

Design e taratura impianto P.A.
Considerazioni sui software di analisi
Il primo produttore di software per analisi acustica di un impianto audio è stato Bose per la gestione e taratura dei suoi prodotti, molto limitato nei calcoli, basse risoluzioni e senza considerare la fase, poi fu il turno di AFMG EASE come software di terze parti con analisi accurate e realistiche, in quanto che i produttori che creano software per i propri sistemi spesso “barano” sui reali dati, dando valore e migliorie al proprio sistema, ottenendo coperture e varianze minime realmente poco raggiungibili sul campo, mentre EASE utilizza file di dati realistici sulle specifiche dell’impianto audio che il produttore deve fornire se vuole che il suo sistema sia utilizzato per la progettazione in questo tipo di software. Insieme ad EASE che si è via via sviluppato perfezionandosi non solo per un utilizzo in ambiente in campo libero ma anche per l’Acustica Architettonica con migliorie sempre più costanti sul fronte di progettazione di ambienti CAD 2D e 3D, e in considerazione di un ambiente realistico con riflessioni, diffrazioni e rifrazioni simulando il più possibile un ambiente reale, in maniera molto simile ma più incentrato esclusivamente per un ambiente in campo libero c’è MAPP 3D di Meyer che a differenza di EASE non usa la CPU del computer come processore di calcolo ma i propri server in Cloud, quindi potenzialmente più prestante (più che altro veloce nella fase di calcolo) rispetto all’utilizzo di una normale CPU da computer di casa.
Un software di simulazione acustica preciso deve avere risoluzione minima 1/3 di ottava meglio se superiore tipo 1/24 di ottava e oltre cosi da analizzare bene la risposta del sistema nelle sue sfumature di interazione di fase, livello e ambiente, misura angolare di copertura di 1 grado massimo e considerare la risposta di fase ai vari angoli di misura, deve considerare gli effetti di attenuazione ed alterazione della risposta spettrale e velocità del suono dovuti alle variazioni di temperatura e umidità relativa (fig. 1).
fig. 1

Per maggiori dettagli sul programma EASE e sugli effetti della temperatura e umidità relativa sul suono vedi Acustica Architettonica.
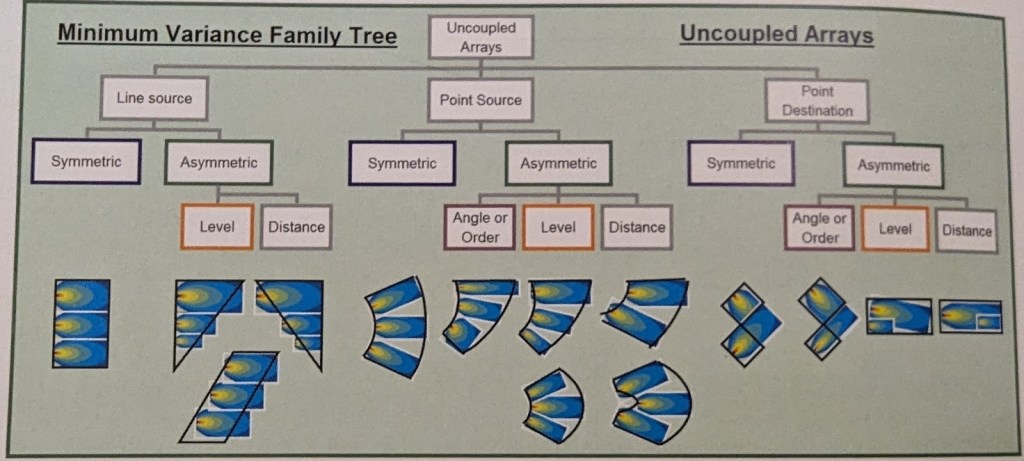
Esistono 3 tipologie di sorgenti sonore (fig. 2) applicate alla musica: Line Source (sorgenti in linea), Point Source (sorgenti puntiformi), Point to Destination (sorgenti puntiformi con punto di destinazione). Esistono poi versioni ibride di questi.
fig. 2

Per l’ottimizzazione della copertura SPL, spettro e Ripple nell’area da sonorizzare (Audience Area) lavorare sull’angolo di copertura e livello dei vari diffusori (per angolo di copertura si considera sia l’angolo di separazione tra i centri acustici di più sorgenti sonore, che l’utilizzo di un diffusore acustico più o meno direttivo “ordine”).
Considerazioni sulla Sommatoria di segnali audio
In figura 3 una tabella indicativa sulle alterazioni di livello in base alla differenza di sommatoria e fase con indicato anche il livello di ripple nella risposta dello spettro in frequenza.
fig. 3

È possibile identificare 2 zone principali che sono la Coupling zone e la Cancellation zone, la Coupling zone è quella di accoppiamento tra due segali di fase entrambi positivi o negativi mentre la Cancellation zone è quella di accoppiamento di due segnali con fase opposta, il livello di differenza tra l’incrocio di fase farà dipendere un differente guadagno (Coupling) o attenuazione (Cancellation).
Queste 2 zone è possibile dividerle in 3 “sotto-zone” che identificano le zone in cui andremo ad agire per la configurazione e taratura delle sorgenti audio per la varianza minima che vedremo più avanti. La Combing Zone che identifica un Ripple della risposta superiore ai 6 dB, la Combining Zone che identifica un Ripple della risposta tra i 3 e i 6 dB, e la Isolation Zone che identifica un Ripple della risposta tra i 0 e i 3 dB.
In figura 4 un esempio di Ripple di risposta spettrale.
fig. 4

L’obiettivo sarà quello di far lavorare il sistema audio per avere una copertura con minor Ripple possibile, quindi che lavori in Isolation Zone o massimo in Combining Zone in tutte le zone dell’area da sonorizzare.
L’obiettivo sarà quello di far lavorare il sistema audio per avere una copertura con minor Ripple possibile, quindi che lavori in Isolation Zone o massimo in Combining Zone in tutte le zone dell’area da sonorizzare.
La cancellazione/attenuazione del segnale comincia quando tra due segnali c’è uno sfasamento superiore ai 120°, quindi l’obiettivo sarà quello di cercare di evitare il più possibile la Cancellation Zone con inversione di fase superiore a 120°.
Con l’aumento del ritardo tra due segnali il filtraggio a pettine parte dagli alti e aumenta via via verso i bassi, quindi per differenze temporali di arrivo tra diversi segnali saranno soprattutto le alte frequenze a subire degli effetti di cancellazione, questo perché hanno lunghezze d’onda più piccole. Sarà importante quindi sincronizzare temporalmente il segnale audio per avere meno Comb Filtering possibile.
In figura 5 viene mostrato graficamente come si verificano le varie zone in base al livello e tempo di arrivo di differenti segali audio.
fig. 5

Più ci si avvicina al livello di picco dell’altoparlante e più la dinamica viene schiacciata, per questo è bene lavorare con un segnale che abbia massimi fattori di cresta (picco) che raggiungano il valore di picco dell’altoparlante (+ 6 dB all’uscita del mixer), così da dare all’altoparlante se tarato bene con l’amplificatore (come vedremo più avanti) la giusta potenza per arrivare al picco.
Ogni ottava di frequenza più bassa è in media necessario 4 volte di escursione in più per riprodurre la stessa potenza acustica.
Sopra a determinati livelli il tensore del timpano porta alla compressione della dinamica percepita in protezione del sistema uditivo, se lo si fa lavorare molto si entra nella zona di stress di ascolto.
In installazione di impianto stereo, più ci si allontana e più l’immagine viene ristretta, mentre più ci si sposta e più la differenza temporale fa cadere la percezione stereo, oltre i 5 ms la localizzazione binaurale viene a meno e l’effetto stereo svanisce a favore dell’altoparlante più diretto, la cui nuova compensazione dovrebbe essere maggiore di 10 dB come offset di livello per riportare l’esperienza in stereo.
In fase di mix ridurre le alte e aumentare le basse giocando anche con effetti e risonanze aiuta ad allontanare o meglio posizionare più indietro strumenti rispetto ad altri, questo può essere utile per migliorare l’immagine del mix posizionando avanti e indietro gli strumenti. Ad esempio portando un po’ più indietro la batteria, basso e quegli strumenti che generalmente sono visivamente più indietro rispetto ad altri.
In alcuni contesti, soprattutto per eventi all’aperto, alla sera le alte frequenze potrebbero risaltare maggiormente perché cala la temperatura e umidità, per questo può essere buona norma eseguire un mix non troppo chiaro se i suoni sono fatti nel pomeriggio.
A livello di percezione il nostro orecchio impiega più tempo per percepire le frequenze basse rispetto a quelle alte, es. in 25 ms una frequenza alta si ripete molte più volte rispetto ad una più bassa, e quindi il nostro orecchio è in grado di avere più copie per comprendere bene cosa sta sentendo ed è anche per questo che è più difficile capire un ritardo temporale tra due segnali a bassa frequenza. È per questo inoltre importante avere delle basse definite e precise per poterle comprendere al meglio a pari livello delle alte.
Requisiti per un sistema ottimizzato
Per la progettazione, calibrazione e verifica di un sistema audio ottimizzato è necessario avere i seguenti requisiti come obbiettivi minimi:
– Minima Varianza di Livello (ugual SPL in tutta l’audience area) (misurato Broadband)
– Minima ondulazione di Livello (ondulazione del livello SPL tra i vari punti dell’audience area), (nota: la maggiore ondulazione avviene sempre ONAX, in asse con il centro acustico della sorgente sonora). (va misurato a 1/3 d’ottava o superiore secondo le capacità del software).
– Minima ondulazione dello Spettro in frequenza (risposta in frequenza piatta), (nota: la maggiore ondulazione avviene sempre in XOVER, nel punto di incrocio “coupling” tra le sorgenti sonore).
Senza entrare nel dettaglio, che vedremo meglio più avanti, nella figura 6 è indicativamente illustrato come ottenere minima varianza in base al tipo di installazione (sorgenti accoppiate e disaccoppiate, simmetriche e asimmetriche), questa immagine evidenzia come per un certo tipo di installazione è più utile lavorare sull’angolo di copertura tra più sorgenti piuttosto che sul livello.
fig. 6

Nella tabella di figura 7 viene evidenziato come ai diversi angoli di incrocio tra più sorgenti ci sia più o meno ondulazione e quindi meno linearità. L’ottimizzazione del sistema su di un triangolo isoscele o ottuso è sempre la soluzione migliore per avere una varianza minima media.
fig. 7

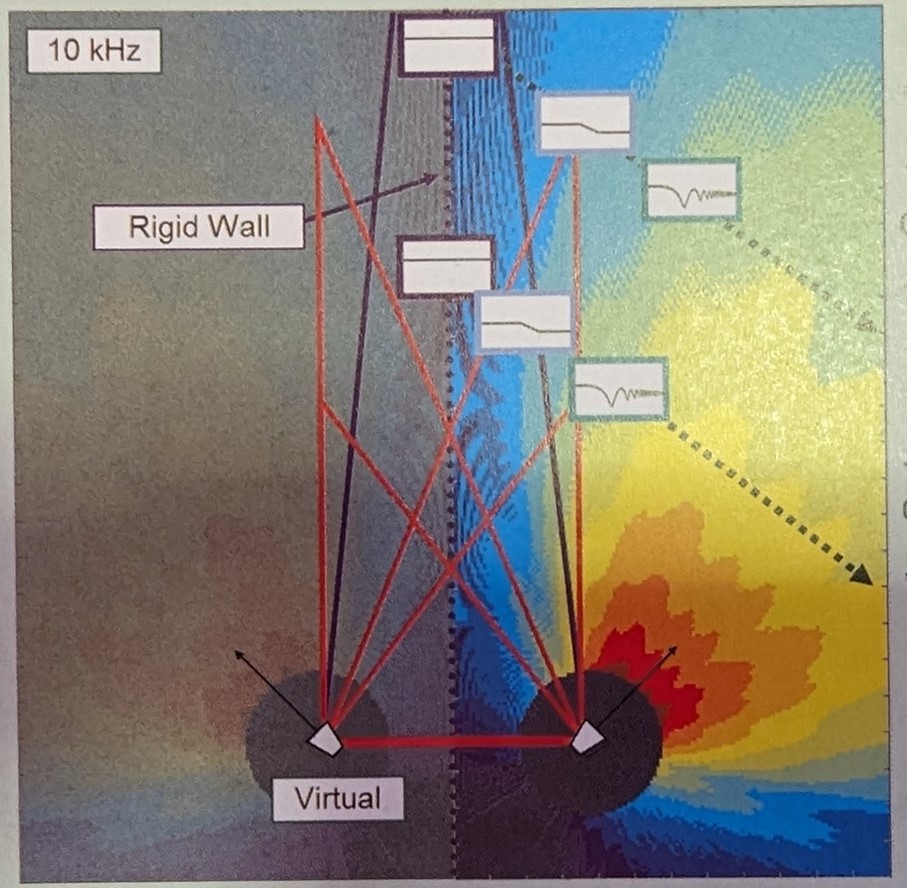
– Un programma di simulazione acustica per essere più realistico possibile nella sua previsione, dovrebbe prevedere anche le somme e cancellazioni dovute alle riflessioni ambientali, un po’ come fa EASE. Nel caso non sia presente, è possibile simulare un ambiente molto riflettente inserendo delle sorgenti speculari al di là delle pareti considerate riflettenti 100% (fig. 8).
fig. 8
– Per un mix Stereo se si usano Front Fill separarli ugualmente in Left e Right in base alla loro posizione ed interazione con il P.A. (fig. 9) in quanto che il Front Fill non è altro che una sorgente atta ad ottimizzare la copertura del lato Left o Right in base alla sua posizione.
fig. 9

Per questo è necessario che livelli e fase siano uguali, difficilmente ottimizzabili con un segnale mono secondario. Stessa cosa per i SUB quando posizionati centrali, in quanto si va a considerare una sorgente unica divisa tra Left e Right e si ottimizza cosi la distribuzione di potenza e fase tra i due canali. In caso di sistemi multicanale separare ugualmente le linee in gruppi multicanale, in considerazione sempre di un sistema unico Satellite, Sub, Front Fill ecc…
– Nel posizionamento delle sorgenti sonore è importante che non si senta il passaggio tra una sorgente e l’altra muovendosi con la testa in punti di ascolto differenti, ma sia tutto in fase in zona di isolamento e con una posizione del ricettore possibilmente non in prossimità. Se il sistema è disaccoppiato come ad esempio per un’installazione stereo, multicanale, più punti di sorgenti sonore disaccoppiate, la percezione di passaggio tra una sorgente e l’altra deve essere graduale. Tutto questo è raggiungibile attraverso un’ottimizzazione del posizionamento e allineamento del sistema (diffusori appositamente accoppiati e tarati per varianza minima). Lo stesso discorso vale per la taratura di Crossover di una sorgente sonora per separare altoparlanti in più vie (es. Alti – Medi), l’ottimizzazione costruttiva del diffusore acustico e taratura del suo crossover, deve essere progettata tale da percepire meno possibile il passaggio tra un altoparlante e l’altro, e questo avviene tanto più è differente la direttività media tra i vari altoparlanti e percepibile soprattutto fuori asse e soprattutto se uno dei due altoparlanti è caricato a tromba e l’altro a radiazione diretta (in cui conviene filtrare il punto di crossover in zone di frequenza dove l’efficienza di direttività della tromba viene a meno).
Note sorgenti sonore
Se una stessa nota è riprodotta da diversi altoparlanti con diverse caratteristiche tonali e diversi livelli di direzionalità comporta uno sfasamento dell’immagine percepita di quella nota, soprattutto quando sei fuori asse che invece di essere un passaggio graduale, cambia la prospettiva di percezione come suono più vicino ad esempio proveniente dal Tweeter direzionale e diventa suono più lontano proveniente dal woofer meno direzionale. Anche un punto di crossover non ben centrato ad esempio che non porta a guadagno unitario, può far risultare quella nota più forte o più debole rispetto alle altre.
Per questo è importante avere un diffusore audio più trasparente possibile nel passaggio tra i diversi altoparlanti di cui è composto, è importante nella fase di progettazione ottimizzare la varianza minima di copertura dello spettro sonoro nell’area di ascolto. È importante che il range di frequenze sia concentrato più possibile in un unico altoparlante e filtrare verso altri altoparlanti solo se e quando necessario e verso frequenze che consentano una dispersione uguale, costante, proporzionale.
Note di Varianza Minima per ottimizzare l’ascolto
Ripple e varianza minima accettabile per l’area da sonorizzare 0 dB, come massimo accettabile +/- 6 dB.
Varianza minima di livello e ondulazione di livello sono direttamente correlate, quindi ottimizzando uno si ottimizza anche l’altro.
Ricevitori su angolo ottuso saranno più isolati (minima varianza) che ricevitori su angolo acuto.
Altri fattori ma più difficili da gestire per una varianza minima sono:
– Varianza minima sulla dinamica ed effetti in tutte le zone.
– La varianza minima ottimizza anche la percezione di ascolto in quanto che a differenti livelli di volume il nostro orecchio percepisce il suono con diversa sensibilità sulla risposta in frequenza.
– Il Ripple della risposta sullo spettro in frequenza può essere attenuato attraverso variazione di gradi, livello (anche in una specifica banda, magari quella interessata al maggior ripple) e tempo tra le sorgenti (se in fase minor ripple).
– Il software di simulazione in uso deve consentire di poter visualizzare graficamente questi dati, per i software moderni questo è aiutato anche dalla vista a gradiente di colori della propagazione e livello di pressione sonora (polar pattern), sia sul piano verticale che orizzontale (fig. 10).
fig. 10

Ripple di Livello
Ripple Spettro di Frequenza

Gradiente di colore piano orizzontale

Gradiente di colore piano verticale
I software moderni hanno potenti tool di configurazione per la gestione del numero di sorgenti, posizionamento, angolature, livelli, ecc.. (fig. 11), consentono inoltre la visualizzazione diretta del sistema così da poter visualizzare i dati e la forma in tempo reale, con indicazioni e allerte anche sul peso e limiti strutturali di installazione.
fig. 11
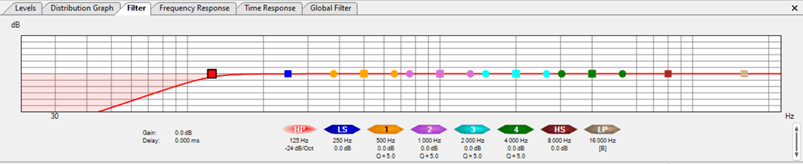
Altri parametri di non meno rilevanza ma che aiutano il processo decisionale di progettazione e velocizzano cosi quello di verifica e calibrazione sul campo, sono la possibilità di visualizzare il tempo di ritardo tra le varie sorgenti cosi da linearizzare temporalmente il sistema mettendolo il più possibile in fase e la possibilità di applicare filtri per verificare sia la corretta linearità del crossover elettrico a livello di crossover acustico che l’effetto di una pre-simulazione di equalizzazione come allineamento spettrale (fig. 12).
fig. 12
Tempo di Ritardo tra le sorgenti sonore

Applicazione di filtri di equalizzazione e crossover
PROGETTAZIONE
Note di impostazione EASE Focus 3
Calculation Parameters:
Mapping Resolution: High, (Highest solo alla fine per un controllo generale delle varianze di livello minimo).
Input Signal Type: Pink Noise
Calculation Accuracy: High Resolution
Sound Pressure Summation: Complex Sum
Up to Frequency: 16.000 Hz.
Mapping Colors, Levels, Frequency Response, Time Response:
Automatic Scale: Automatic Scale (per una comparazione di più varianti per lo stesso progetto consiglio di impostare una scala personalizzata fissa, altrimenti con l’auto correzione lo sfasamento dei colori può far sembrare un progetto migliore di un altro che in realtà non è).
Environment:
Mode: Extended
Processo
Prima di proseguire con il metodo per il disegno e configurazione di un impianto audio per sonorizzare una determinata area di ascolto c’è da fare un accenno sul comportamento di due o più diffusori (fig. 13).
Quando si installano due o più diffusori acustici sarà importante come vedremo bilanciare il fronte d’onda, qualsiasi sistema ha un suo grado di direttività che dipende dalla frequenza e dalle sue dimensioni e tipologia costruttiva, questo quando accoppiato con un altro sistema avrà una zona di incrocio XOVER dove i segnali si incrociano e generano forti campi di interferenza costruttiva o distruttiva e per cui se si incrociano a – 6 dB si crea un segnale stabile ed unitario a livello SPL 0 dB (Unity), una zona di GAP dove ci saranno zone di attenuazione soprattutto per sistemi molto direttivi e molto distanziati dove i due segnali si incrociano a livelli inferiori a – 6 dB, ed una zona di Overlap dove il livello di segnale sarà maggiore di 0 dB dato dalla continua somma dei segnali delle sorgenti. Bilanciare la posizione e distanza delle sorgenti sarà fondamentale per gestire questi 3 fattori sempre presenti e ottimizzare cosi la varianza minima.
Fig. 13

Più il fronte d’onda è direttivo e più i driver devono essere avvicinati per mantenere un crossover a guadagno unitario nella stessa posizione.
Il contesto ideale è riuscire a posizionare l’ascolto in zona di Overlap Costante per avere la più ampia ed omogenea copertura sonora.
In EASE FOCUS è poi possibile simulare il rumore di fondo ambientale così da avere una misurazione ancora più accurata sulla dinamica percepita nei vari punti di ascolto (S/N), (fig. 14). Utile misurare questo parametro dopo la corretta progettazione per la varianza minima su cui eventualmente effettuare piccole ricalibrazioni.
fig. 14

PER IL METODO SULLA CONFIGURAZIONE DI UN IMPIANTO AUDIO PER LA SONORIZZAZIONE AMBIENTALE VEDI ARTICOLO: System Designer – Line Array – Part – I
VERIFICA E TARATURA
Impostazioni Limiter
– Quando utilizzato impostare il limitatore (possibilmente Brickwall), (del DSP) al livello di Picco massimo dell’altoparlante per cui si può considerare + 6 dB rispetto alla potenza RMS dichiarata dal costruttore a meno di non conoscerne i dati esatti, così da poter sfruttare a pieno la potenza dinamica dell’altoparlante stesso. Utilizzare il limitatore alle uscite post crossover per ottimizzare la dinamica delle uscite stesse evitando di lavorare su frequenze in cui non è necessario.
Note sui Limiter
Il Limiter può essere da banco di mixaggio, da processore per segnali di linea di input, a processore per segnali di linea di output, a processore per segnale sul controllo di amplificazione.
Il Limiter a livello di segnale di linea è meglio post frequency divider (crossover), questo perché ovviamente è a frequenza sensibile, se lo mettessi full range prima del crossover ogni frequenza che supera la soglia fa comprimere tutto il segnale audio, mentre post crossover tutto quello che rimane sotto viene lasciato inalterato, ad esempio se va in Limiter il satellite il sub non viene toccato.
Peak Limiter lavora bene per prevenire rotture meccaniche dell’altoparlante, elongazioni, escursioni. RMS Limiter lavora bene per prevenire surriscaldamenti quindi distorsione. Un ottimo Limiter lavora bene e mediato su entrambe le soluzioni.
Impostazione Finali di potenza
– Quando possibile far lavorare sempre i finali ad 8 Ohm o 16 Ohm per minimizzare perdite del cavo e ottimizzare il Damping Factor (fig. 15), (considerare anche il guadagno o perdita di potenza tra il passaggio da un’impedenza e l’altra per avere sempre tutta la potenza necessaria, se la potenza ad 8 Ohm è troppo bassa rispetto a quella necessaria fornita a 4 Ohm, optare per il collegamento a 4 Ohm).
fig. 15

Note sui Finali di Potenza
Gli amplificatori professionali sono tarati con riferimenti in Tensione (Gain regolabile) o con riferimento in Sensibilità (Gain fisso) e possono avere dei controlli in tensione mV, dBV o dBU (fig. 16 – 17).
Amplificatori con riferimento in guadagno di tensione
Ogni 3 dB in più di segnale in input è un raddoppio della potenza di uscita a parità di guadagno e dipendente dal carico. Ogni 3 dB in più di guadagno è un raddoppio della potenza di uscita a parità di tensione di ingresso e dipendente dal carico.
fig. 16
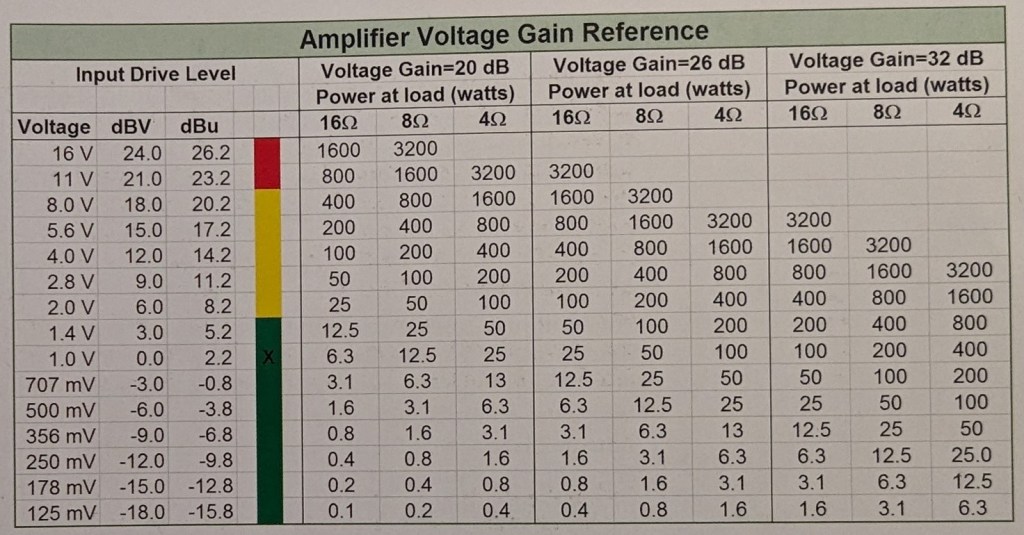
Fino a valori limiti massimi di Input variando con il Gain è possibile aumentare o calare il livello di Input ottenendo la potenza di uscita desiderata.
– Per finali con guadagno di ingresso variabile (Gain), impostare il guadagno ottimale per avere in uscita la potenza necessaria con riferimento di ingresso a 0 dBV.
Amplificatori con riferimento in sensibilità
Generalmente questi sono settati a valori vicino al Clip per avere la piena potenza di uscita, generalmente a – 3dB dal clip come margine di input.
Per capire il guadagno che hanno serve il valore di riferimento in ingresso e il livello di tensione di clip, esempio se clippa con 10 dB in ingresso con sensibilità di riferimento 0 dB a 1 V vuol dire che ho 20 di guadagno.
fig. 17

Lavorando a più bassa impedenza si ha inoltre più margine dinamico in quanto la potenza è più bassa ed il livello massimo di clip rimane più alto. Amplificatori professionali hanno stesso livello di Clip sia a 8 che a 4 ohm.
Lavorando a più bassa impedenza gli amplificatori hanno vita più breve e la qualità è più scadente con una riduzione del Damping Factor e aumento distorsioni.
Il valore RMS è il 70 % del valore di picco misurato, che in tensione sono 3 dB ma vale solo su onda sinusoidale, onde audio hanno transitori molto veloci e per questo il valore RMS è un valore medio dato dai singoli valori e va a definire l’Headroom del segnale audio (valore RMS – picco transitorio), 6-12 dB di Headroom è tipico di un programma musicale.
Il Limiter presente come controllo all’interno di amplificatori è generalmente un Negative feedback Limiter, praticamente il punto di negative feedback è posto dopo lo stadio di amplificazione e quindi viene controllata la tensione all’uscita del finale (V) (sono limitatori generalmente integrati nel filale come protezione di rotture e distorsioni e protezioni termiche, a volte anche controllabili dall’utente), a differenza di quelli standard (predittivi) che controllano la tensione in ingresso o uscita dopo filtro (mv) presente all’interno del DSP (fig. 18 – 19).
fig. 18

fig. 19

Anche il limitatore termico quando si acquista un amplificatore esterno andrebbe tarato per i valori di Thermal ed escursione massima dell’altoparlante.
Per precisione quello negative feedback è meglio per ottimizzare tutta la dinamica e potenza ammissibile dal finale senza limitarla a priori.
I sistemi di diffusione attivi e gli amplificatori esterni dedicati in teoria sono già tutti ottimizzati.
Anche mettere in parallelo più ingressi di linea negli Amplificatori (Input-Link-Input-Link), riduce l’impedenza di carico di ingresso, quindi perdite di segnale e distorsione.
A livello di perdite di linea può essere considerata questa formula:
LineLoss (dB) = 20 x log10 x (input+cable+output impedance) / (input impedance).
Note sulla distribuzione di potenza
Quando possibile utilizzare sempre sistemi ad amplificazione separata cosi da ottimizzare al meglio la potenza dedicata agli altoparlanti riducendo interferenze di ogni genere.
Se il sistema è con crossover integrato meglio che i carichi tra gli altoparlanti sia indicativamente uguali, “es. 8 Ohm per i Woofer, singolo o due da 16 Ohm in parallelo, ecc.., e 8 Ohm per il Tweeter”, cosi da minimizzare le oscillazioni di potenza in base al contenuto spettrale in frequenza visto dall’amplificatore finale, in quanto che se ho un Woofer ad 8 Ohm per le basse ed un Tweeter a 16 Ohm per le alte, quando lo spettro è concentrato sulle Basse il finale avrà una predominanza di potenza verso gli 8 Ohm, mentre se sulle alte sarà a 16 Ohm, riducendo quindi la potenza di carico applicata che in questi casi può andare facilmente a sovrapotenziare il Tweeter o a depotenziare il Woofer creando instabilità di livello oltre che rischi di rottura.
Se invece i carichi sono gli stessi verrà sempre letta la stessa impedenza e sarà quindi la potenza meglio gestita, (in questo caso molto probabilmente il crossover avrà una resistenza che attenua il livello di segnale verso il Tweeter “essendo generalmente la componente che richiede un più basso wattaggio rispetto ai Woofer per le medie e basse”, appunto per inviargli la giusta potenza e non rischiare di danneggiarlo). E comunque la potenza verrà distribuita su differenti altoparlanti secondo lo spettro, es. sul Woofer quando lo spettro è verso il basso, sul Tweeter quando verso l’alto e su entrambi quando lo spettro è Broadband, riducendone quindi la potenza. Mentre in un sistema a vie separate la potenza rimanere sempre la stessa.
Impostazioni di Crossover
– Impostare il punto di incrocio per ottenere guadagno unitario (-6 dB), overlapping (> – 6 dB) o gap (< – 6 dB) secondo le necessità, questo dovrà essere poi ricercato nel crossover acustico di allineamento delle sorgenti a meno di non voler ottenere differenti forme di spettro.
– Per mantenere un livello SPL di guadagno unitario o di gap o overlapping secondo le impostazioni del crossover elettronico, è necessario che i livelli audio elettrici di uscita e le pendenze siano uguali, in caso contrario la pendenza del filtro e suo livello di guadagno faranno dipendere una diversa frequenza di taglio ed un diverso coupling di accoppiamento dei due filtri, da ottimizzare poi nella fase di taratura.
Stessa cosa per il crossover acustico, differenti livelli di guadagno e copertura faranno dipendere un differente punto di incrocio con guadagno unitario (fig. 20).
fig. 20

– Sia a livello elettrico che acustico è molto importante regolare in fase il punto di crossover per avere il Coupling a + 6 dB ed evitare ripple aggiuntivi sulla risposta.
– Se si vuole spostare la fase senza spostare la frequenza di taglio o agire temporalmente sullo spettro, agire con un filtro Passa-Tutto.
– Per quanto riguarda il tipo di filtro questo è a discrezione dell’utente, i filtri sono quasi tutti identici come pendenza, cambia solo la curvatura dell’angolo del ginocchio, poi più la pendenza è ripida e più preciso sarà il taglio ma a scapito di un maggiore ripple della risposta rispetto a pendenze più dolci. Per questo va scelta con accuratezza in base all’incrocio di frequenza desiderato che in ogni caso deve combaciare in fase.
Note Crossover
Per avere guadagno unitario i filtri devono lavorare sullo stesso livello di segnale.
Crossover con differenti livelli di pendenza e differenti livelli di guadagno spostano il centro di crossover, tendenzialmente verso valori di crossover a più basso livello.
Se si utilizzando diverse pendenze del filtro per l’incrocio di fase (se non a fase lineare), è utile analizzare la risposta del singolo altoparlante anche dopo aver applicato il filtro in quanto che diverse pendenze girano differentemente la fase.
Quando possibile ed in considerazione anche della latenza percepita utilizzare sempre filtri FIR a fase lineare.
Per avere guadagno unitario l’incrocio dei filtri deve essere a – 6 dB, se accoppiati o a livelli più alti di – 6 dB ci sarà un guadagno proporzionale attorno alla frequenza di incrocio.
Se la frequenza di taglio inferiore (es. Satellite) è più bassa di quella superiore (es. Sub), si otterrà un guadagno proporzionale nella banda di Overlapping.
Una buona decisione sul tipo di pendenza e frequenza di taglio del crossover è quella di far cadere a più bassi livelli prima che la risposta di fase superi i 120 gradi e diventi negativa (cancellazione).
Per le alte frequenze è bene utilizzare un filtro passa basso molto ripido per minimizzare le escursioni soprattutto in bande di frequenza non udibili, escursioni che potrebbero danneggiare l’altoparlante, passa alto invece può essere tanto meno pendente quanto più è bassa la frequenza e la distanza tra le due sorgenti, in quanto che l’interazione di fase a lunghezze d’onda cosi basse è minima, quindi pendenza più morbida, sfasamento più morbido e valutare se la pendenza genera un aumento del livello SPL nell’incrocio, altrimenti utilizzare pendenze più ripide e valutare la fase.
L’accoppiamento di potenza combinata tra i vari driver (massimo 6 dB) realizzata con frequenze di taglio in Overlapping, consente di avere maggiore SPL con minore sforzo da parte dei driver, questo perché si sommano le due sorgenti. Pendenze ripide riducono al minimo l’interazione di fase negativa nella zona comb filtering ma minimizza anche gli effetti di fase additiva.
L’allineamento di crossover di una sorgente è utile farla sempre al centro tra gli altoparlanti tale da avere un triangolo rettangolo che ottimizza fase ed ampiezza, quindi in base alla tipologia costruttiva del diffusore acustico a più vie, prendere come riferimento sempre il punto centrale.
Se la risposta di fase tra più altoparlanti di una stessa sorgente o tra sub e satellite è molto diversa, può essere buona norma provare ad invertire la fase di uno dei due come base di partenza per la taratura e calibrazione, potrebbe esserci un problema di fase rilevato anche lungo il processore, cavi, ecc..
Più il filtro di equalizzazione è pendente e più la risposta all’impulso è meno definita e precisa, quindi meno performante (quelli a fase lineare invece mantengono la precisione dell’impulso).
Sui punti di minima e massima frequenza possibile delle sorgenti stesse, è utile utilizzare filtri ad alta pendenza per minimizzare lo stress di riproduzione delle frequenze inferiori e superiori ai loro limiti.
Per quanto riguarda la scelta della frequenza di crossover direi che in una configurazione Satelliti Left e Right con Sub in Mono o Centrali poggiati a terra, se i Sub sono ottimizzati nella copertura omogenea e’ facile ottenere ad esempio 90 – 100 – 110 Hz una piu’ omogenea copertura rispetto a quella possibile dai satelliti che sono distanziati in Left e Right, per questo e’ necessario fare alcune valutazioni. L’ideale e’ sempre il dare quanto piu’ possibile ai Satelliti in modo da rendere il fuoco anche alle piu’ basse frequenze verso i punti dal piu’ vicino al piu’ lontano ed avere una migliore fase e risposta in quanto singolo elemento. La valutazione da fare e’ quella se mantenere una piu’ ampia ed omogenea banda di frequenze ai Sub a scapito di una minore distanza percorsa, oppure lasciare quella banda di incrocio ai satelliti per riuscire a spingerla piu’ lontano a scapito di maggiori interferenze. E la stessa cosa vale nel caso di utilizzo di Sub Sospesi ma sempre distanziati Left e Right e quindi con sempre maggiori interferenze rispetto ad una configurazione con Sub accoppiati.
Mentre se i Sub sono posti in Left e Right distanziati ad esempio in Stacked con i Satelliti conviene sempre lasciare piu’ banda possibile al Satellite che ne ottimizza una migliore distribuzione dal punto piu’ vicino a quello piu’ lontano.
Misurazione e taratura
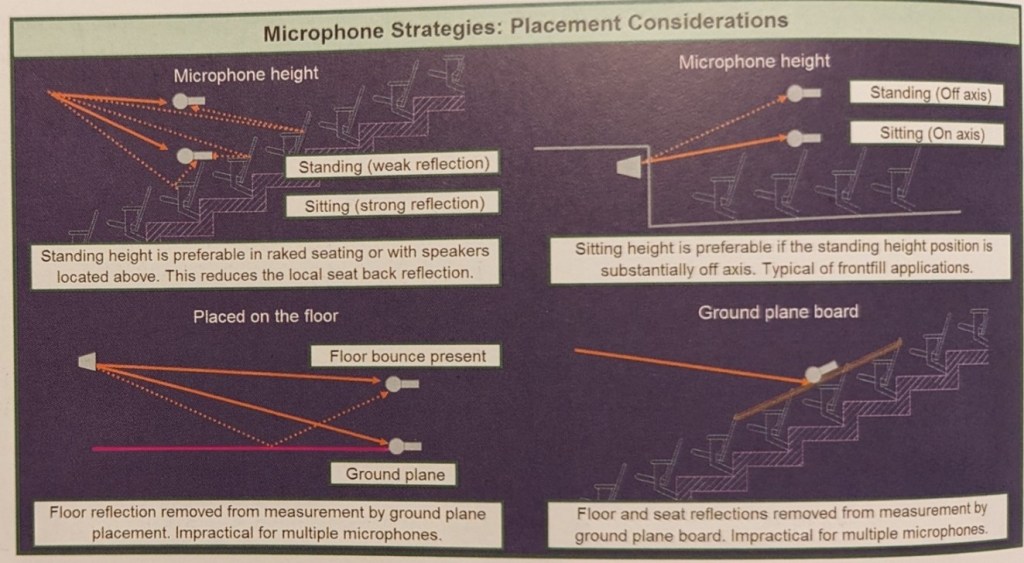
Il microfono di misura deve essere posizionato all’altezza media di ascolto 1.70 in piedi o 1.40 seduto, se l’ambiente è molto riverberante e con alta presenza di prime riflessioni è possibile effettuare una misurazione comparativa appoggiandolo al piano terra (così facendo è possibile rilevare l’interferenza delle riflessioni e non considerarle per il processamento di calibrazione, è importante calibrare la sorgente audio sul piano diretto in relazione all’ambiente e non il suono di risposta ambientale da cui non si ottengono benefici se non agendo direttamente sul trattamento acustico delle pareti ambientali stesse).
Di seguito una tabella di considerazioni sul posizionamento dei microfoni di misura (fig. 21):
fig. 21
All’interno del software di misurazione sarà importante caricare la curva di correzione equalizzazione del microfono utilizzato (questo è importante per ottenere un rilievo con maggiore trasparenza e linearità possibile), e per il corretto rilievo dell’SPL è importante che il microfono sia calibrato (fig. 22).
fig. 22

Per la calibrazione della singola sorgente, se non si hanno già i dati di riferimento analizzare singoli elementi (satelliti (full range o più vie, e sub) a 1 metro di distanza, a 0 dB, nel loro centro acustico (triangolo equilatero tra gli altoparlanti), (possibilmente in camera anecoica).
Il livello del segnale di test deve essere quello che porta al raggiungimento del livello SPL medio che sarà per lo spettacolo, es. 96 dBSPL.
In fase di equalizzazione e modifiche al livello, trattare con più cura e attenzione la mediazione dei picchi piuttosto che dei buchi, questo perché se facciamo una media dei valori, i buchi hanno sempre un grado di attenuazione maggiore che i picchi che al massimo arrivano a + 6 dB di Coupling ogni raddoppio delle sorgenti sonore in fase. Per questo sarebbe sempre una media negativa di ottimizzazione. Inoltre la nostra percezione è più incline ai picchi che hai buchi, sentiamo sempre e meglio ciò che è in eccesso rispetto a quello che non sentiamo. Livellando poi i picchi è possibile aumentare il livello SPL medio prima del raggiungimento di un livello di distorsione.
Come per il MIX anche per l’equalizzazione dell’impianto audio è sempre meglio lavorare in Cut che in Boost, soprattutto perché se lavoro in Boost soprattutto in frequenze limite prossime di banda a quelle riproducibili linearmente dall’altoparlante è probabile che il livello di distorsione aumenti proporzionalmente a quanto Boost applico, in più soprattutto in utilizzo di filtri a NON fase lineare, essendo il Cut limitato a – 6 dB che è il massimo di somma raggiungibile dai picchi, si limita anche lo sfasamento di fase rispetto ad utilizzare il Boost che può essere anche superiore a + 12 dB per il livellamento dei buchi.
Lavorare con l’equalizzatore per lo stadio in ingresso al crossover elettronico. L’equalizzazione dello stadio di Input rispetto a quella di Output post-crossover, aiuta a bilanciare ed ottimizzare il taglio crossover elettronico che se troppo basso di livello genera uno sfasamento sul punto di crossover. Limitare il processamento di equalizzazione di uscita post-crossover alle piccole correzioni necessarie dovute agli interventi dei filtri.
Per una corretta misura è importante monitorare sempre anche i singoli processori di segnale presenti lungo la catena audio, così da rilevare eventuali anomalie derivate da un loro malfunzionamento piuttosto che dall’impianto audio stesso (es. monitorare uscita Main mixer a cui fa riferimento il livello del P.A. e uscita DSP), questo è possibile attraverso il prelievo di una copia dell’uscita di più segnali da inviare al software di analisi e comparare attraverso la funzione di trasferimento il segnale di ingresso ed il relativo segnale di uscita (fig. 23).
fig. 23

Note software di analisi/calibrazione
Il software utilizzato nella spiegazione che seguirà è Smaart Live, rimando allo studio del suo manuale per la comprensione dei vari parametri che seguono.
Avere sempre a disposizione i dati della risposta in frequenza delle singole sorgenti utilizzate nel P.A. come riferimento per la taratura ufficiale nel suo insieme, in quanto che andando poi a sommare elementi le risposte potrebbero estendersi nel loro campo acustico e questo potrebbe portare a definire frequenze di taglio ed equalizzazione eccessivamente alte o basse secondo le reali potenzialità del singolo sistema.
Analizzare la risposta con una risoluzione adeguata 1/24 ottava o superiore cosi da vedere in modo chiaro il Ripple di varianza minima e distinguere echi dal suono diretto (fig. 24 – 25).
fig. 24

fig. 25

L’analisi del singolo elemento in camera anecoica al fine di definire punti di crossover elettronico o passivo, farla con ponderazione 0, Istantanea (non mediata) per vedere la risposta reale dell’impianto.
L’analisi per la taratura e monitoraggio del P.A. eseguirla con ponderazione dipendente dal rumore ambientale circostante, trovare quella giusta per avere una misurazione più stabile possibile a più bassa ponderazione, tale da poter essere valutate e comparata.
Per le impostazioni della finestra FFT utilizzare filtro Flat Top per misurare THD, Sinusoidi e Ronzio, in quanto tratta meglio la parte superiore del segnale audio. Per misurazioni del Rumore con spettro causale sia a canale singolo che in Funzione di Trasferimento (bianco-rosa), o sorgente musicale, utilizzare Hann per il suo migliore trattamento delle onde casuali (fig.26).
fig. 26

Per l’analisi temporale definita prima nel caso la misura sia accettabile e quindi comparabile utilizzare 1 – 2 – 3 di Smaart Live che sono i tempi di integrazione FIFO, danno una migliore risposta avendo un rapporto segnale rumore piu ampio, mediando a pari livello ogni singolo campione di ingresso, rispetto ai classici tempi di integrazione più dedicati al rumore che ponderano a peso ogni nuovo campione che arriva (fig. 27).
fig. 27

Questo consentire di avere una Magnitude piu precisa con meno interferenze dovute agli errori FFT e rumori.
n.b. La risposta all’impulso ragiona nel dominio del tempo, mentre quella di fase e la Magnitude nel dominio della frequenza, le due cose non sono simmetriche e comparabili con una sola impostazione di analisi, per questo è necessario utilizzare differenti processi per ottenere i migliori risultati visivi sia per la misura nel dominio del tempo che in quella della frequenza.
A questo proposito SMAART Live utilizza due motori di processamento DSP, uno per il dominio del tempo ed uno per il dominio della frequenza.
Per quanto riguarda la risposta all’impulso che come vedremo darà a noi informazioni sui ritardi da applicare ai vari diffusori per avere tutto il sistema in fase temporalmente parlando, sarà necessario aumentare il piu possibile il rapporto segnale rumore cosi da avere chiaro l’impulso e nell’eventualità di voler misurare la risposta di un ambiente anche le varie riflessioni e riverberazione. Per fare questo sarà necessario aumentare il valore dell’ FFT Size e aumentare la media ponderata di integrazione che non fa altro che aumentare anche la dinamica quindi il rapporto segnale rumore, rendendo sempre più chiara la differenza tra gli impulsi, echi, riverbero e rumore. Questo valore in realtà dipende anche dalla distanza di misurazione, piu si è lontani e più alto deve essere il valore FFT per avere cosi tempo di rilevare e mediare il ritardo di arrivo dell’impulso, ma in ogni caso misure troppo lontane portano anche a peggioramenti sulla precisione di analisi, quindi non andrei più lontano di un 16K o 32 K che è circa 100 Metri di distanza, ancor più se l’ambiente è molto riverberante e quindi è meglio rimanere entro pochi metri di distanza dal suono diretto, in quanto che la funzione di trasferimento più prende dentro la misura riverbero e rumore e peggio è.
Quando si misura un impulso per la calibrazione temporale di un Line Array è bene quindi impostare alti valori FFT per avere un discreto rapporto segnale rumore che consenta di rilevare con chiarezza il picco, per quanto riguarda le medie di integrazione valutare in base all’ambiente, tanto più rumore e riverbero c’è e tanto più il valore delle medie dovrà essere alto.
Se si vuole misurare la risposta della stanza sarà necessario avere una FFT Size in grado di contenere tutto il decadimento di quell’ambiente. Non sempre i software hanno delle FFT Size che possono contenere molti secondi di analisi in tempo reale, oltre al fatto che elevati tempi di analisi possono generare un maggior numero di errori e necessitare di DSP sempre piu potenti, oltre che impiegare anche piu tempo (il tempo della durata della finestra FFT). Per questo in questi frangenti di rilevamento acustico è bene registrare la risposta su di un file .wav e poi importare il tutto su di un programma tipo SMAART per leggere l’andamento spettrale di quell’ambiente (meno problemi, piu velocità e precisione).
Per quanto riguarda la risposta in frequenza e quindi anche fase, il concetto è esattamente l’opposto, sarà necessario escludere il più possibile rumori echi e riverbero dalla misura in quanto portano ad inserire rumore ed errori di misura soprattutto se gli echi ed il riverbero e rumori sono con un tempo di ritardo o decadimento superiore alla lunghezza della finestra FFT impostata.
In figura 28 un esempio di come l’FFT Size possa determinare errori.
Fig. 28

Come si vede dalla figura 28, differenti grandezze dell’FFT Size portano a differenti mediazioni della risposta, quindi se i successivi impulsi rientrano nella prima finestra non verranno ponderati, se rientrano nella seconda verranno ponderati con la prima, se rientrano nella seconda ponderati con la media della prima e la seconda (se integrato), o in media con la prima e seconda (se FIFO), ecc… Quindi si otterranno differenti risultati sulla Magnitude, che ricordo essere la risposta in frequenza della funzione di trasferimento, quindi quanto il segnale di misura è uguale ad un segnale di riferimento di stessa caratteristica e proprietà. E’ misurata in dB e dirà a noi quanto dare Boost o Cut alle varie frequenze per far si che il segnale misurato (quindi il nostro impianto), suoni piu simile e quindi trasparente al segnale di riferimento (fig. 29).
Fig. 29

L’obbiettivo sarà quello di linearizzare e rendere il più trasparente la risposta diretta dell’impianto audio, poi da modellare ad orecchio in quanto il software fatica a considerare in modo simmetrico i rumori, riverberi ed eco, andando a mediare erroneamente la risposta in frequenza misurata. Questo proprio per i limiti appena definiti sulla precisione degli analizzatori FFT.
Per fare questo sarà necessario ridurre la FFT Size cosi da portare rientri e rumori su campioni successivi da ponderare con meno valore rispetto ai primi campioni in cui è presente il suono diretto, ma è anche vero che dovrà essere necessario avere abbastanza risoluzione per garantire una corretta cattura dei campioni anche alle frequenze più basse. A questo proposito SMAART utilizza una funzione chiamata MTW che adatta la FFT Size in base alla frequenza presa in esame riducendone il valore all’aumentare della frequenza in quanto avendo onde più piccole e brevi può essere necessaria una più piccola finestra per il corretto rilievo.
Come anticipato è poi possibile decidere se utilizzare valori di integrazioni classiche (quindi i successivi campioni vengono mediati con la media dei campioni precedenti), oppure tramite un processo di mediazione detto FIFO (first In e first Out), che media allo stesso livello tutti i campioni in ingresso.
Il metodo FIFO è più efficiente per tenere alto il rapporto segnale rumore in quanto che il suono è un elemento direttamente correlato a se stesso e la sua somma è in media + 6 dB, mentre il rumore casuale non è correlato e la sua somma media è di circa + 3 dB, per questo avendo una media costante dei campioni di ingresso come quella FIFO è possibile aumentare di molto il rapporto segnale rumore tanto ed avere misurazioni più fedeli.
(più l’analizzatore ha veloci e varianti variazioni di livello nella risposta e più significa che ci sono rumori, risonanze, echi, instabilità della sorgente audio stessa, e questa non è una misura che può essere catturata per essere comparata, valutata e lavorata, sarà necessario quindi aumentare il valore di medie per raggiungere un livello affidabile e pulito).
Come per la misurazione della risposta all’impulso il valore di mediazione va stabilito arbitrariamente in base al tipo di ambiente, in ambienti molto rumorosi e riverberanti per avere una misura stabile, rilevabile e comparabile con minor rientro di rumore ed interferenze, sarà necessario avere un valore di ponderazione alto, mentre più l’ambiente è anecoico e meno mediazione sarà necessaria, e come prassi per margine di errore utilizzare sempre la più bassa mediazione possibile.
Per quanto riguarda le finestre di ponderazione FFT, utilizzare modalità come anticipato MTW che ottimizza le finestre in base alle ottave di frequenza, prendendo cosi i campioni necessari e lasciando fuori quelli non necessari. In alternativa sarà necessario prelevare campioni di ottava a diverse finestre di ponderazione (basse frequenze alte finestre di ponderazione, alte frequenze basse finestre di ponderazione in quanto che le alte hanno più cicli rispetto alle basse e verrebbero cosi mediate troppo rispetto alle basse a parità di tempo di ponderazione, oltre che a integrare anche maggiore rumore, oppure se troppo breve soprattutto le basse potrebbero non essere rilevate correttamente), in più consente di ottimizzare la risposta visiva delle alte frequenze che in alternativa mostrerebbe una nuvola di varianti poco utile ai fini dell’analisi e processamento in quanto che alle alte frequenze percepiamo bande critiche molto più grandi rispetto alle basse e quindi è necessario agire con filtri a più largo spettro per poter percepire la variazione timbrica necessaria (fig. 30).
In figura 30, l’impostazione MTW ed una comparazione visiva tra una risposta classica FFT ed una MTW.
fig. 30


Quando si analizza in una situazione standard impostare l’analisi di Smaart in Polar (più realistica), mentre quando si è in ambienti rumorosi e riverberanti impostarla in Complex (esclude maggiormente rumore e riverberazione), (fig. 31).
fig. 31

Per un corretto rilievo è importante che il software sia impostato sul livello di temperatura attuale (fig. 32).
fig. 32

La cattura della risposta non farla in modo immediato all’accensione della sorgente e rilevazione, dare un po’ di tempo alla mediazione ed al processo di integrazione di ottimizzare il rilievo.
I software di analisi considerano sempre segnali costanti e di infinita durata, quindi che si incrociano sempre e si sommano sempre costanti nel tempo (peggiore dei casi), nella realtà i segnali audio sono casuali e spesso cambiano nel loro tempo di interazione tra le varie sorgenti anche dipendente dall’ambiente e soprattutto per segnali stereo molto variabili tra i vari canali audio. Per cui soprattutto per le medie e alte frequenze il sistema sarà più ottimizzato in ambiente reale rispetto a quello tarato da software. Anche la sommatoria dei segnali è fissa e costante, mentre nella realtà può essere anche casuale sempre per gli stessi motivi. Solo lo spettrogramma è in grado di rilevare e notificare la sommatoria nel tempo, quindi le variabili tra sommatoria stabile e sommatoria non stabile (non stabile quando il segnale arriva casualmente e o con tempi di ritardo alti da non considerare una somma). Per questo l’utilizzo dello Spettrogramma può essere una valida vista complementare a quella RTA nel processo di calibrazione e verifica.
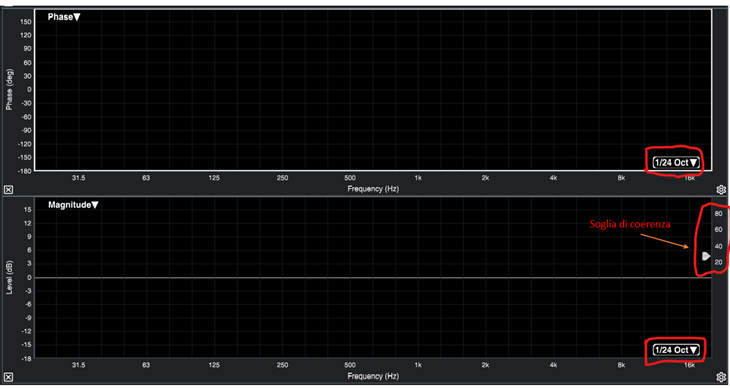
Per la Funzione di Trasferimento la Magnitude come anticipato ci dice la differenza tra l’RTA di riferimento e quello misurato, mentre la Coerenza ci dice la differenza tra RTA e Fase del segnale di riferimento rispetto a quelli del segnale misurato. Anche queste due finestre vanno analizzate a minimo 1/24 di ottava.
Utilizzare la soglia di Coerenza per eliminare dall’input i rumori di fondo ed il silenzio quando non si ha suono ed evitare così una media non importante (fig. 33).
fig. 33
Per ottimizzare la Funzione di Trasferimento è importante che i livelli del segnale di misura e di riferimento siano identici, per calibrare questo è utile e più preciso utilizzare un segnale di test come sinusoide, rumore o segnale a bassa dinamica, con impostazioni della risposta all’impulso con un alto rapporto segnale rumore. È inoltre importante che questi livelli sia il più possibile lineari, nel senso che se mando in distorsione un finale, il segnale prelevato non sarà mai comparabile ed analizzabile dalla funzione di trasferimento, deve invece lavorare in una gamma di linearità (prima del clip).
Se la curva di Coerenza è un rilevatore a gradini allora ci sono problemi temporali tra suono da misurare e suono di riferimento.
Un altro problema che potrebbe generare una non corretta Coerenza è l’eccessivo rumore di fondo, riflessioni, ritardo temporale tra segnale di riferimento e di misura, far lavorare i processori e/o altoparlanti al loro livello di stress (introducendo cosi distorsioni), questo a meno di non voler eseguire test sui valori di distorsione. Una misurazione di prossimità comparata ad una distanza media e lontana può aiutare a capire quanto di queste interferenze sono introdotte potendole cosi escludere in fase di calibrazione ed ottimizzazione.
La vista migliore per comprendere lo spettro RTA è quella logaritmica che è già di default impostata per le frazioni di ottava in Smaart Live.
Nel processo di rilevazione con i Microfoni utilizzare tecnica Democratica (più punti di rilievo in posizioni ben definite per la varianza minima di livello e spettro: ONAX, XOVER, OFFAX, SYM). Come definito in fase di Progettazione i punti di rilievo e quelli di simulazione da progetto dovrebbero essere gli stessi cosi da comparare e vedere le differenze tra la simulazione ed il contesto reale.
Come ordine di calibrazione prima il sistema più performante (P.A. Main) poi il sottosistema meno performante andando via via a sommare ed analizzare. La distanza e la copertura media più ampia ha la priorità su quelli che coprono aree più vicine, ridotte e con meno potenza (la priorità ce l’ha anche il caso di dover sonorizzare aree confinate in cui il pubblico paga un biglietto più costoso per vedere da vicino gli artisti ed avere un suono più qualitativo).
Dopo la calibrazione del sistema Main calibrare i sottosistemi, prima quelli Accoppiati (es. Downfill) e poi quelli disaccoppiati (es. Infill, Out Fill, FrontFill).
Considerazioni sulla Funzione di Trasferimento
Un utilizzatore non esperto potrebbe pensare che per linearizzare la risposta acustica dell’impianto audio basti analizzare il suo RTA e poi compensare i Gap e Boost fino ad un livellamento. Si, è un ragionamento giusto (ed è quello che si faceva prima dell’avvento della funzione di trasferimento), ma il problema principale è che non si ha una linea di riferimento media da cui partire per considerare quello che è in Boost e quello che è in Cut.
Cosi facendo si va sempre a decidere o provare diverse linee di riferimento medie senza mai ottenere risultati realistici ma sempre un troppo Boost o troppo Cut, rendendo di fatti questo inutilizzabile e con scarsi risultati per un corretto e trasparente processo.
La funzione di trasferimento invece avendo sempre e costantemente un segnale di riferimento, definisce con precisione ed accuratezza quello che è in eccesso e quello che è da amplificare (fig. 34).
Fig. 34 (RTA non ha linea di riferimento per la definizione di quanto Boost e Cut dare)
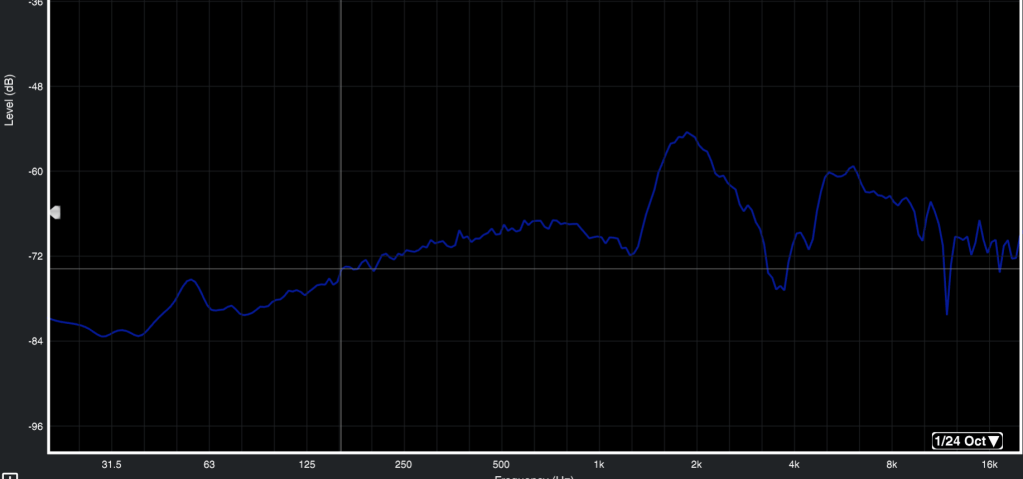
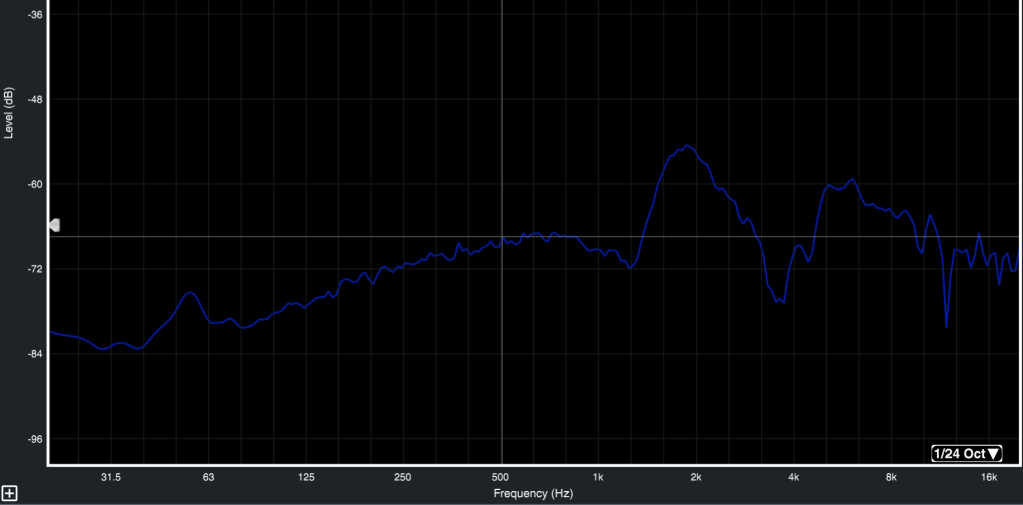
(Funzione di Trasferimento ha una linea di riferimento per determinare quanto Boost e Cut dare)

Considerazioni sulla Fase
Leggere uno sfasamento a 0 gradi tra due sorgenti non vuol dire in fase, ma può voler dire che è in fase ma ritardato, quindi combacia solo la fase ma è in ritardo, il ritardo lo vedi dalla pendenza, leggendo da sinistra verso destra se la pendenza è verso l’alto l’output arriva prima dell’input, se è verso il basso arriva prima l’input, in base all’andamento della pendenza di fase è inoltre possibile capire il tipo di ritardo temporale tra il segale di riferimento e quello di misura (fig. 35), è quindi importante il giusto delay time per il sincronismo di fase. Pendenze più ripide significano maggiore ritardo.
fig. 35
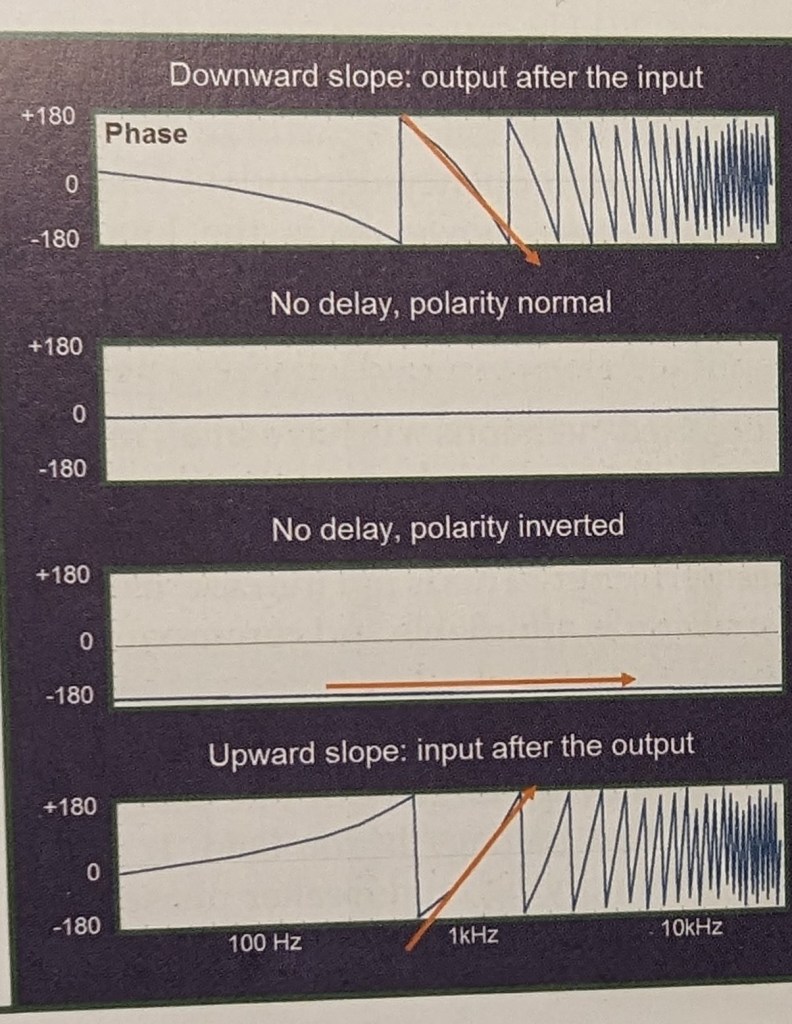
Impostando visualizzazione lineare può essere utile per vedere il tracciamento della linea orizzontale di fase a 0 gradi, mentre in logaritmico è più facile analizzare le curve ma è meno chiara le linearità in quanto che il logaritmico creerà sempre delle curvature.
La fase ragiona come il livello, se un segnale è a + 90 gradi e l’altro a 0 gradi la fase risultante dall’interazione è a + 45 gradi con un livello in calo rispetto al + 6 dB dell’accoppiamento perfetto dato dallo sfasamento in atto. Più c’è differenza di livello tra i segnali e meno questo non corretto incrocio di fase inciderà sul calo/somma del livello.
Più i picchi di fase sono verso le basse frequenze e più ritardo di fase si ha (fig. 36).
fig. 36

PROCESSO DI VERIFICA E CALIBRAZIONE
PER IL METODO SULLA TARATURA E CALIBRAZIONE P.A. VEDI ARTICOLO: Taratura e Calibrazione P.A.
Considerazioni di Mix
Le vocali hanno un fattore di cresta basso, simile al 3 dB dell’onda sinusoidale in quanto molto vicine come distribuzione. Le consonanti invece sono Picchi e quindi valori di cresta alti (più dinamica). Il rumore rosa fattore di cresta di 12 dB (adatto per le misurazioni medie in considerazione di musica e parlato).
Per quanto riguarda la voce, lavorare con compressore impostato sul Peak consente di livellare le consonanti alle vocali mantenendo un alto livello dinamico senza andare ad intaccare la parte delle vocali di base di più bassa dinamica rispetto alle consonanti, lavorando invece sul valore RMS si riduce l’intera dinamica vocale.
Considerazioni Finali
Il Range dinamico dichiarato per Finali di Potenza, Microfoni, DSP, Altoparlanti, ecc…è spesso riferito ad una data frequenza o media di più frequenze, questo perché a diverse frequenze il dispositivo ha generalmente uno spettro di rumore differente, questo spesso anche per il MAX Watt o MAX dBSPL sopportabile, questo fa variare il range dinamico effettivo. Generalmente alle basse frequenze si ha il più alto range dinamico.
Monitoraggio Performance
Il PA Manager non ha solo il compito di analizzare le performance dell’impianto audio, seguendo la corretta installazione come da progetto, tarando e sincronizzando il tutto e monitorando per quanto possibile la risposta durante l’evento.
Ha anche la responsabilità di controllare e monitorare lo stato del processore e finali di potenza, non solo per le operazioni di settaggio del DSP al fine di sincronizzare, livellare ed equalizzare il segnale audio ma anche del comportamento stesso del Finale di Potenza durante la performance dal vivo.
I moderni amplificatori finali possiedono DSP integrati ma lo stesso discorso solo in maniera più contenuta nelle operazioni di monitoraggio vale anche per i DSP esterni.
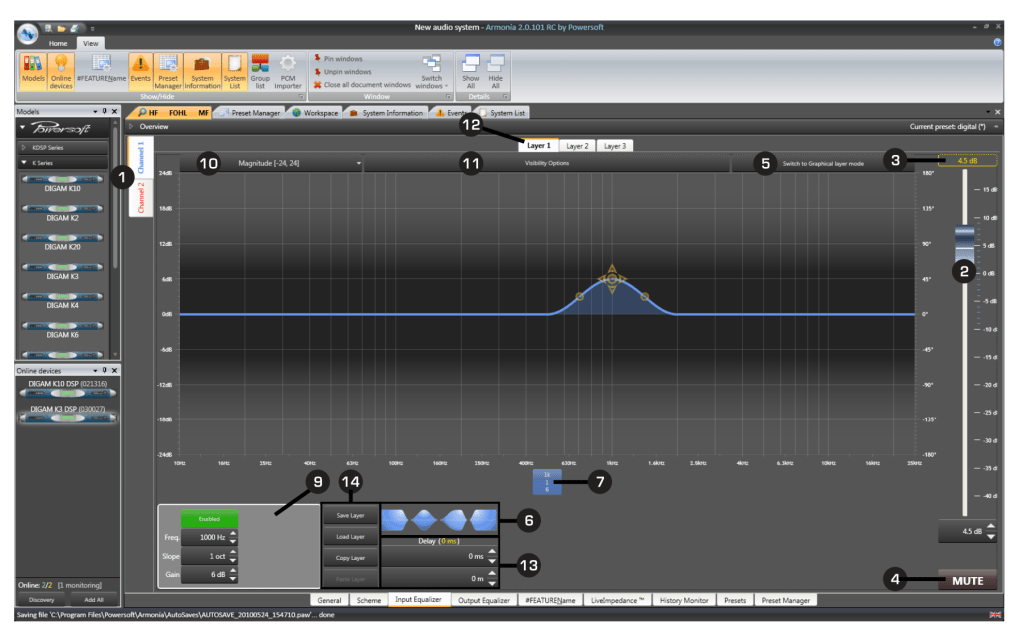
Attraverso il DSP quindi il PA Manager è in grado di gestire le operazioni di livellamento del “volume” di uscita ed ingresso del DSP stesso o anche del finale di potenza se integrato, dell’applicazione di ritardi temporali per il sincronismo, della finalizzazione dell’equalizzazione tonale per il segnale di ingresso o di uscita e impostare i Crossover di taglio dove necessari (fig. 37).
Fig. 37
Finestra Crossover

Equalizzazione
Ormai tutti i DSP sono controllabili in remoto da Computer e questo agevola di molto la velocità delle operazione e le procedure di settaggio e test.
Basterà mettere in Link (generalmente attraverso cavi di rete, ed in utilizzo di Switch), i vari DSP o Finali di Potenza con DSP integrato e tramite Software proprietario appositamente impostato per interfacciarsi correttamente con la rete si potranno visualizzare e gestire i processori (fig. 38).
Fig. 38
Collegamento in Daesy Chain dei vari processori direttamente al PC o tramite Switch, in alcuni casi controllabili anche via WiFi.
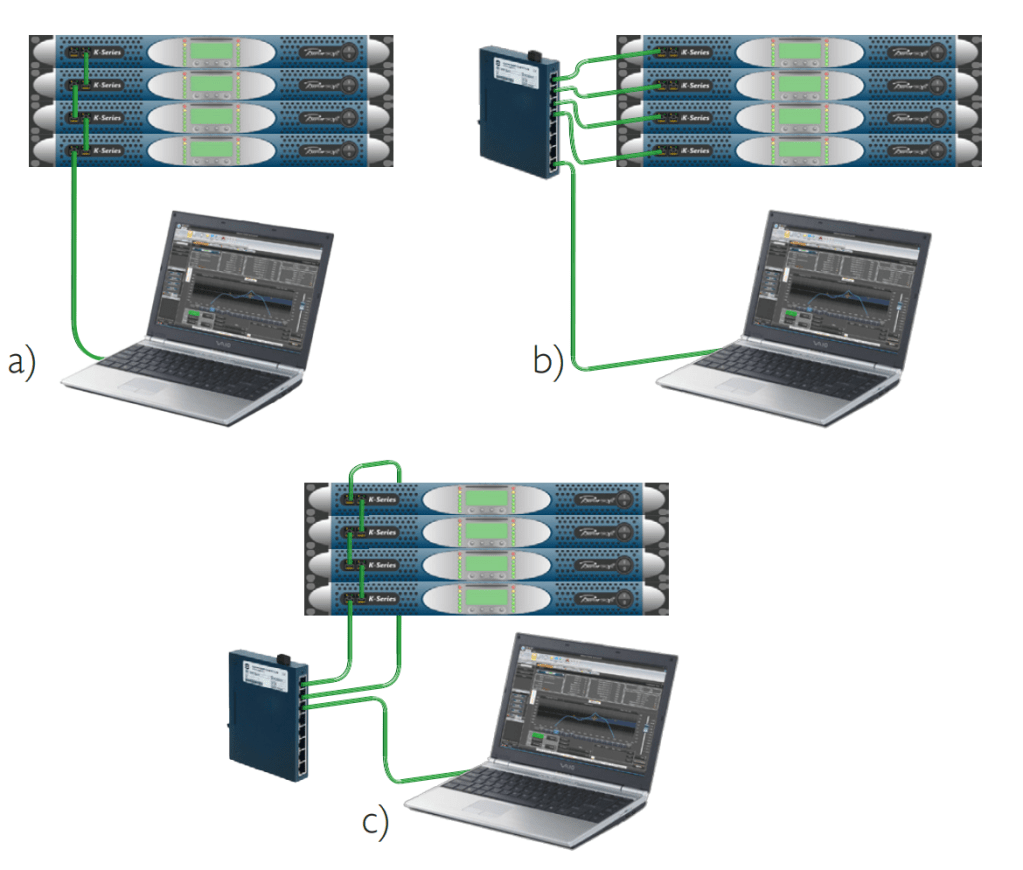

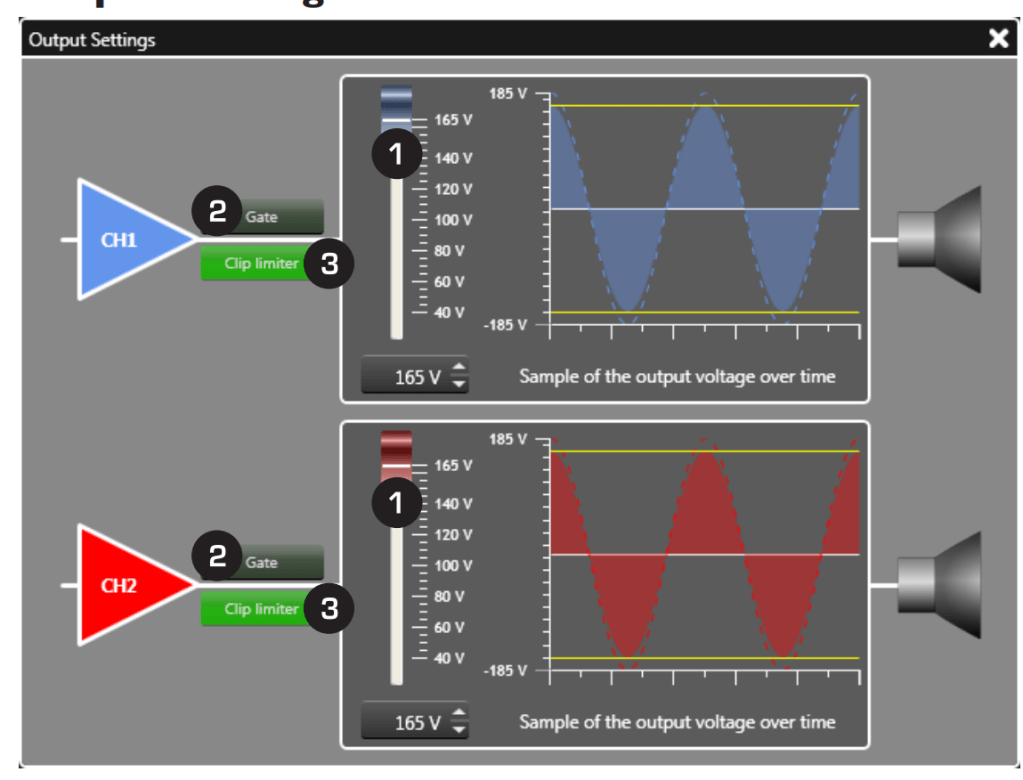
Dal Software il PA Manager come detto controlla tutti i parametri di livello, tempo ed EQ. ma anche il Routing del segnale dall’ingresso all’uscita, quindi scegliere la strada che deve percorre il segnale e quali parametri processano quel segnale dallo stadio di ingresso allo stadio di uscita, e perfino sommare ingressi verso una o piu uscite (fig. 39).
Fig. 39

Alcuni DSP integrati a differenza di quelli esterni permettono anche il controllo di impostazioni del Finale di Potenza stesso, come ad esempio il controllo del Damping (fig. 40).
Fig. 40
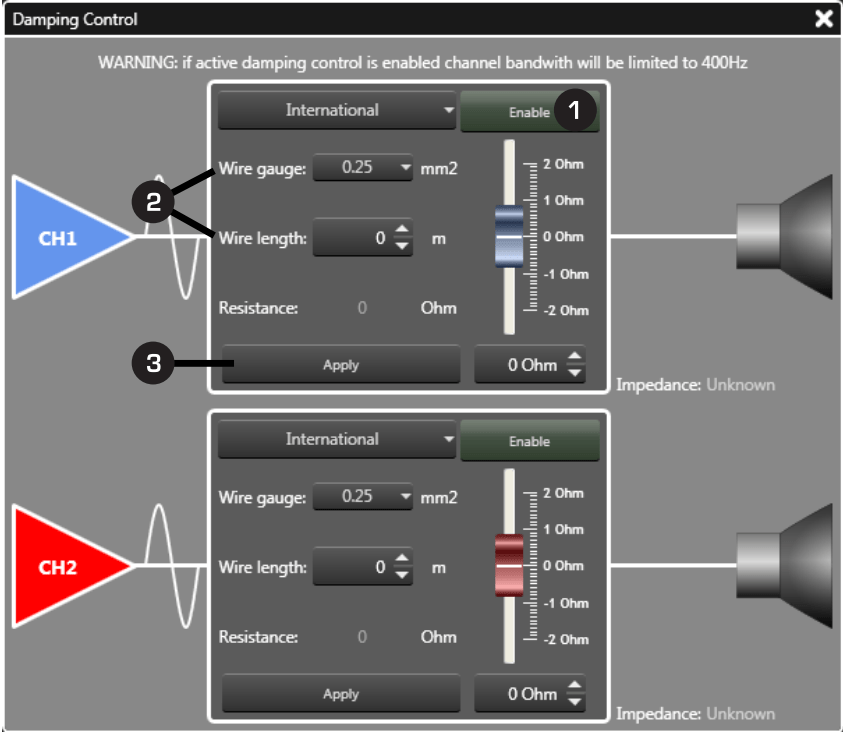
In pratica è possibile inserire dati sulla sezione e lunghezza del cavo ed il sistema in automatico correggere i parametri di amplificazione per compensare la perdita in bassa frequenza data in bassa frequenza da cavi con sezione e lunghezza non ottimali.
E’ possibile inoltre trovare una sezione di controllo dell’andamento dei valori di impedenza che ti dicono se l’amplificatore e l’altoparlante stanno rispondendo bene o se ci sono dei malfunzionamenti, come anche il valore della temperatura del Finale, dei valori di tensione e corrente di ingresso ed uscita (fig. 41).
Fig. 41


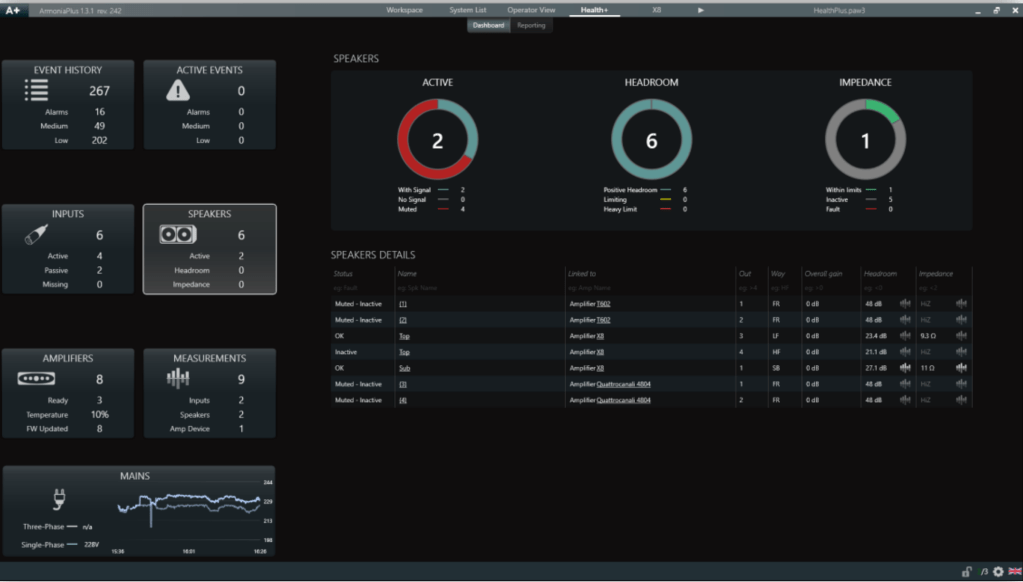
Il sistema monitora costantemente l’impedenza rilevata del diffusore/altoparlante e se l’impedenza supera determinate soglie limite (considerate come range di regime ottimale di funzionamento dell’altoparlante) notifica con un allarme che il sistema ha dei problemi. “Per questo si consiglia sempre di utilizzare sistemi multi amplificati (bi-amplificati, tri-amplificati, ecc..), cosi da avere un amplificatore ed un controllo diretto dei singoli altoparlanti.
Attraverso il monitoraggio dell’Headroom è poi possibile sapere costantemente quanta tensione in uscita e quindi “volume” è possibile dare, se si può alzare il volume o se è già al massimo e quanto range si ha a disposizione.
E’ possibile inoltre monitorare lo stato degli ingressi e definire collegamenti ridondanti, in questo caso il Finale di Potenza ha ingressi sia Analogici (XLR), che Digitali (AES/EBU, DANTE), è possibile collegare tutti gli ingressi, definire delle priorità di ridondanza quindi dove deve prendere il segnale da Amplificare e quali sono quelli ridondanti, poi impostare in modo automatico o manuale lo Switch in caso di malfunzionamento di una linea, cosi che in automatico o su richiesta di intervento manuale parte subito quella impostata come seconda linea di priorità di ridondanza. Questo passaggio se automatico avviene in una frazione di secondo, ai più non percettibile (fig. 42).
Fig. 42

Acquista Processori Audio dai principali Store


