è sempre bene rimanere entro i – 24 dB rispetto al valore massimo dichiarato prima della distorsione. Per i Preamplificatori integrati è possibile guadagnare qualche dB in quanto il rapporto segnale rumore è ben più alto rispetto a quelli attivi o ancor più passivi.
In dominio digitale invece le impedenze sono sempre perfette ZOut = ZIn, ed i livelli di ottimizzazione del trasferimento del segnale audio sono determinate dal livello di tensione, in questo caso la circuiteria di ingresso del dispositivo che riceve determina la qualità del segnale audio. I dispositivi convertitori, dispositivi di Input e Output hanno un modulo di tolleranza per determinare la lettura del segnale audio digitale sul livello di tensione al loro ingresso. più la tolleranza è piccola e tanto più qualitativo sarà il circuito perché meno mediato nelle operazioni di calcolo, a scapito però di una perdita di informazioni in caso che vi siano sbalzi di tensione non controllati che finiscono a livelli sotto quelli di tolleranza creando artefatti e in certi casi la perdita di sincronismo e trasferimento del segnale.
In dominio digitale la distorsione del segnale audio avviene solo una volta superati gli 0 dBFS e per questo si ha molta più pulizia anche a livelli alti di tensione/amplificazione.
E’ consigliato in ogni caso rimanere sempre almeno a -3 dBFS sotto lo 0 dBFS in quanto può capitare che tra l’uscita ed ingresso di più processori ma soprattutto durante la fase di conversione D/A (spesso ottimizzata dal costruttore, in cui avviene anche la maggiore perdita di informazioni ed impoverimento dinamico) si verifichino leggere risonanze che portano ad un aumento del livello di uscita rischiando appunto di superare gli 0 dBFS (limite prima della piena distorsione in onda quadra del segnale digitale). Stesso discorso per il processo di conversione formato, in cui soprattutto i codec Lossy possono far eccedere il segnale audio in uscita dal Codec di qualche dBFS e quindi rischiare la distorsione.
In dominio digitale è molto importante non portare in distorsione il software utilizzato per il processamento o ancor più il convertitore, causa elevati digititis.
In generale anche se con un rapporto inferiore rispetto al caso analogico, in dominio digitale più ci si avvicina allo 0 dBFS e più aumenta il livello di distorsione digititis.
n.b. Per digititis si intende l’insieme degli errori digitali (Jitter, Offset, distorsioni, perdite di clock, errori di quantizzazione, ecc..).
Detto questo il processamento a livello digitale, ancor più software è sempre la soluzione migliore (se di qualità), altrimenti gli errori e distorsioni digitali danno un risultato di ascolto più scadente rispetto a quello analogico, in quanto i digititis che si vanno a creare in dominio digitale sono più complessi e difficili da campionare per i vari stadi di processamento in quanto non armonici e casuali.
Per quanto riguarda le distorsioni “volute”, queste è sempre bene farle con dispositivi analogici che hanno un forte contributo di armoniche pari, in quanto più gradevoli all’orecchio.
Il segnale audio digitale ha livelli operativi di tensione molto più elevati rispetto all’analogico e questo permette di avere maggiori dinamiche ed essere con il livello di segnale più lontani dal rumore di fondo.
In generale è importante sapere se ci si trova con il Meter del livello di uscita con il segnale oltre lo 0 dB (FS), è necessario aumentare la potenza o comunque pressione sonora dell’impianto audio utilizzato per quell’evento così da ridurre il livello di segnale in uscita e migliorare la qualità audio finale. Al contrario diminuire la potenza se il livello di segnale è molto sotto lo 0 dB. Stesso discorso per il Meter di ingresso a controllare che il circuito di amplificazione ed interno dei vari processori non vada in distorsione.
Lavorare sempre ai più alti livelli di campionamento e quantizzazione per ottimizzare la conversione dell’onda analogica, ottenere più ampie dinamiche e minimizzare il problema dei digititis di distorsione.
Fondamentale poi la qualità dei convertitori e circuiteria In/Out che sia hardware o software per minimizzare Jitter, problemi di sincronismo, clock e trasferimento dati. Anche la Latenza deve essere la più bassa possibile, migliorando così il trasferimento lungo la catena audio con minime perdite di informazioni da interferenze esterne e dalla circuiteria stessa utilizzata.
Convertitori PCM sono sempre migliori rispetto a quelli DSD (anche se è oggetto di discussione) e Sigma Delta in quanto presentano una maggiore fedeltà dinamica, ma, soprattutto quelli a bassa risoluzione (sotto i 24 bit), necessitano di Dither (rumore introdotto) per una corretta conversione A/D e D/A (più scadenti ma che ad oggi quasi in disuso in quanto non si lavora più sotto i 24 bit).
I PCM sono anche più costosi in quanto che più complessi come circuito, mentre i Sigma Delta (i più utilizzati a livello consumer) sono più semplici lavorando ad 1 bit di quantizzazione e non necessitano di Dither, ma sono anche meno precisi, ma meno costosi.
In caso di utilizzo plugin, software, hardware digitale, utilizzare sempre il massimo della risoluzione di quantizzazione in quanto che come già anticipato a 16 – 24 bit si hanno problemi di troncamento LSB con necessario utilizzo del Dither e quindi distorsione e rumori. Valori ottimali > 24 bit.
E’ importante avere un buon livello di segnale audio all’ingresso del convertitore A/D e D/A per ridurre le distorsioni di conversione.
Preamplificatori
A livello analogico i Preamplificatori consentono spesso (quelli di maggiore qualità) più alti livelli di tensione prima della piena distorsione, ma rispetto ai Circuiti Integrati (Amplificatori Digitali) hanno anche un maggiore rumore armonico generato. I Circuiti Integrati hanno un livello massimo di ingresso a +24 dB secondo lo standard digitale SMPTE, che è anche il limite di livello di ingresso nei convertitori A/D, in quanto limite per il segnale digitale a 0 dBFS, per cui anche inviando un segnale proveniente da un dispositivo analogico con Max Input a +30 dB, questo dovrà essere comunque limitato a +24 dB per non mandare in distorsione il convertitore.
Vale comunque sempre la regola: Meno si Amplifica e Meglio è!
Utilizzare Preamplificatori con il più basso livello di rumore, il più alto livello di guadagno, il più basso livello di Step sulle variazioni di amplificazione, con il più alto livello di Max. Input, la più bassa impedenza di uscita, un adeguata impedenza di ingresso in base all’impedenza del segnale in uscita dal dispositivo da collegare e con i più bassi valori di Crosstalk.
Protocolli digitali e Clock
In ambito digitale utilizzare protocolli di trasmissione dati audio (AES50, DANTE, RAVENNA, SOUNDGRID, MADI, ecc..), che garantiscano qualità con più bassa latenza possibile, che garantiscano il più veloce trasferimento di segnale ed ampia Bandwidth, più basse tolleranze tra circuiti di In/Out con la possibilità di realizzare ridondanze per aumentare il livello di sicurezza contro cadute di segnale accidentali e che permettano diverse tipologie di configurazione per ottimizzare il percorso di segnale audio secondo le necessità (anello, stella, cerchio, punto a punto). Se possibile utilizzare sempre lo stesso protocollo per garantire un maggiore sincronismo e meno distorsione tra le varie circuiterie di ingresso, quantomeno non abbassare la velocità di trasferimento del segnale audio bitrate, ed utilizzare sempre il Clock del protocollo in utilizzo, in quanto che utilizzandolo esterno possono esserci problemi di corretto sincronismo soprattutto se il Clock esterno ha una velocità “bitrate” inferiore. Utilizzarlo esterno se ha velocità superiore o se quello integrato nel protocollo è scadente o ha problemi di sincronismo.
Per quanto riguarda i Clock, gli oscillatori al quarzo sono i migliori generatori di clock, quelli digitali sono più precisi ma anche più instabili in quanto dipendono dalle capacità della CPU. Da qui si capisce come la stabilità del Clock sia fondamentale e per questo ancor più in digitale la tensione elettrica di alimentazione deve essere garantita pulita, lineare e stabile.
Utilizzare sempre e se possibile un trasferimento di segnale digitale Sincrono, in quanto più rapido e preciso rispetto a quelli Asincroni e Isocroni, anche se di contro hanno una limitata configurazione e meno versatilità.
Cavo e Connessione Bilanciata vs Sbilanciata
In ambito analogico per piccole distanze utilizzare sempre connessioni sbilanciate in quanto che il bilanciamento introduce sempre rumore di fondo e distorsione dell’onda. In caso si utilizzano linee bilanciate come ad esempio in grandi eventi in cui il segnale deve percorrere grandi distanze, utilizzare sempre i migliori trasformatori e bilanciare il segnale sbilanciato con le migliori D.I. Box considerando il giusto rapporto di impedenze tra Out/In. Prevedere l’utilizzo di D.I. Box anche per linee sbilanciate al fine di ottimizzare il trasferimento di carico sulle impedenze.
È importante che il cavo abbia le migliori caratteristiche possibili, soprattutto più basso livello capacitivo, resistivo ed impedenza al Km, ottenibile con il più pulito reticolo cristallino del materiale utilizzato (per il caso rame o argento) per far attraversare il segnale audio, a partire da cavi OFC 100% od OCC, considerare l’utilizzo di cavi NON-PVC per minimizzare i fenomeni di interferenza. Sarà inoltre importante il tipo di schermatura a bilanciare le caratteristiche tecniche appena elencate.
Per la fibra ottica invece la schermatura non è necessaria in quanto è intrinsecamente immune alle interferenze elettromagnetiche.
Non lasciare mai un qualsiasi cavo adibito al trasporto audio vicino a cavi di corrente per via dell’effetto pelle che porta risonanze sul segnale audio. Un ottimo cavo audio è poi realizzato intrecciato per minimizzare l’effetto capacitivo). I cavi audio di potenza non sono né da intrecciare e né da tenere vicini a cavi di corrente sempre per l’effetto pelle, che ha valore per elevati livelli di tensione-corrente elettrica.
In dominio digitale è importante scegliere il giusto cavo per il giusto protocollo del segnale trasportato, es. il campionamento a 48 KHz ha generalmente una banda di trasmissione di 100 M/bits ed è correttamente trasportabile con cavi ethernet Cat5, 96 KHz ha una banda di 1000 M/bits ed è correttamente trasportabile con Cat5e o meglio Cat6 e superiori.
La fibra ottica garantisce il più veloce trasferimento dati tra connessione di uscita ed ingresso (minore latenza), ed anche qui è necessario scegliere il cavo adatto a seconda del Bitrate e Bandwidth richiesto dal protocollo. Se la latenza è alta tra le varie connessioni dei dispositivi di Input e Output l’utilizzo di un cavo in fibra ottica può aiutare.
La fibra ottica è anche più fragile rispetto al cavo ethernet ma consente di raggiungere più ampie distanze, per l’ethernet il limite massimo con velocità di Bandwidth a 1000 M/bits è 100 – 150 metri, ma il limite corretto da tenere anche contro interferenze e minimizzare errori di trasporto è 75 metri. Più la velocità di banda è bassa e più corto dovrà essere il cavo. Per 500 M/bits consigliato 50 – 70 metri.
n.b. I M/bits del protocollo digitale sono la velocità di invio pacchetto dati da parte del circuito di uscita e quindi ricezione del circuito di ingresso, la Bandwidth è invece lo spazio occupato da quel tipo di segnale, derivato dal numero e tipo di informazioni di cui è composto, più è alta la Bandwidth e più informazioni ad esempio Canali audio può portare quel cavo, quel protocollo, quindi il cavo digitale ha una sua capacità di trasporto, quindi velocità e Bandwidth.
Processori Tonali e Dinamici
Lavorare con Equalizzatori Dinamici e non con l’utilizzo di Equalizzatori e processori di Dinamica separati (se non per eccezionali controlli), è la soluzione ottimale per un suono di qualità, potendo effettuare simultaneamente correzioni tonali e dinamiche, riducendo così rumori ed artefatti dal collegamento di più processori in cascata, ma anche in parallelo, stesso discorso in utilizzo di Plugin.
Come spiegato bene in argomento Equalizzatori, l’Equalizzatore Dinamico offre vantaggi di una maggiore precisione ed accuratezza nel processamento tonale e viceversa in utilizzo di un processore Dinamico.
Ad oggi l’evoluzione dei processori dinamici è quella con degli Equalizzatori Dinamici controllati dall’Intelligenza Artificiale che ottimizzano il tutto in modo automatico.
Finale di Potenza
Evitare di inviare un segnale audio Analogico eccessivo all’ingresso dell’amplificatore finale di potenza in quanto che è il più debole della catena audio avendo solo 3 dB di Headroom, quindi può essere facilmente portato in distorsione, i più professionali presentano sezioni di limiting e compressione, che non permettono la distorsione ma tendono a schiacciare la dinamica del segnale audio in ingresso. Fare quindi attenzione a rimane con i picchi ad un livello di dB sotto i 3 dB di Headroom del finale che spesso non coincidono con il livello di segnale audio in uscita dal mixer in quanto poi lungo la catena audio che va dall’uscita del mixer all’ingresso del finale ci possono essere perdite di segnale soprattutto in utilizzo di lunghe metrature di cavo.
La soluzione migliore in ogni caso è quella di collegarsi al Finale di Potenza digitalmente ottimizzando quindi il rapporto tra segnale in uscita e quello in ingresso al finale, migliorando inoltre la qualità e fedeltà del segnale audio in quanto che a livello analogico il circuito di ingresso del finale porta ad alterazioni della risposta per introduzione di armoniche rilevanti e tutti quei fenomeni di distorsione precedentemente visti.
Streaming
Per testare se uno streaming o una riproduzione da interfaccia audio digitale risulta ottimale, è buona norma inviare una sinusoide (es. 1 Khz) e vedere il livello di buffer da tenere prima che il segnale audio cominci a “saltellare”, più basso è il suo valore e migliore saranno i driver e scheda audio stessa o trasmissione in streaming.
In utilizzo di Media Player da PC o MAC è necessario seguire e quindi scegliere il giusto e più qualitativo software che garantisca questi fattori:
- Non dare SRC in modo automatico e se presente disattivarlo (quindi possibilità di disattivarlo).
- Poter definire il Dither da associare correttamente al DAC quando necessario (in quanto audio a 32 bit e superiore o DAC Sigma Delta non ne necessitano, mentre i player consumer inviano Dither a priori, mentre molti brani hanno già un loro Dither presente inserito in fase di bounce “mix finale”).
- Un player in grado di gestire il Clock dell’interfaccia collegata alle variazioni si Sample Rate, questo utile esclusivamente se risponde meglio del Clock interno dell’interfaccia (in quanto il clock del player è generalmente su software mentre quello dell’interfaccia è spesso analogico al quarzo, utile ad esempio dopo anni di utilizzo di quello interno all’interfaccia che ha quindi subito variazioni di stabilità).
- Possibilità di gestire il livello Buffer al fine di ottimizzare sempre la qualità audio.
- Utilizzare sempre un flusso dati tramite driver ASIO (questo dipende dall’interfaccia audio collegata), in alternativa utilizzare DirectX se pur meno di qualità, è un driver di Windows per cui compatibile con qualsiasi interfaccia compatibile con Windows.
OTTIMIZZAZIONE DELLA RIPRESA MICROFONICA
In caso di multi microfonaggio è molto importante la correlazione di fase e tempo tra i vari segnali per minimizzare gli effetti di Comb Filtering e Battimenti soprattutto per strumenti con simile spettro sonoro ed ancor più per strumenti ripresi da più di un microfono (vedi la batteria acustica dove spesso si utilizzano microfoni di prossimità con microfoni panoramici, o doppi microfoni come Rullante sopra e sotto, o Cassa dentro e fuori, o ancora Basso in D.I. e Cabinet microfonato, doppio microfono per Cabinet Chitarra elettrica, ecc…).
In caso di problemi di fase in medio-alta e alta questo è possibile risolverlo anche pannando i vari segnali tra Left e Right e/o Surround per minimizzare i problemi di fase dalla loro somma mono, verranno percepiti dalle nostre orecchie come un’estensione stereofonica o surround sul piano orizzontale o 360°. Sulle basse frequenze soprattutto è invece fondamentale la correlazione di fase per non creare Comb-Filter.
Alcuni esempi possono essere le riprese di prossimità insieme a quelle d’accento e a distanza nella ripresa di un’orchestra. È importante che i microfoni più vicini siano correttamente ritardati per andare in fase con quello di ripresa più lontano. Se ai microfoni più lontani ci sono ulteriori rientri, esempio di altre sezioni, è importate che tutto l’insieme del microfonaggio dia un tempo di ritardo (tra l’uno e l’altro) medio complessivo più basso possibile. Questo è comunque guadagnato rispettando la regola del 3:1 e il livello SPL dei ritorni inferiore ai – 10 dB. Microfoni adibiti alla ripresa ambientale possono non essere messi in fase in quanto non sono utilizzati per la ripresa dello strumento.
Microfoni con ripresa a distanza e d’accento nel caso di un orchestra ad esempio disposta a cerchio, va a loro sincronizzato il ritardo della prima linea per i microfoni della prima linea, sincronizzato il ritardo della seconda linea per i microfoni della seconda linea e cosi via..
Regola del 3:1
La regola del 3:1 è una legge generica e semplicista che va su di un’ottimizzazione sicura ma non considera la qualità del segnale ripreso nella definizione di un suono chiaro, presente, dinamico. Questo perché ogni strumento ha un suo diagramma polare di dispersione sonora che varia in base alla frequenza, e la distanza da esso è determinata dalla sua estensione quindi quanto è grande e come è composto, da che risposta si vuole catturare ed in relazione anche ai rientri e rumori esterni.
Regola del 3:1 (modificata)
Per questo una microfonazione di qualità è fatta in considerazione di un mix di queste cose:
- Diagramma polare e risposta del microfono in asse e fuori asse.
- Diagramma dispersione polare dello strumento
- Ottimizzazione del posizionamento in relazione ai precedenti elementi
- Distanza del secondo microfono come media tra i fattori di rientro di segnale tra i due microfoni (giocando eventualmente anche sulla direttività polare del microfono stesso), ma che non escluda la corretta ripresa sempre secondo i diagrammi polari sorgente – microfono.
- E cosi via per tutti i microfoni aggiunti.
- Per una corretta correlazione di fase è possibile in primis utilizzare il Pan se richiesto nel mix ed in ogni caso e soprattutto per riprese monofoniche, la messa in fase in relazione alla distanza rispetto alla sorgente (in considerazione di mettere in fase riprese ravvicinate con riprese a distanza, o la messa in fase di un multi microfonaggio).
In generale è sempre meglio avere un diagramma polare di ripresa microfonica più direttivo per minimizzare il livello di rientro rispetto a dover applicare dei ritardi temporali per metterli in fase.
Ritardo di Fase
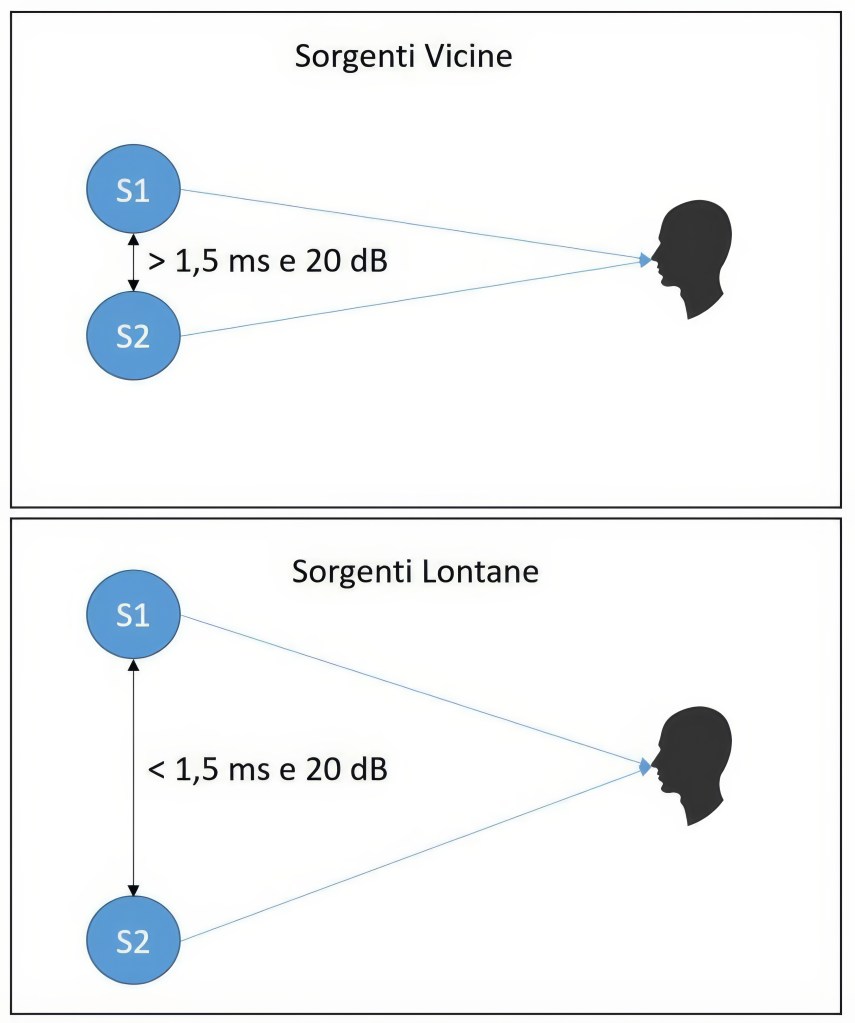
Per quanto riguarda il tempo di ritardo sarà fondamentale che lo sfasamento sia contenuto entro i 60 gradi, quindi una mediazione dei ritardi positiva. Se questi rientri sono entro i 60 gradi l’effetto sarà sempre un Boost e non una controfase con attenuazione della risposta (giocando a nostro favore). Ma in ogni caso il tempo deve essere entro i 2 – 3 ms per non essere percepito come eco soprattutto in medio alta frequenza.
Anche l’utilizzo di un diverso trasduttore come può essere un microfono a condensatore con uno dinamico a pari distanza può voler dire applicare un ritardo temporale per via dei ritardi naturali differenti tra i due trasduttori.
Anche gli stessi componenti utilizzati come il percorso di segnale (cavo, preamplificatore), possono portare differenti ritardi, soprattutto se si compara un percorso di segnale analogico con quello digitale.
Un fattore critico ad esempio può essere la ripresa di un’orchestra dove sorgenti diverse rientrano simultaneamente in molteplici microfoni a diverse posizioni.
Per ottimizzare questo utilizzare microfoni di prossimità per avere il più alto rapporto segnale diretto/rientro, che è una sorta di regola 3:1 verso i microfoni in cui rientra (uno strumento un microfono). In ogni caso e soprattutto per ottimizzare riprese a distanza, esempio riprese di ogni sezione con un microfono a sezione, l’approccio più qualitativo è quello di utilizzare un espander/gate tarato per aprire il microfono solo quando suona la sezione dedicata o per minimizzare l’effetto del rientro degli altri strumenti. L’operazione di ritardare i microfoni in una situazione cosi piena di rientri non è percorribile se non quando si utilizzano dei microfoni a distanza che riprendono l’insieme generale dell’orchestra e quindi il ritardo tra microfono dedicato per la sezione e microfono a distanza è ottimizzabile ritardando opportunamente come media in quanto che avranno comunque posizioni differenti i microfoni delle sezioni in base al loro posizionamento ma faranno riferimento in questo caso ad un solo percorso di ritardo che è quello del microfonaggio a distanza.
I Trigger vanno sempre sincronizzati a priori con l’eventuale microfono se presente sul tamburo o cassa di riferimento. Anche i Pad sincronizzati generalmente con il Rullante.
Ci possono poi essere dei casi in cui la sezione è molto grande e necessità di più di un microfono, ma come precedentemente detto e che vale anche nel caso di Cori ottimizzare la microfonazione secondo la regola del 3:1 modificata.
In un contesto Live con Batteria Acustica in cui ci sono Over Head panoramici, come spiegato nell’articolo allegato sarà necessario ottimizzare il ritardo dei microfoni di Prossimità con quelli Panoramici.
Per questo se non si ha la possibilità per via dei limiti sui dispositivi utilizzati (mixer audio e/o processori) conviene spesso non utilizzare i microfoni panoramici ma effettuare esclusivamente riprese di prossimità.
Microfonazione Panoramica Batteria Acustica
Se si vanno ad aggiungere sorgenti temporalmente ritardate (rispetto a delle sorgenti acustiche), come la presenza di Basi Musicali il cui segnale passa da PC con ritardo temporale dato dal driver utilizzato, anche qui è da valutare la differenza di ritardo tra il segnale che arriva dalla Base Musicale e quello diretto dagli strumenti che a loro volta potrebbero essere ritardati e quindi avere un esecuzione temporale diversa (più ritardata) rispetto a quella data dal musicista.
Anche per strumenti in D.I. e con multi-microfonazione o mix di questi è necessario considerare i ritardi da applicare in relazione al resto degli strumenti.
Come linea generale lo strumento che ha più ritardo è quello a cui il tutto va sincronizzato.
Può essere utile registrare una prova audio con tutti gli strumenti per visualizzare le tracce e tarare con più calma e precisione tutte le linee audio, oppure utilizzare software in tempo reale di comparazione forma d’onda come il Waves InPhase.
Nel caso poi durante il processo di correzione temporale si riscontra un segnale di maggiore ritardo allora sarà da offsettare tutto il precedente lavoro per sincronizzarlo con quello. Ma generalmente Over Head e Tracce Audio da PC sono quelle con il maggiore ritardo.
In caso di utilizzo di software per comparazione temporale linee microfoniche (generalmente 2 alla volta) oltre alla linea stessa da monitorare scegliere sempre come seconda linea una linea già ottimizzata che come anticipato il riferimento temporale sarà quello degli Over Head o Basi Musicali.
n.b. Non è detto che gli Over Head siano allo stesso tempo di ritardo in quanto possono avere posizioni ed altezze diverse secondo la tecnica utilizzata. Nel caso optare sempre per sincronizzare con il microfono con maggiore ritardo.
E’ importante anche la gestione del ritardo stesso, mentre in Studio è possibile mettere tutto in fase Post Recording attraverso lo spostamento temporale delle tracce audio, nei Live il ritorno dei monitor è fondamentale per la corretta performance del musicista e per cui eccessivi ritardi possono essere percepiti come eco, o come un ritardo troppo grande da non permettere una corretta esecuzione dello strumento. Per questo è sempre bene essere limitati entro i 4-5 ms di ritardo in medio-alta frequenza comprensivo anche del ritardo dato dal percorso di segnale dalla ripresa microfonica, al suo processamento e ritorno sul monitor.
OTTIMIZZAZIONE DELLA PERCEZIONE, CHIAREZZA e PRESENZA
Ottimizzazione della Fase e Disposizione dell’Impianto Audio
Prima di procedere ad un qualsiasi mix, con aiuto da parte del P.A. Manager è importante testare la polarità e fase dell’impianto audio, inviando un segnale mono e ascoltando (anche tramite analizzatore di spettro) se il segnale è percepito perfettamente in centro o ci sono spostamenti dell’immagine. Lo stesso per la fase facendo suonare uno strumento che lavora in bassa frequenza (es. basso elettrico), invertendo poi la fase si deve percepire uno sfasamento, se il contrario allora la partenza è in controfase, quindi da correggere.
Non è necessario che sia in controfase ma bastano anche piccole variazioni di fase per percepire un degrado della presenza in bassa frequenza.
Gestione del Livello e Regola dei 3 Strumenti
Vista la capacità del nostro apparato uditivo di focalizzare un massimo di 3 strumenti di cui principalmente 1 è percepito a fuoco e gli altri più in secondo piano, è utile durante il mix far risaltare alternativamente i vari strumenti, prendendo sempre come riferimento per il livello massimo la voce o strumento in solo. L’ottimizzazione di questa tecnica avviene attraverso un’attenuazione degli strumenti rispetto a quello da focalizzare (subtractive mixing). Questo è utile farlo non casualmente per ovviare ad un effetto ping pong o vicino-lontano che si verrebbe a creare, ma in presenza di cambi di ritmo ed accenti da parte dello strumento stesso da focalizzare.
n.b. In un contesto live questo può risultare abbastanza difficoltoso per cui è possibile aumentare lo strumento da far risaltare, facendo sempre attenzione a non superare mai oltre 3 – 4 dB, o utilizzare gruppi e DCA per una maggiore facilità di gestione dei vari canali.
Quando si enfatizza o attenua il livello di segnale di uno strumento ma anche mix, è importante che questo venga eseguito piano piano senza essere bruschi e decisi nel movimento, in quanto veloci cambi di livello di pressione sonora sono maggiormente percepibili e quindi disturbanti, mentre se si è dolci e con piccoli step l’incremento percepito è più naturale. Il segreto è non far percepire in modo diretto dell’avvenuto processamento, e questa è una teoria che vale per un qualsiasi processamento del segnale audio.
Tenere la voce ed assoli a più alto livello rispetto ad un tappeto sonoro rappresentato dagli altri strumenti oltre l’utilizzo della tecnica dei 3 strumenti, favorisce l’attenzione verso appunto il cantato e l’esecuzione strumentale, in quanto che il nostro sistema uditivo tende a concentrarsi sempre di più verso sorgenti con volumi più alti.
Il nostro sistema uditivo è in grado di separare e focalizzare strumenti con un rapporto segnale-rumore di circa 15 dB, più il mix è bilanciato su di un piano 360° e più ci si avvicina in alcuni casi supera questo valore, mentre mixare in mono affatica e riduce al minimo le capacità di focalizzazione. Per questo è sempre bene mixare almeno in stereo.
Per allontanare uno strumento rispetto ad altri è possibile anche attenuare le alte e medio-alte frequenze, simulando l’attenuazione naturale dell’aria e dando una percezione di suono più lontano.
Per aumentare la sensazione di Loudness è utile utilizzare un processamento di equalizzazione dinamica multibanda, cosi da lavorare sul Loudness Parziale ed enfatizzando porzioni di banda si va a percepire un incremento di Loudness (in quanto siamo più sensibili agli incrementi di sensibilità), sostenuto dal livello di compressione. Questo è un processo migliore rispetto ad equalizzare in boost in quanto che semplicemente equalizzando in boost ci si avvicina maggiormente al livello di distorsione in/out, si incrementano le distorsioni armoniche per amplificazione ed è meno preciso a livello di ascolto in quanto è più facile percepire quello che eccede e poi attenuare che il contrario.
Aumentare il livello di segnale in uscita insieme a lavorare dinamicamente sul segnale audio generale o singolo dello strumento, può portare ad una compensazione del mancato loudness per sottrazione.
Equalizzare porta a sua volta una sensazione di incremento del Loudness Parziale (in misura inferiore rispetto al processamento dinamico).
Nel caso di mixaggio in surround od in cui il suono proviene dal dietro, è molto probabile che il tipo di equalizzazione e processamento dinamico sia differente da quello come se il suono provenisse dal fronte, in quanto che diverso è il rapporto ambientale e diversa è la percezione (più scura, meno armonica, meno localizzata e focalizzata).
Utilizzare diffusori per la riproduzione delle basse frequenze in modalità stereo o multicanale è sempre consigliato in quanto che oltre a migliorare la percezione delle stesse per ITD, consentono anche di ridurre i fenomeni modali presenti all’interno dell’ambiente (fasi e controfasi o ventri e nodi creati per interferenza di queste frequenze dirette con quelle riflesse dall’ambiente).
Evitare di utilizzare Cappelli con visiera ed altri oggetti in testa in quanto si altera la risposta percepita. Il cappellino con visiera creare un Notch Filter a 2 Khz.
Un ottimo aiuto alla percezione dei suoni è la vista, attraverso Meter come RTA è possibile visualizzare in tempo reale l’andamento dello spettro dello strumento o mix e valutarne più finemente possibili correzioni. Attraverso invece lo Spettrogramma è più facile rilevare fondamentali ed armoniche, non che rumori e risonanze sempre con lo scopo di processarle più precisamente possibile.
Per quanto riguarda l’ascolto per musicisti attraverso monitor di palco, ma ancor più in-ear monitor, evitare di enfatizzare troppo il riverbero in quanto che il musicista può facilmente essere distratto dall’effetto quando invece il livello di segnale più presente e chiaro deve sempre essere il suo, in tappeto ma correttamente bilanciati il resto degli strumenti da lui richiesti. Seguire soli e tecniche di mixaggio aiutano a migliorare la percezione del mix. In caso di monitoraggio in stereo utilizzare le tecniche viste per il mixaggio solo seguendo il punto di vista del musicista che generalmente è l’inverso di quello del fonico di sala.
Per un fonico di palco è poi buona norma ascoltare ripetutamente tramite cuffie o monitor (meglio nello stesso formato di ascolto del musicista, in quanto a volte può essere anche 3D), il solo del monitor dei musicisti per capire se va tutto bene o ci sono correzioni da fare.
Sempre per un monitoraggio stereo ma anche 3D, è utile mixare ricreando l’immagine sonora di posizionamento degli strumenti cosi come la si vede e sente il musicista, focalizzando il suo strumento centralmente (per una maggiore concentrazione) mentre nello spazio tutti gli altri (minimizzando così il disturbo che ci sarebbe se tutti gli strumenti fossero in mono e migliorando anche la focalizzazione e chiarezza di ognuno).
È possibile aumentare l’estensione di un suono mono su di un piano orizzontale tramite l’utilizzo di Stereo Enancher, questo aiuta a creare un effetto più avvolgente e dimensionale ed in certi casi a migliorare la percezione e focalizzazione di altri strumenti mono.
In alternativa è possibile farlo manualmente, sdoppiando il segnale mono, pannando poi i due segnali uno opposto all’altro e ritardare il segnale sdoppiato secondo quantità ricercate al fine di allargare e stringere l’immagine.
La regola dei tre strumenti è importante anche per minimizzare l’effetto precedenza in cui se un suono soprattutto di frequenza vicina arriva con leggero ritardo viene mascherato, mentre se di differente volume è possibile che sia maggiormente percepibile.
Subtractive Mixing
Lavorare in sottrazione tramite Subtractive Gain e Subtractive Fader che vedremo meglio quando parleremo di Mixaggio.
L’orecchio è più sensibile ed attratto (quindi portato a mixare e processare) dalle variazioni positive (in amplificazione), ma questo oltre che produrre un maggiore rumore e distorsione sul segnale audio, in quanto come già precedentemente detto amplificare porta anche ad un aumento dei valori di distorsione armonici e dell’onda stessa amplificata, porta quanto prima ad un livello massimo del segnale prima della distorsione, mentre più ne siamo lontani e più pulizia avrà il segnale audio cercando di mediare come riferimento a 0 dB il livello di segnale massimo ottimale. Al contrario più attenuiamo e più ci avviciniamo al rumore di fondo.
Per il principio psicoacustico per cui un suono più forte è percepito più chiaro e presente di un suono più debole, attenuando il livello di alcuni segnali oltre alla possibilità di farne risaltare altri, permette di risparmiare energia ed eventualmente poter aumentare il livello generale del mix.
È anche uno dei motivi per cui si preferisce ed è più qualitativo oltre che più preciso in fase di equalizzazione di uno strumento musicale, percepire quali sono le frequenze che eccedono per poi attenuarle. Lavorare quindi in Sottrazione e non in Boost. È importante agire finemente (magari utilizzando un equalizzatore Peaking o Digitale, comunque con campanatura variabile) sulle frequenze che disturbano per essere precisi cercando di attenuare solo la parte interferente e ridurre al minimo la percezione di calo del Loudness.
Utilizzare eventualmente (rispettando sempre la dinamica dello strumento), un processore di dinamica per recuperare parte del loudness percepito perso, e insieme od in alternativa regolare in amplificazione il guadagno del pre-amplificatore, fino a percepire un segnale pieno e chiaro, nonostante si sia agito in sottrazione per eliminare eventuali disturbi, risonanze, colorazioni del suono eccessive. Durante l’equalizzazione è importante bypassare e attivare l’equalizzatore dopo un lungo periodo di ascolto per ottenere un giudizio più oggettivo sulla percezione del loudness dello strumento o mix, al fine di determinare quale preferito.
Per ridurre le sibilanti, oltre che l’utilizzo di de-esser può essere valutabile l’inserimento di un Equalizzatore in Sidechain ad un compressore (che è il principio su cui si basano la maggior parte dei de-esser), tale da enfatizzare all’interno della sezione di Controllo le frequenze desiderate (quindi anche plosive ed altre risonanze) ottenendo così un’attenuazione più mirata verso questo range di frequenze. Un’altra alternativa può essere il controllo attraverso un compressore multibanda (più efficiente e trasparente rispetto alla soluzione precedente) o ancor più attraverso l’utilizzo di un Equalizzatore Dinamico.
Per ottimizzare la presenza e chiarezza della Voce può essere utile ridurre le fondamentali di questo strumento sugli altri in esecuzione, cosi da mascherarne meno il suo livello. In opposto effettuare se possibile una più schiacciata ed elevata compressione per far risaltare anche il contributo armonico e le basse parti dinamiche che possono facilmente essere coperte da strumenti percussivi e distorti.
Quando c’è un Assolo è importante che questo sia chiaro e presente, allo stesso livello della Voce e mai sotto o superiore al livello medio tenuto, la Voce poi in ogni caso deve essere sempre quella di maggiore rilevanza e presenza in quanto che l’ascolto è rivolto sempre su di essa, dando così meno fatica e stress di ascolto.
La base corretta per un mix pulito su cui poi si applica la tecnica dei 3 strumenti per aumentare il livello di percezione di tutto l’insieme strumentale, è sempre quella di a parte la Voce ed Assoli che devono sempre essere padroni, livellare il più possibile su di un piano di correlazione, in fase, ben accoppiati, in cui nessuno strumento maschera l’altro ma anzi enfatizza la percezione di entrambi facendo attenzione ai battimenti e bande critiche, migliorando l’accoppiamento e minimizzando cosi la distrazione.
Se si comprime troppo (soprattutto utilizzando compressori di scarsa qualità) e quindi poi si riguadagna per riportare il livello a regime, si generà un incremento delle alte frequenze percepite (in quanto vengono enfatizzate le armoniche) e schiacciamento dinamico in bassa (in quanto compresso), fare per cui attenzione a questi range di frequenze in caso di compressioni importanti.
Armoniche e Risonanze
Le risonanze sono parte di suono che mascherano e disturbano l’ascolto, di norma un palco (legno e similari) e soprattutto se non correttamente costruito per minimizzare le risonanze, tende a risuonare su di un range di frequenze 100 – 250 Hz dipendente dalle dimensioni e struttura (più grande ed elastico più bassa sarà la frequenza di risonanza, al contrario più piccolo è “tipo palchetti per batteria” e più alta sarà). Questo è maggiormente presente in caso di utilizzo di monitor da palco a diretto contatto con il palco stesso e Sub appoggiati sopra al palco.
n.b. È quindi fondamentale nella taratura dell’impianto audio considerare anche l’emissione sonora dai monitor che incide sulle risonanze del palco.
n.b. Per palchi in cemento e similari le risonanze sono più concentrare per prime riflessioni sulle medie e medio-alte frequenze.
Dal punto di vista del microfonaggio è bene mantenere una corretta distanza (altezza) dal palco, minimo 40 – 50 cm e con un elevato rapporto tra la distanza di ripresa dello strumento e quella rispetto al palco < 1:30, in caso non si riesca come ad esempio nel microfonaggio di una grancassa da batteria posta generalmente direttamente sul palco o palchetto sarà fondamentale agire con una corretta equalizzazione.
Le risonanze ambientali sono da controllare tramite appositi elementi assorbenti ed isolanti, come linea guida è bene trovarsi il più lontano possibile dal campo riverberante, ed in caso utilizzare wind-filter per minimizzare i rientri delle riflessioni, soprattutto le prime, e facendo attenzione in fase di equalizzazione alle frequenze medio-alte che sono le prime a risuonare per prime riflessioni.
È utile in ogni caso filtrare con passa-alto le frequenze basse e medio-basse non riproducibili dallo strumento o in generale le sub-armoniche non desiderate che creano disturbo e risonanze.
n.b. Tutti gli strumenti presentano un più o meno contributo energetico sub-armonico, utile ad esempio per aumentare la profondità e corpo dello strumento, ma che in certi casi invece portano solo risonanze e mascheramenti di altri suoni.
Le armoniche superiori soprattutto le prime, contribuiscono in maggiore misura a definire la naturalezza dello strumento (le sub-armoniche sono generalmente di ben più basso livello di intensità), per questo è sempre bene ottimizzare anche la loro presenza. Da non confondere con le armoniche di risonanza (un eccessivo valore energetico delle armoniche naturali) e armoniche per distorsione, entrambe da controllare attraverso i processi (ripresa-dinamica-equalizzazione).
Armoniche della voce che creano molto disturbo/fastidio all’ascolto in quanto spesso risonanti sono quelle da 1 Khz a 4 Khz (risonanze condotto uditivo e tendenzialmente microfoni dinamici). Altre risonanze da tenere in considerazione sulla voce sono quelle da 150 Hz a 250 Hz in cui rientri, risonanze del palco e possibili risonanze microfono dinamico ne fanno parte.
La posizione della sorgente determina una variazione del timbro sonoro percepito e quindi chiarezza e presenza. In una situazione standard con il suono provenire dal fronte è fondamentale il controllo delle frequenze di 2 – 3 – 4 Khz che sono le più risonanti. In una situazione con il suono provenire da dietro o per via riflessa (es. all’interno di un ambiente molto riflettente) è importante controllare anche la frequenza di 1 Khz che è quella di maggiore risonanza quando il suono proviene da dietro, valutare l’attenuazione data in alta frequenza per il suono che proviene da dietro. Quando il suono proviene dall’alto (sempre per gli stessi possibili motivi) è necessario controllare anche i 7 Khz che sono la frequenza di maggiore risonanza, (valutare il comb filter creato sopra ai 4 Khz per via delle riflessioni dovute dalla testa, spalle e corpo che incidono sulla risposta in frequenza percepita per suoni provenienti dall’alto).
n.b. Per un ascolto binaurale valgono le sole regole di ascolto frontale, con minore risalto delle frequenze di 2 – 3 – 4 Khz come sopra elencato in quando non c’è la presenza di testa e corpo.
Quando si ascolta tramite in Ear-Monitor (ascolto binaurale) è facile che vi siano maggiori risonanze in medio-alta ed alta frequenza per via della radiazione diretta verso il condotto uditivo, è opportuno quindi utilizzare cuffie opportunamente equalizzate e monitorare la gestione di queste frequenze.
Con Padiglioni Auricolari esterni queste risonanze sono più contenute ma aumentano le distorsioni armoniche per via del contatto diretto con il padiglione auricolare dell’orecchio, in questo caso il maggiore controllo deve essere eseguito sulla parte media e medio-alta.
In un ascolto Binaurale non ci sono riflessioni, rifrazione e diffrazioni ambientali, per cui pur essendo molto più definiti in quanto la sorgente è a diretto contatto con le orecchie, è necessario ponderarli opportunamente (attenzione alla chiarezza e livello).
BATTIMENTI E MASCHERAMENTI
Per ovviare a possibili battimenti e mascheramenti per suoni con simile o identico spettro in frequenza è utile pannare adeguatamente questi in modo da dare una maggiore estensione e quindi percezione, prima mascherata nel caso siano tutti in mono.
Anche la tecnica di miglioramento della percezione prima vista consente di abbassare il livello di battimento e mascheramento.
È importante che il livello della voce ed assoli non sia troppo elevato tale da mascherare sempre più il resto degli strumenti.
Tendenzialmente un livello di segnale più alto tende a mascherare in primis le armoniche e frequenze alte, tanto è più alto e tanto più range di frequenza tenderà a mascherare. Anche un eccessivo livello di basse frequenze porta allo stesso problema.
Per quanto riguarda i battimenti, ottimizzando il mascheramento e la banda critica degli strumenti già si risolvono molti problemi, l’aspetto da tenere conto per un ulteriore gradino di qualità è quello di utilizzare strumentazione più qualitativa possibile, anche un’eccessiva distorsione armonica della strumentazione audio può portare alla percezione di battimenti.
Anche la frequenza di crossover e pendenza di taglio incidono sulla qualità del suono. Se lungo la catena audio ci sono ripetuti tagli alla stessa frequenza soprattutto per processamenti non a fase lineare, si generano piccole oscillazioni che generano fenomeni di battimento e mascheramento. Evitare per cui di tagliare lo strumento musicale alla stessa frequenza di taglio più volte (quindi non tagliare ad esempio in gruppi canale).
GESTIONE DELLE BANDE CRITICHE
Attraverso l’analisi della risposta in frequenza temporale dello strumento, è possibile definire la Banda Critica ed ottimizzare il processo di mixaggio tramite equalizzazione e controllo dinamico.
La frequenza limite per cui la percezione rimane costante dipende dal suo livello di pressione sonora, come da foto:
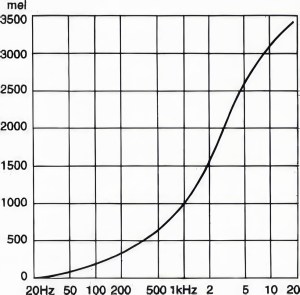
Più è alto il livello di pressione sonora e più questo effetto è presente sopra i 150 Hz (aumenta il livello di intensità sonora percepito) mentre rimane invariato sotto.
Sarà quindi importante ridurre la banda critica tramite processo o di equalizzazione e/o dinamica al fine di far rientrare la percezione degli strumenti musicali entro la banda critica. Cioè lo strumento che suona più forte nella stessa banda di frequenze di un altro sarà tanto più mascherante quanto più alto è il suo livello di pressione sonora in quel range di frequenze.
Esempio:
Attenuare 100 Hz – 120 Hz sulla Grancassa e lasciarli al Basso oltre che far risaltare meglio il Basso come visto per le tecniche di miglioramento chiarezza e presenza al fine di ovviare a possibili mascheramenti, anche per evitare sbalzi di pressione “percezione” quando suonano sulla stessa nota, rendendo entrambi più intellegibili (da valutare caso per caso secondo la risposta dello strumento stesso).
OTTIMIZZAZIONE DELLA FOCALIZZAZIONE – LOCALIZZAZIONE
La vista è il senso prioritario per il nostro cervello ed è in grado di far modificare la percezione di un suono, per questo ottimizzare la localizzazione e focalizzazione di una sorgente sonora è fondamentale per ottenere un suono di qualità soprattutto quando questo viene visto.
n.b. Il nostro cervello prende per vero solo ciò che vede, che pensiamo sia vero o probabile, mentre tralascia ciò che pensiamo sia non veritiero, impossibile.
Per ottimizzare la percezione di provenienza delle basse frequenze (legate quindi alla posizione dello strumento) è utile spostarle su assi temporali differenti, in quanto che la percezione di provenienza in bassa frequenza è maggiormente legata all’ITD (differenze di livello temporale). Un esempio può essere quello di ritardare leggermente la cassa della batteria rispetto al basso elettrico o contrabbasso senza snaturare il mix, cosi da separare in un ascolto “ad esempio stereo” i due segnali quindi tempi di arrivo alle nostre orecchie.
In generale la localizzazione per ITD avviene sotto a 1 Khz, mentre sopra ai 4 Khz il nostro udito lavora per ILD.
Per frequenze intermedie (in cui ci sono molte fondamentali ed armoniche strumentali) è possibile che si verifichino degli errori di localizzazione come visto in argomento Psicoacustica, risolvibili in parte attenuando leggermente entro i 0,5 – 1 dB (per non essere percepito come attenuazione di volume) o enfatizzando il pannaggio (a scapito di uno spostamento dell’immagine).
Questo non risolve il problema ma distrae meno dalla localizzazione di tutto il resto della banda di frequenze.
L’effetto del pannaggio ha valore se > 1 – 2° per il piano orizzontale, in quanto che questa è la minima risoluzione di percezione delle nostre orecchie.
Altezza Sorgente Sonora
In fase di progettazione di un sistema audio l’altezza dell’impianto audio andrebbe sempre considerando l’asse del diffusore a non più di 10° sopra o sotto le orecchie dell’ascoltatore, in quanto che oltre i 10° si comincia a percepire un innalzamento del suono verso l’alto e varia la risposta in frequenza percepita (questo aspetto del posizionamento è dipendente anche dal grado di direttività polare del diffusore audio stesso).
Oltre a questo c’è anche la presenza del musicista quindi a che altezza si trova a suonare lo strumento rispetto a noi che lo ascoltiamo. Più è alto e più il nostro apparato uditivo accetta di sentire un suono che tendenzialmente arriva un po’ più scuro (per avere una percezione naturale).
Diciamo che di norma è utile considerare che se la sorgente è alla stessa altezza del ricettore il diffusore audio non deve essere sopra ai 10° di ascolto verticale, se la sorgente è più in alto la distanza in altezza sorgente/ricettore può essere aggiunta ai 10° limiti visti precedentemente.
In ogni caso in aiuto viene comunque l’effetto ventriloquo che limita la percezione e localizzazione anche sul piano verticale oltre che orizzontale.
Se si rimane all’interno di questa regola è minimizzato anche il problema della risposta in frequenza percepita per un suono provenire dall’alto in quanto rimane sempre all’interno di un ascolto frontale. Da considerare poi le intemperie atmosferiche e la non linearità dell’aria.
In un ambiente riverberante è ancora più importante il rispetto di tutti questi fattori in cui focalizzazione e localizzazione sono maggiormente distorti.
Se l’ascolto è molto vicino con sorgente ed impianto audio ben oltre ai 10° è possibile al fine di ridurre l’effetto di ascolto sfocato, inserire dei Front Fill di prossimità per ribilanciarne l’ascolto ma da considerare in un progetto di varianza minima per gli effetti di interferenza che potrebbe portare verso il resto del sistema P.A.
Gestione dell’immagine considerando un ascolto L – R
La posizione ottimale dei diffusori acustici è sempre sulla stessa linea orizzontale e verticale in cui si trova la/le sorgenti.
Per un ascolto stereo è importante considerare il posizionamento come da teoria:
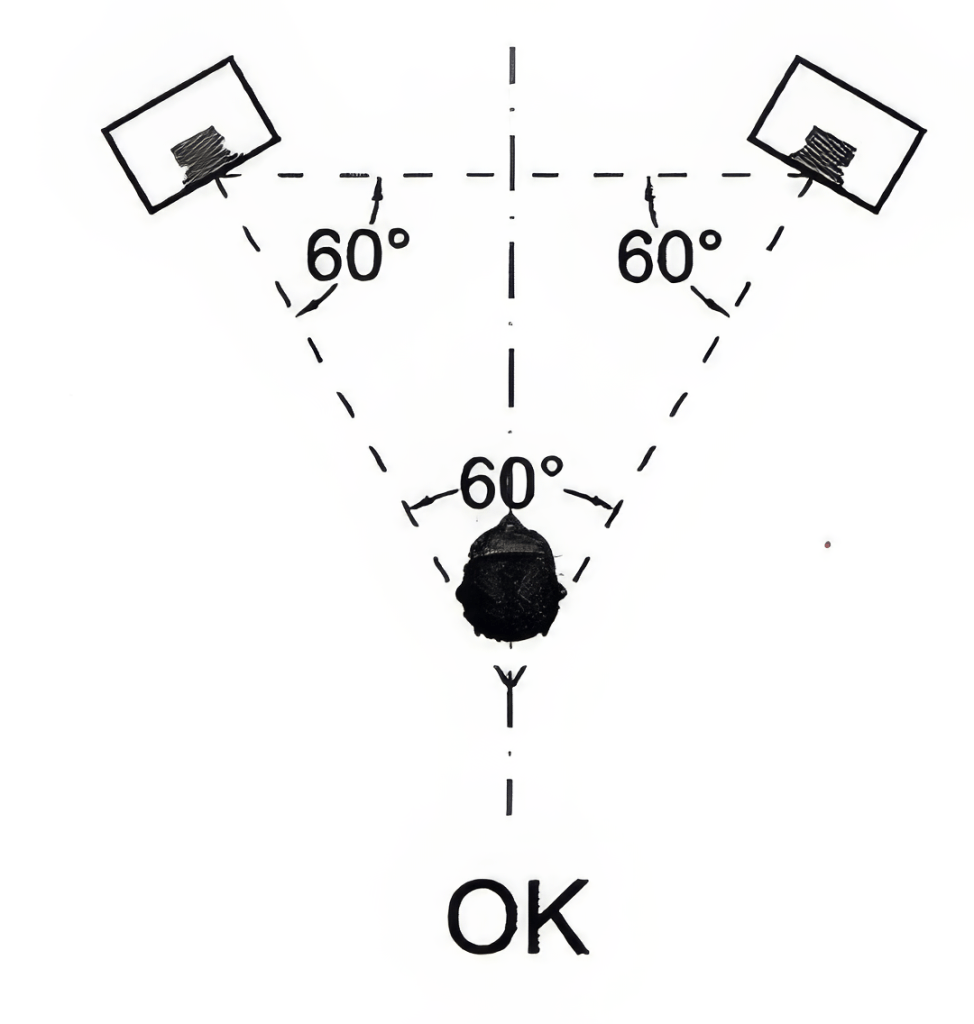
Tanto più ci si trova lontani o si avvicinano le sorgenti (rispetto ad un ipotetico ascolto stereofonico) e tanto più i valori di ILD e ITD dovranno essere elevati per ottenere uno spostamento dell’immagine. Frequenze più basse necessitano di valori più elevati.
Se l’ascolto è maggiormente concentrato vicino alle sorgenti audio è possibile prevedere una riduzione dell’estensione dell’immagine stereo, mentre al contrario se è molto lontana un aumento dell’estensione dell’immagine stereo.
Stereofonia Discreta: Realizzata tramite tecniche di ripresa stereofoniche e correttamente bilanciate nello spazio L-R.
Stereofonia non-Discreta: Realizzata bilanciando gli strumenti con ripresa mono in un piano L-R.
Per aumentare il senso di profondità e realismo di un mix è possibile aggiungere riverberazione e delay.
Per ascolti di prossimità, esempio come spesso accade in piccoli ambienti ma anche in grandi eventi ma con ricettori in prossimità del palco, è molto importate visto l’estrema vicinanza dell’ascolto ai sistemi di diffusione sonora che creano un elevato livello di distorsione di localizzazione e focalizzazione, cercare di mixare il più possibile il suono naturale dello strumento con un minimo di contributo dai diffusori esterni e che questo sia mascherato, quindi non sia chiara e definita la sua provenienza dai diffusori, questo si ottiene mixando adeguatamente il suono diretto degli strumento con quello amplificato (monitor da palco compresi) e bilanciando correttamente fase e tempo di ritardo tra i vari sistemi dell’impianto audio.
Frequenze percepite omnidirezionali avranno sempre meno valore nell’errore di localizzazione e focalizzazione, in quanto non è definita la loro provenienza, ed è questo l’unico contesto in cui è giusto mediare l’ottimizzazione della localizzazione in bassa frequenza con la sua omnidirezionalità.
Tipologie di Localizzazione e Focalizzazione in un Evento Live

Ottimizzazione della Localizzazione-Focalizzazione su di un piano Orizzontale
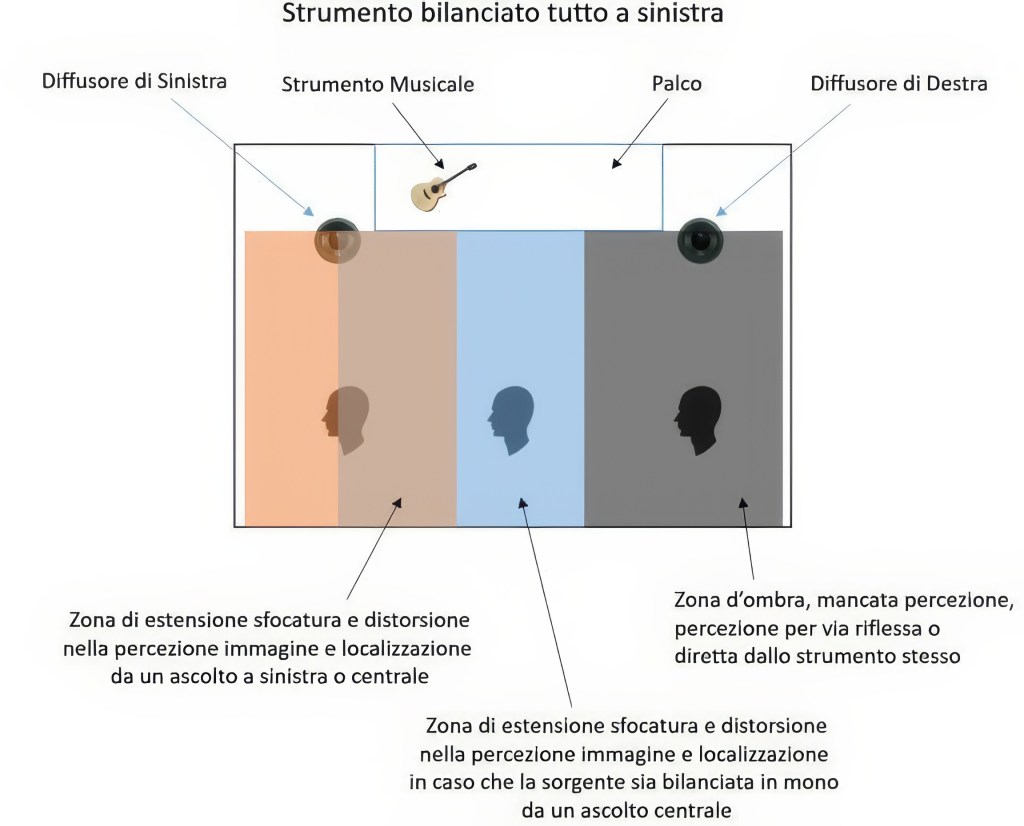
Se panno uno strumento tutto a sinistra o destra si ottiene un risultato come da figura sopra in cui massime sono le zone d’ombra per chi ascolta dal lato opposto.
Lavorare con la Tecnica Ventriloquo per cui la localizzazione segue sempre la vista è la migliore soluzione, (la presenza visiva di una sorgente centrale ma con il suono che proviene da un lato sarà percepita dal nostro cervello come provenire dal centro, ma tanto più questo suono è sfasato rispetto alla posizione fisica reale dello strumento visto e tanto maggiore è lo sfocamento acustico percepito dello stesso).
Considerando che 20 dB sono il limite massimo medio per spostare una sorgente ad essere percepita da un lato e che a livello visivo questo valore si riduce di circa la metà. Considerando anche che a parità di distanza tra i diffusori acustici più ci allontaniamo e più servirà guadagno per lo spostamento dell’immagine in quanto l’angolo si va via via a ridurre, considerando anche di creare una zona d’ombra più piccola possibile, è opportuno per ottimizzare la localizzazione e focalizzazione non spostare la sorgente rispetto alla percezione mono media di circa 4 – 5 dB, di cui 3 – 4 dB per ascolti ravvicinati e 5 – 6 dB per ascolti lontani.
I risultati di questa tecnica sono nella figura sottostante in cui le zone di sfocamento nella percezione dell’immagine sonora sono molto più ridotte.
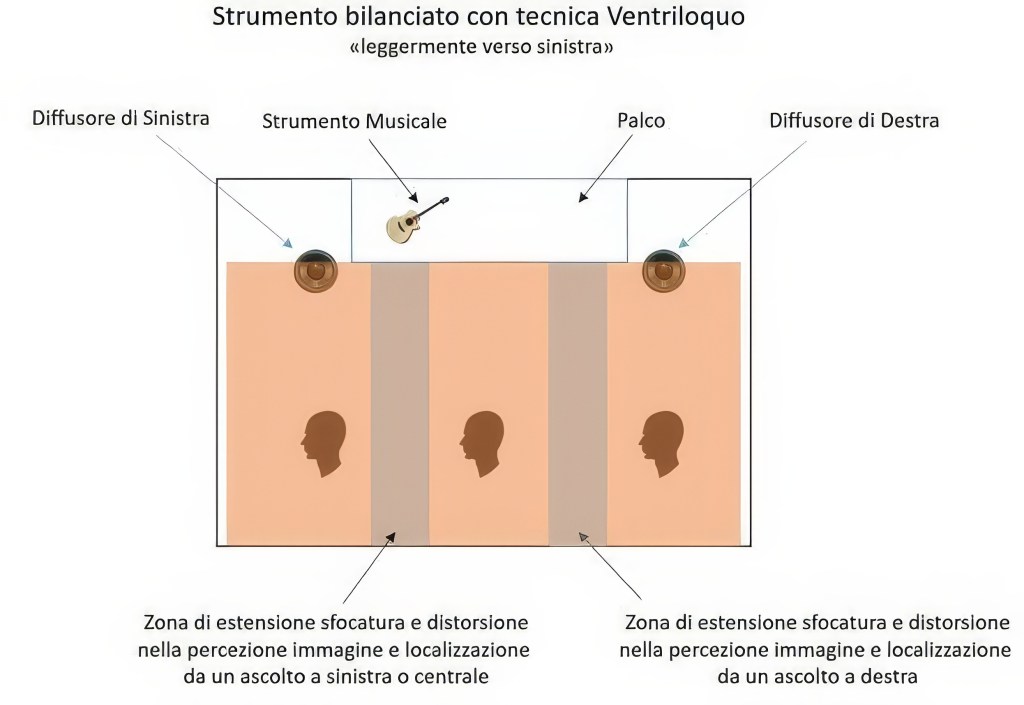
In caso di ripresa stereofonica discreta, l’immagine sonora dello strumento è già ben bilanciata dalla tecnica utilizzata. Nel caso in cui la stereofonia non sia discreta, quindi ad esempio pannare uno strumento con ripresa monofonica verso Left e Right ma anche Surround, si ottiene una percezione di sfasamento della corretta focalizzazione dello strumento tra le frequenze con lunghezza d’onda superiore alla distanza tra le orecchie, quindi quelle che verranno percepite centrali e le frequenze con lunghezza d’onda inferiore che verranno percepite spostate verso Left, Right o Surround in base a dove si panpotta lo strumento. Considerando che la nostra percezione alle frequenze con più piccola lunghezza d’onda rispetto alla distanza tra le orecchie avviene principalmente per differenza di ampiezza, mentre quelle con più grande lunghezza d’onda per differenza temporale, per ottimizzare la focalizzazione di uno strumento a larga banda può essere utile applicare un tempo di ritardo (delay) sulle frequenze con più grande lunghezza d’onda, tra il canale Left, Right e Surround, ritardando appunto il segnale che va al canale opposto a quello a cui mandiamo lo strumento, cosi che la nostra percezione si focalizza anche in questo caso sul segnale che arriva prima, riuscendo se pur meno efficacemente a percepire anche a più bassa frequenza uno spostamento dell’immagine.
In caso di presenza di Front Fill è opportuno per gli stessi motivi visti mantenere un corretto rapporto Left – Right come da figura sottostante:
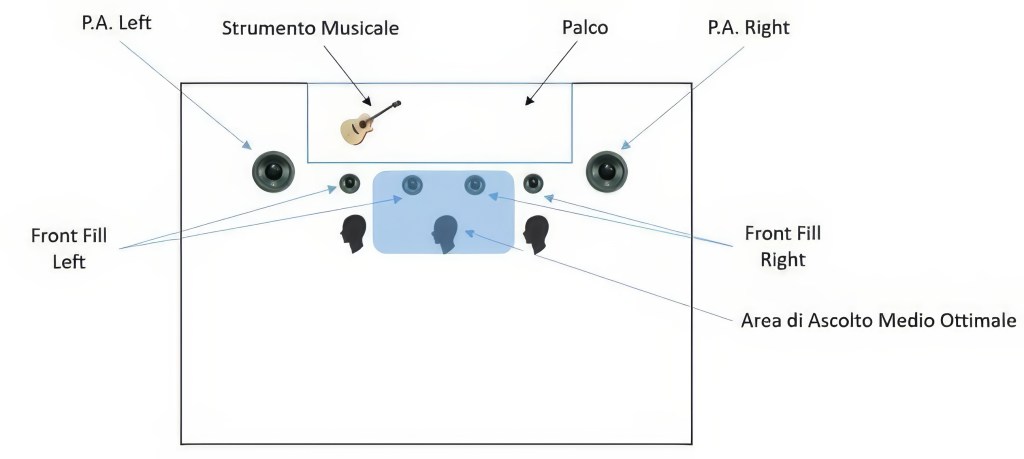
Questo a differenza di come sarebbe mettendoli in mono, consente di mantenere il giusto rapporto di localizzazione-focalizzazione anche per le prime file ravvicinate in prossimità del palco, laddove l’impianto P.A. fatica a determinare una copertura omogenea.
Una soluzione alternativa ancora più efficiente è quella di creare piccoli gruppi di ascolto L – R come da figura sottostante:
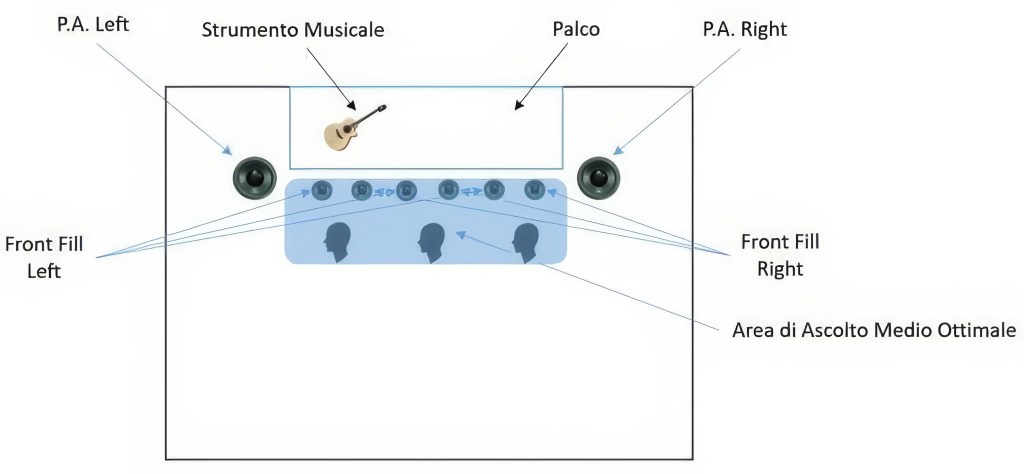
Così facendo ci sarà un ulteriore aiuto alla focalizzazione anche per gli estremi di ascolto, ma sempre limitati dal fatto che al massimo si percepirà un suono provenire leggermente da sinistra ma poi vedere che lo strumento musicale suona completamente a sinistra sul palco.
n.b. In caso di riproduzione di un brano musicale stereo, quindi già mixato in studio, considerare anche in questo caso che l’ascolto è in prossimità delle sorgenti, per cui valutare se stringere o allargare l’immagine stereofonica come visto precedentemente.
In caso di utilizzo impianto audio in configurazione sub a terra e satelliti appesi avviene uno sfasamento dell’immagine dello spettro, in cui i bassi percepiti a terra ed il resto della banda percepita verso l’alto, come da figura sottostante:
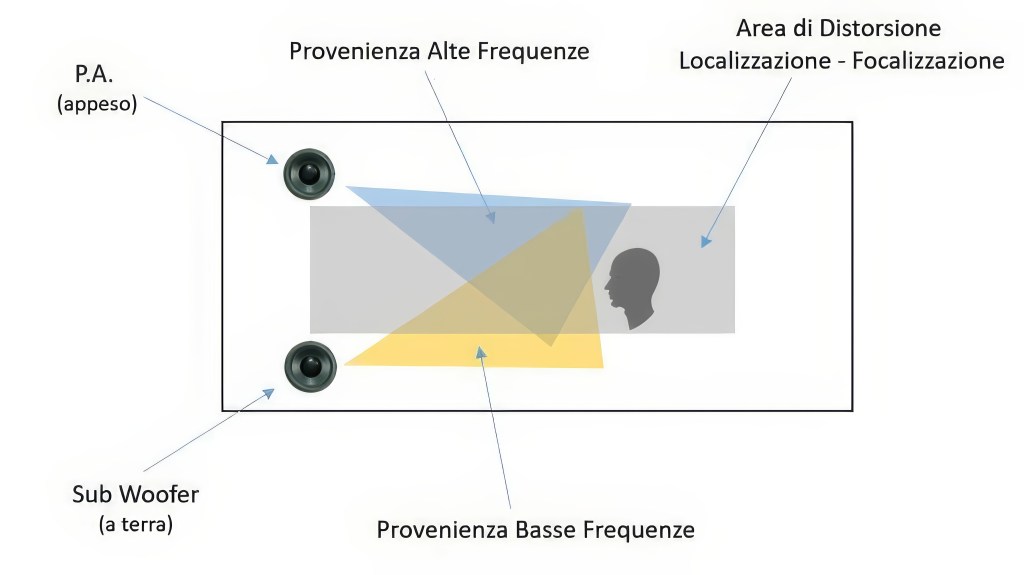
Questo problema è sempre risolvibile mantenendo il giusto angolo di altezza del diffusore appeso (< 10°) e corretto tempo di ritardo rispetto allo strumento musicale visto, oltre che utilizzare un tipo di configurazione con frequenze < 60 Hz a terra (in ogni caso non localizzabili) e > 60° appese cosi da ottimizzare anche la percezione di localizzazione e focalizzazione nelle frequenze basse, distorte invece nel caso precedente.
Questo è illustrato nella figura sottostante:
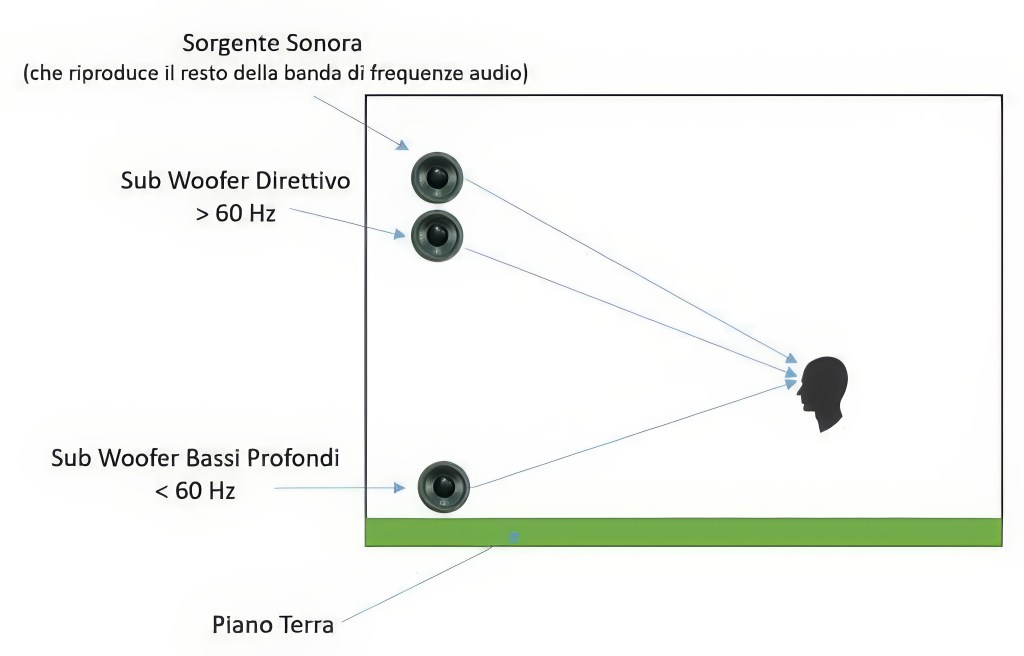
Anche i monitor da palco sono una fonte di disturbo non solo della risposta in frequenza e SPL per un ascolto in prossimità, ma anche di distorsione della corretta focalizzazione-localizzazione immagine. Questo è risolvibile utilizzando In-Ear monitor (monitoraggio in cuffia), cosi da eliminare tutto il contributo energetico ambientale generato dai monitor da palco, risolvendo anche altri molteplici problemi come ad esempio i rientri sui microfoni, la creazione di zone d’ombra di ascolto, più elevati rumori di fondo. In caso si richieda il suo utilizzo o questo sia l’unica soluzione possibile, utilizzare monitor più direttivi possibile ed equalizzarli opportunamente tale da generare il più basso livello SPL in arrivo alle prime file di ascolto. Sono in ogni caso fonte di risonanza da considerare durante la taratura dello spettro dell’impianto audio.
Impostare strumenti in stereo (ad esempio chitarre elettriche e voci) aumenta il livello di sfasamento di localizzazione e focalizzazione, per questo se non per scopi creativi o correttivi per migliorare l’intelligibilità del mix (utilizzare estensioni limitate) è sempre bene non utilizzarlo.
Per maggiori dettagli su come progettare un impianto audio P.A. per varianza minima, vedi articolo: System Designer – Line Array
OTTIMIZZAZIONE DELLA SENSAZIONE – ASCOLTO EMOZIONALE
Un cambio di equalizzazione durante un cambio di tonalità, velocità, o comunque variazioni del programma musicale, determina anche una minore percezione di variazione dell’equalizzazione.
Tramite ascolto in cuffia si perde la sensazione ed emozione di ascolto che c’è ascoltando attraverso diffusori acustici in quanto non vi è la presenza del corpo e testa. Per migliorare l’ascolto emozionale può essere utile in ogni caso aggiungere monitor di ascolto almeno in riproduzione della parte bassa dello spettro che è quella di maggiore interesse nel far lavorare testa e corpo avendo maggiore energia e lunghezze d’onda tali da non essere ostacolate dalla presenza fisica di chi ascolta. Da considerare poi il ritardo temporale tra un ascolto In-Ear monitor e tramite diffusori acustici, per cui è necessario ritardare temporalmente l’ascolto in In-Ear monitor per mettere tutto in fase.
Di seguito una tabella per la definizione della sensazione in base alla frequenza, rilevabile maggiormente per ascolto in campo libero, agire su questi range di frequenze per estendere ed ottimizzare la sensazione in quella parte del corpo facendo attenzione all’effetto di risalto sugli strumenti che riproducono quelle particolari frequenze:
|
Frequenza (Hz) |
Sensazione sul Corpo |
Definizione |
|
20 – 40 |
Corpo – Bacino Basso |
Basse Profonde |
|
40 – 160 |
Corpo – Bacino Alto |
Basse |
|
160 – 315 |
Bacino Alto – Gola |
Medio Basse |
|
315 – 2.500 |
Gola – Testa/Naso – Orecchie |
Medie |
|
2.500 – 5.000 |
Orecchie |
Medio Alte |
|
5000 – 10.000 |
Fronte |
Alte |
|
10.000 – 20.000 |
Fronte Superiore |
Altissime |
DINAMICHE ED IMPULSI
Variazioni dinamiche durante un cambio di tonalità, velocità, o comunque variazioni del programma musicale, determinano anche una minore percezione di introduzione del processamento.
Per brevi impulsi (pochi ms) il nostro apparato uditivo necessita di un differente livello di intensità sonora per percepirli in egual modo, fino ad un limite di 200 ms per cui oltre, l’orecchio medio tende a ridurre il livello di pressione sonora verso l’orecchio interno pareggiando il livello di intensità sonora percepita.
È quindi importante per dare presenza e dinamica agli strumenti considerare ed ottimizzare questi primi ms di inviluppo (generalmente legati all’attacco dello strumento).
Oltre i 200 ms non si hanno riferimenti per l’ottimizzazione del processo di controllo dinamico, in quanto diverse sono le variabili che portano all’alterazione dinamica vista, per questo è improbabile la necessita di impostare un attacco e rilascio di un processore dinamico oltre 200 ms (se non per la correzione di eventuali problemi di processamento.
Attraverso la compressione e guadagno post-compressione è possibile far risaltare armoniche e risonanze, i parametri di attacco e rilascio vanno bilanciati in base alla risposta armonica, in modo tale da rimanere al di fuori dell’attacco dello strumento e gestire il solo contributo armonico.
n.b. Un processore multibanda sicuramente viene maggiormente in aiuto per la gestione separata di attacco ed armoniche.
Attraverso la compressione/limitazione è poi possibile gestire picchi e sbalzi di tensione limitando i livelli di distorsione e dinamica.
Attraverso la Downward Compression (utilizzare il compressore come limitatore per ridurre l’estensione dei picchi) è possibile ridurre l’escursione dinamica (soprattutto i picchi) degli strumenti al fine di livellarne l’ascolto con il resto del mix, limitando mascheramenti e distrazioni di ascolto, utile toglierlo ad esempio quando interviene un assolo per lasciare l’escursione dinamica che necessita. Serve anche per limitare picchi che possono portare a livelli di distorsione.
Attraverso la Upward Compression (utilizzare il compressore per aumentare il livello dei più bassi valori energetici del segnale, utile per far risaltare armoniche, risonanze, contributi mascherati del segnale).
Lo stesso solo all’opposto vale per Downward Expansion (utile per attenuare rumori, rientri, suoni non utili e non desiderati nel mix), e Upward Expansion (per espandere la dinamica di strumenti e mix poveri di essa abbassando il livello dei più alti valori energetici del segnale).
Per Upward Processing attenzione oltre che alle risonanze anche alla generazione di sibilanti e suoni squillanti in quanto le armoniche come detto tendono a prendere valore energetico rilevante.
In un mix di ripresa di prossimità con microfoni dinamici più Over Head con microfoni a condensatore, come può essere ad esempio la ripresa di una batteria acustica, dopo opportuna messa in fase delle singole riprese microfoniche e corretto bilanciamento dei livelli di segnale delle singole riprese, questi se a condensatore, tendono a non rappresentare correttamente l’attacco di rientro degli strumenti percussivi, come ad esempio tom, rullante, timpano…, che si traduce nel mix in un indebolimento dell’attacco stesso ripreso dai microfonici dinamici di prossimità dedicati. Se si filtra escludendo le fondamentali dei singoli strumenti non c’è problema, ma se si prende anche la fondamentale allora è utile enfatizzare leggermente l’attacco del segnale ripreso dagli over head, per ottenere un recupero dei transienti ponderati dalla ripresa tramite microfoni a condensatore. La regolazione del livello di Preamplificazione e/o mix dei microfoni dinamici rispetto a quelli Over Head incide sulla percezione di più o meno ammorbidimento del transiente e quindi regolare di conseguenza l’eventuale enfasi prima definita.
Compressore prima o dopo l’equalizzatore?
Vedi articolo: Equalizzatori – XIX
OTTIMIZZAZIONE DEL LOUDNESS TRAMITE LUFS METER
Vedi argomento LUFS Meter
RIDUZIONE DEI RUMORI E PREVENZIONE
È molto importate che la massa e la corrente elettrica di alimentazione sul posto in cui ci si trova sia ben bilanciata, tale da trasferire correttamente tutte le interferenze a terra e garantire i livelli di corrente più stabili possibili per evitare riduzioni dinamiche del segnale, dc offset, distorsioni e rumori di fondo (soprattutto in dominio digitale ed attivo).
Utilizzare per cui distributori di corrente con filtri e tecnologie per pulire la corrente da rumori ed eventualmente ricrearla (qualsiasi sia il livello di tensione in ingresso “generalmente entro una certa soglia di tolleranza” viene assorbito e ricreato a livelli di tensione definiti dall’utente), questo per avere risultati ancora più qualitativi.
Per ridurre il rumore è inoltre molto importante rispettare soprattutto in ambito analogico le impedenze di carico tra i circuiti di ingresso e uscita.
Per prevenire sovraccarichi e rotture è bene utilizzare attrezzature con doppio PSU quando possibile, così da avere ridondanza sul circuito di alimentazione.
Per quanto riguarda la riduzione dei rumori da tracce audio, che siano analogiche, vecchie, da restaurare, vedi argomento Noise Reduction.
In un contesto Live ma anche Studio (digitale), prevedere ridondanze sul percorso di segnale quantomeno verso Finali di Potenza e P.A. cosi da evitare che l’evento o la sessione di registrazione salti per un problema tecnico all’attrezzatura, garantendo la corretta riuscita dell’evento.
AMBIENTE E POSIZIONAMENTO (EFFETTI)
Le riprese in Close Miking limitano la reale dinamica dello strumento percepita in quanto che sono prive di risonanze ambientali, per questo un corretto posizionamento di panoramici e tecniche di ripresa d’accento, a distanza, ambientali, sono spesso gradite soprattutto in generi musicali dove la dinamica è l’essenza del brano (vedi orchestre). In ogni caso l’aggiunta di riverberazione ed effetti può risultare più gradevole ed aiutare la dinamica percepita dello strumento.
In questo tipo di riprese fare attenzione all’effetto di prossimità che si viene a creare (basse e medio-basse frequenze), risolvibile quando possibile con microfoni dal diagramma polare omnidirezionale. Nei microfoni a condensatore per via del diverso principio di trasduzione il fenomeno è più contenuto.
Prendendo come esempio la Batteria Acustica l’utilizzo corretto di panoramici è fondamentale per aiutare il sostegno e quindi la parte centrale della dinamica dello strumento, naturalmente povero per una ripresa di prossimità. In questo caso però sarà poi necessario considerare fase e rientri in quanto che il suono dello strumento entra sia dal microfono a lui dedicato che dalla ripresa panoramica, come già visto precedentemente.
Nella creazione di un ambiente con l’utilizzo di effetti è importante per dare un senso di maggiore realismo non che migliorare la percezione, sia del suono diretto che quello ambientale, aumentare il grado di spazialità dell’effetto ed aggiungere un più o meno tempo di ritardo. Questo perché nella realtà il suono riverberato/eco non è presente insieme alla sorgente (cosa che avviene semplicemente aggiungendo ad esempio riverbero ad una voce) ma il suono diretto è seguito dopo x tempo dalle prime riflessioni e riflessioni successive che arrivano all’ascoltatore da diverse posizioni di riflessioni in base a come è la struttura dell’ambiente in cui si diffondono (quindi non è nemmeno sullo stesso fronte d’onda ma da diverse posizioni di ascolto), in questo caso uno Stereo Imager o Spaziale può aiutare.
Gestione del Riverbero. In realtà il riverbero non esiste, siamo noi che lo percepiamo cosi per via della bassa risoluzione del nostro sistema uditivo nel percepire e separare veloci transienti e suoni che arrivano a brevi distante l’uno dall’altro in cui si aggiungono mascheramenti e teoria degli impulsi. Per ottimizzare e ricreare la sua percezione naturale c’è da considerare che il suono diretto e le prime riflessioni sono le fondamentali e quelle maggiormente percepite nella definizione di localizzazione e focalizzazione dello strumento nell’ambiente, le riflessioni secondarie ed oltre determinano la percezione di profondità e grandezza.
Nella gestione del riverbero ed effetti è fondamentale in controllo delle risonanze in bassa frequenza che se con eccessivo riverbero vengono solo enfatizzate ulteriormente ed aggiungono confusione e distorsione di ascolto. Se il riverbero è troppo questo viene percepito come distorsione a partire dalle alte frequenze, è per cui utile controllare alte e medio-alte frequenze al fine di migliorare l’intelligibilità non solo del riverbero ma anche strumento a cui è associato.
Un leggero ritardo (delay) tra il suono diretto e quello riverberato aiuta la sua comprensione.
L’aggiunta di riverbero, meno sulle prime riflessioni, aiuta a ridurre l’efficienza percepita di un suono bright, squillante ed eccessivamente chiaro, questo perché a livello percettivo il nostro cervello tende a mediare i valori percepiti del suono diretto con quelli riverberati.
Per questo stesso motivo il riverbero tende a scurire il suono dry, può quindi in certi casi essere utile enfatizzare la parte alta dello spettro in frequenza. Al contrario può enfatizzare risonanze in medio-bassa e bassa, quindi da ridurre.
Se il segnale audio presenta troppe prime riflessioni (come nel caso ci si trovi vicino ad ostacoli e ambienti piccoli confinati, vicino pareti riflettenti, ecc..), provare ad aggiungere solo coda riverbero per dare profondità.
Più il suono dello strumento ma anche di un mix è ritmico e rapido nei transienti, ma anche in considerazioni di strumenti percussivi, e meno riverbero (lunghezza), bisogna dare per non impastarlo e rispettare la caratteristica timbrica voluta da musicista o direttore d’orchestra. La stessa cosa vale per strumenti di natura risonante e molto armonica. Generalmente tra una musica lenta ed una veloce e generi musicali affini si va tra gli 1,2 – 1,3 s e i 2,2 s. Suoni percussivi in media devono essere contenuti entro i 0.2 – 0,3 s. in meno rispetto alla media che si dà ad un timbro più armonioso. Questo perché i riverberi artificiali lavorano prendendo il suono diretto ed aggiungendogli con metodo di convoluzione e/o processamento proprio, secondo come il processore è costruito, il tempo di riverbero con le caratteristiche impostate, per cui è bene avere differenti processori effetti in base alla timbrica ed allo spettro dello strumento, in cui in generale si dividono i percussivi e gli armoniosi i cui preset vanno variati in base al genere e struttura musicale.
In caso non sia un Convolutore o comunque che abbia la possibilità di gestire le prime riflessioni è importante che queste siano contenute in un range tra i 15 ms e 35 ms dal suono diretto, questo per avere un effetto di rinforzo e definizione in senso positivo, altrimenti si genereranno echi che cominciano ad essere percepibili ed il rinforzo di definizione non correttamente sostenuto, se troppo presto invece si possono avere problemi di fase e modulazione del segnale diretto. Per quanto riguarda lo spettro di frequenze utili alle prime riflessioni e riverbero, è importante il contributo da 500 Hz – 2 KHz, sotto i 500 Hz può diventare rimbombante e medioso, sopra i 500 Hz molto sibilante e squillante, innesco feedback.
Le prime riflessioni aiutano presenza ed intimità del suono nel senso soggettivo della percezione, in quanto che brevi ritardi tra il suono diretto e prime riflessioni non vengono percepiti e sembra che il suono diretto sia più energetico rispetto al campo diffuso e riverberato.
In un evento live, gli effetti di ritorno del palco (che sono le prime riflessioni che si sommano al suono che esce dal P.A.) sono fondamentali al musicista per la comprensione, preferibile tra i 15 ms e 35 ms, come nei casi precedenti per il rinforzo al musicista e da tenere in considerazione per il mix in sala onde evitare di aggiungere prime riflessioni inutili dai propri processori effetti e che andrebbero ulteriormente a degradare la percezione qualitative soggettiva del suono. Di natura queste prime riflessioni possono già di base contribuire a degradare la qualità del suono. In questo caso è bene posizionare correttamente il monitor in modo che il suo ritorno in sala sia di livello energetico molto inferiore a quello del P.A. < 20 dB, oppure regolarne il livello di pressione sonora sempre allo stesso scopo, il tutto in accordo con il musicista. In alternativa se non si riesce a risolvere il problema, optare per un monitoraggio In-Ear.
Se è necessario ottimizzare la chiarezza, ricchezza, intensità e dimensionalità nella percezione della voce è utile calare il tempo di riverbero associato alla voce rispetto alla parte strumentale.
Nel caso di una registrazione in Studio, un suono ad esempio registrato con un tipo di riverbero dovrebbe essere riprodotto all’interno di un ambiente con simile riverberazione o meglio con caratteristiche di riflessioni limitate e controllare simili a quelle dello studio di registrazione stesse. Più c’è differenza e più la percezione si discosta dal messaggio che si voleva dare nel mix registrato.
Nella voce è importante lavorare bene aumentando le deboli consonanti e calando le più forti vocali se l’ambiente e o microfono le alterano. Questo attraverso l’utilizzo dell’equalizzatore e processori dinamici multibanda.
Per migliorare la pienezza dei toni è possibile allungare il riverbero in media ed alta frequenza cosi da dare maggiore vivezza. Mentre se lo si fa in bassa si aumenta la risonanza e rimbombo.
Quando si usa un riverbero artificiale non Convolutore, è bene smorzare leggermente il transiente di attacco dello strumento e calare bassi e un po’ gli alti a simulare un maggiore realismo, che poi è ciò che accade nella realtà.
GESTIONE DEI RUMORI
In presenza di rumori (come ad esempio effetti sonori) da mixare insieme a suoni strumentali è importante che questi abbiano un livello mediamente più basso rispetto a quello medio strumentale, in quanto che il rumore prende più attenzione rispetto ad un suono armonico come quello strumentale.
AUDIO IN PRESENZA DI VIDEO
Un ascolto stereo o frontale per alcuni setup di ascolto surround (da valutare quindi l’impostazione del formato surround utilizzato) tende ad estremizzare la percezione di dimensione ed estensione sull’asse orizzontale, per cui i 60° e triangolo equilatero come da teoria stereo non sono in questo caso più validi, ma invece è necessario ridurre l’angolo di ascolto L – R a 30°.
Per quanto riguarda il Mix, per ottimizzare la focalizzazione e localizzazione seguire sempre il movimento della sorgente presente nel video, in quanto che se la sorgente si sposta a destra ma il suono viene continuamente percepito in centro o ancor più sinistra si ha uno sfasamento di percezione audio-video.
Stesso discorso per gli effetti, quindi pannarli da dove esattamente stanno arrivando e quindi da dove il nostro sistema uditivo si aspetta di sentirli.
È importate ridurre il parlato al solo mix mono in quanto un’estensione troppo pronunciata porta a confusione e distrazione. Mentre rumori ed effetti buona norma riprenderli e mixarli in stereo o surround.
Utilizzare all’interno del mix suoni e rumori esterni all’angolo di ripresa video è utile al fine di ottimizzare un senso di realismo e dare maggiore dimensione sia audio che video, limitata appunto dall’angolo di ripresa. Per immagini sfocate anche l’audio deve essere meno presente, definito, intelligibile, in quanto a livello psicoacustico il nostro cervello si aspetta un suono lontano e confuso, cosi come visto.
CONSIDERAZIONI
- L’obbiettivo finale di un ottimo ascolto è quello NON più di ascoltare il suono dello strumento musicale o mix considerando lo strumento in sé nel suo insieme di risposta tonale, ma scomporre il suo spettro in frequenza e parte dinamica, rilevarne possibili cause e correzioni per raggiungere un suono di maggiore qualità con minor percezione di variazione e distrazione possibile, naturalezza, neutralità di ascolto ed attenzione sono fondamentali per un risultato ottimale.
- Anche se il nostro apparato uditivo è meno sensibile alle variazioni di frequenza via via che queste aumentano, per cui vi è un tipo di percezione logaritmica, è sempre bene agire con l’equalizzazione e dinamica sul range di frequenze interessate e mai su di un contesto via via più generico (tipo Shelving), in quanto si potrebbe dedurre che percependo in egual misura un più ampio range di frequenze via via che queste aumentano allora si potrebbe lavorare anche interessando con il processo un range di frequenze più grande. In realtà il processore interessato tanto più ampio è il range in cui lavoro ed al contrario tanto più si cerca di rendere un filtro selettivo e tanto più genera distorsione, errori, rumore.
Per questo è sempre meglio ottimizzare questi parametri sul range di frequenze interessate al processamento e mai su contesto generico.
- Muovere testa e corpo il meno possibile durante la fase di mix, in quanto oltre che concentrarsi sul movimento il nostro cervello percepisce rumori provenire da sfregamento muscolare e osseo.
- Durante la fase di Soundcheck può essere buona norma alzare il livello SPL dello strumento sotto processo di circa 3 dB rispetto a come poi suonerà il Mix, questo perché nel Mix e quindi con la presenza di tutti gli strumenti in gioco, il nostro apparato uditivo non avrà più il fuoco di percezione del singolo strumento ma in considerazione anche della regola dei 3 strumenti, andrà a focalizzarsi su più suoni che arrivano alle orecchie mediando notevolmente le dinamiche e toni percepiti e per cui lo strumento risulterà percettivamente più attenuato.
- Provare ad ascoltare il mix con tutte le tipologie di ascolto a cui è destinato per correggere e mediare il mix stesso (stereo – binaurale – surround).
Acquista Attrezzature Audio dai principali Store

