

SAMPLE RATE CONVERTER
Come promesso nel precedente articolo dopo una lunga carrellata di test nella scelta dei generatori di tono e rumore più adeguati ad analisi di software ed hardware veniamo ora ad analizzare i primi SRC ( Sample Rate Converter ). In questo articolo vedremo alcuni pre-test eseguiti per capire meglio il successivo comportamento che avranno i test comparativi veri e propri degli SRC, in modo da non dover spiegare per ogni tipo di conversione il perchè succede questo, in più vedremo alcune altre indicazioni sull’utilizzo o meno del dither durante le varie fasi di conversione.
Introduzione
Il funzionamento e la struttura non chè utilizzo di un convertitore di campionamento/quantizzazione verrà analizzato quando parleremo di audio digitale. Per questo tipo di analisi basti sapere che tanto più trasparente è la conversione del campionamento e/o quantizzazione di un segnale audio ( quindi meno introduzione di distorsioni ed armoniche ) e tanto più di qualità sarà.
In questo articolo compareremo Sample Rate Converter Sincroni e Offline su software ( il sincrono può convertire solo un tipo di campionamento alla volta, offline è quindi non in tempo reale, per cui è necessario caricare un file audio, determinare i valori di conversione ed effettuare il processamento risultante su di un nuovo file audio o in sovrascrittura del precedente ).
n.b. Gli SRC sincroni ed offline sono i migliori dal punto di vista qualitativo, per cui quando possibile utilizzare sempre questi.
Un’altro fattore che andremo a considerare in questa serie di test è la qualità e stabilità del Dither.
Il Dither è necessario ( anche se come vedremo non sempre e solo in certi casi di conversione ), quando convertiamo audio digitale verso 24 bit – 16 bit per evitare il troncamento del segnale audio nei LSB ( i bit meno significativi ).
Esistono differenti tipologie di dither, ognuna in grado di colorire o rendere più trasparente il suono finale risultante dalla conversione. Per i nostri test analizzeremo in comparazione lo stesso dither per capire quale sia generato e distribuito nel modo più trasparente sul segnale audio convertito.
Una dimostrazione dell’effettivo miglioramento qualitativo nell’introduzione del dither in questo tipo di processi di conversione la vediamo nella figura 1.
fig. 1 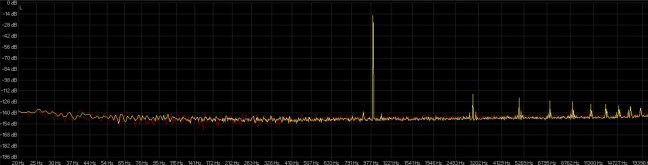
Nella figura 1 la linea rossa mostra una conversione audio digitale senza l’utilizzo del dither, la gialla invece mostra la stessa conversione ma con l’utilizzo di un tipo di dither.
E’ chiaro come la linea gialla ( presenza di dither ) sia più lineare e quindi abbia consentito una migliore conversione audio.
Un’altro parametro che è possibile trovare nei SRC ma più in generale in qualsiasi analizzatore di spettro come quello che utilizziamo per questa serie di articoli ed in qualsiasi processore convolver in cui l’analisi e processamento audio è realizzata tramite filtri e risposte all’impulso ( analizzeremo meglio i convolutori quando parleremo di audio digitale ) è il grado di risoluzione dell’FFT, quindi la possibilità di scegliere quanti più punti utilizzare del segnale audio in ingresso per il processamento.
Tanti più punti si prelevano per l’analisi e tanto più il processamento sarà qualitativo e trasparente a scapito però di una maggiore latenza di analisi ( servirà più tempo per analizzare ogni singolo punto ), più latenza è sinonimo anche di un maggiore impoverimento della qualità audio finale soprattutto per quanto riguarda l’ascolto, quindi in fase di conversione D/A.
In questa serie di analisi utilizzeremo sempre il massimo della risoluzione possibile per il tipo di software sotto test, per quanto riguarda la qualità audio finale di ascolto questa dipenderà dalla qualità di ogni singolo convertitore D/A che uno utilizza.
Per comparazione in figura 2 un’immagine che rappresenta il segnale audio utilizzato per il test del dither in figura 1 solo utilizzando un grado di risoluzione FFT inferiore.
fig. 2

Si nota chiaramente come in comparazione della figura 1 e 2 anche una conversione senza dither sia più lineare rispetto ad una conversione con dither ma con più bassa risoluzione FFT ( da qui la sua importanza ). Si capisce anche come per avere una corretta trasparenza di conversione in bassa frequenza servano molti più punti rispetto a quelli che servono per una corretta trasparenza di conversione in alta frequenza.
Per chiarezza i punti utilizzati in figura 1 sono 65536, quelli in figura 2 sono 2048.
Il minimo di punti utili per avere una buona trasparenza in bassa frequenza che si parli di conversione ma anche di semplice riproduzione o registrazione sarebbe 16384. Questi valori sono limitati nel loro utilizzo dalle capacità stesse del software che dalle prestazioni del computer utilizzato.
Nei nostri test verranno fatte comparazioni con e senza utilizzo di dither sia per illustrazione che per necessità a certi valori di quantizzazione. Per il dither digitale quello utilizzato è il TPDF ( dither triangolare ) lineare e senza colorazioni, adatto a questo tipo di test e presente in quasi tutti i tipi di software ed hardware ( uno standard ).
Verranno utilizzate le più comuni risoluzioni con cui generalmente ci si trova a lavorare in campo hardware e software quali:
| Risoluzioni di conversione per i test ( bit-Khz ) | ||||||||
| 16-44.1 | 16-48 | 24-48 | 24-96 | 24-192 | 32-192 | 32-384 | 32FP-192 | 64FP-384 |
I file e le conversioni sotto test sono sempre riferite a file non compressi e conversioni verso file non compressi.
Uno dei limiti dei test è quello di avere una massima risoluzione di analisi FFT fino a 96 Khz, comunque ottimale per rilevare le caratteristiche di conversione in banda audio udibile che è di nostro fondamentale interesse. Lo spettrogramma invece lavora fino ai più alti livelli di campionamento, quali 384 Khz.
Non verranno mai effettuate conversioni verso stesso campionamento e stessa quantizzazione ( dovrà sempre essere differente almeno uno dei due parametri ) in quanto non utile e andrebbe solo a peggiorare la qualità finale soprattutto per convertitori non di qualità.
n.b. Se come vedremo in alcuni esempi soprattutto sovracampionare non porta benefici meglio lasciare il campionamento com’è in quanto il filtro D/A dovrà agire su di un range di frequenze quindi presenza di suono e rumore su molte più frequenze tanto più il campionamento di conversione è elevato, quindi maggiore stress.
- Per la cronaca come vedremo dai test, la maggior parte delle distorsioni introdotte durante la fase di conversione sono incentrate verso le prime armoniche di una fondamentale e nel range di frequenze medio-alte ed alte.
A parte questo non molti sono software o hardware che permettono di regolare alcuni parametri di campionamento come la scelta della posizione del filtro e sua pendenza ( per esperti e sperimentazioni ), per questo verrà sempre usato uno standard comune a tutti come ad esempio per un campionamento a 44.1 Khz il filtro passa basso ha la sua frequenza di taglio a circa 22 Khz, mentre dove vi sia la possibilità di regolare la pendenza del filtro verranno fatte sperimentazioni al fine di ottenere la pendenza con il miglior risultato possibile ( in termini di trasparenza ).
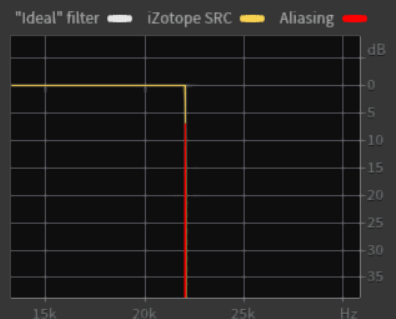
Dei vari SRC su software utilizzati per i nostri test solo iZotope RX5 permette di lavorare sulla frequenza di taglio e pendenza del filtro, la frequenza di taglio verrà lasciata come standard mentre la pendenza dopo vari test e soprattutto grazie alle capacità di processamento del software e suo algoritmo è risultata una pendenza perpendicolare alla frequenza di taglio ( fig. 3 ) ( valori ancora oggi impossibili da ottenere senza elevati fenomeni distorsivi con apparecchiature digitali hardware ).
fig. 3
Alcune note sull’utilizzo del Dither al variare della quantizzazione e del segnale di test.
Prima di partire con i test è bene fare chiarezza sul reale utilizzo del dither, in quanto che da sperimentazioni fatte dipende molto dal tipo di segnale audio in ingresso.
Per fare alcuni esempi in figura 4 abbiamo la comparazione della risposta in frequenza di una sinusoide a 16 bit 44.1 Khz data da una conversione con utilizzo di dither ( risposta di colore giallo ) e senza utilizzo di dither ( risposta di colore rosso ).
fig. 4 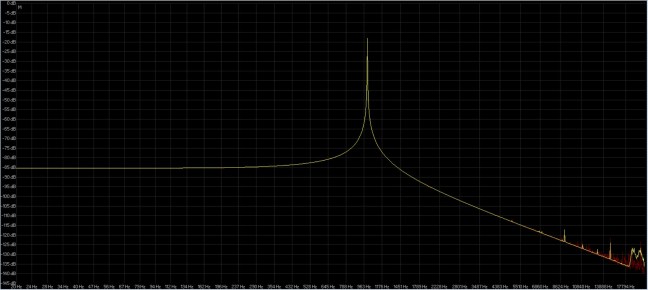
E’ chiaro come la risposta in frequenza ( giallo ) sia più lineare di quella di colore ( rosso ) soprattutto in alta frequenza, e da qui si capisce come in questo caso sia utile utilizzare il dither. Questo avviene anche perchè il livello armonico generato oltre la sinusoide a 1 Khz è ben più elevato del rumore introdotto dal dither ( a 16 bit generalmente si presenta come rumore a circa – 96 dBFS se analogico ma in alcuni contesti variabile come soprattutto in ambito digitale in cui per il test della rappresentazione grafica in figura 4 è stato posto a circa – 130 dBFS ), elevato soprattutto nella parte bassa dove il livello armonico rimane stabile nell’intorno dei – 85 dBFS ( + 45 dBFS rispetto al rumore di dither ), ed in parte alta fino a circa 18 Khz in cui oltre si nota una risonanza causata probabilmente dal rumore di dither.
Difatti in un secondo test ( fig. 5 ) è stata presa una sinusoide con contributo armonico molto inferiore al valore energetico del rumore del dither in gran parte della banda audio analizzata, da questo test si capisce come la risposta in frequenza ( giallo ) che è priva di dither abbia una sinusoide tonale uguale alla risposta in frequenza ( rosso ) che presenta dither ma con contributo armonicco medio molto inferiore, quindi un suono più pulito.
fig. 5 
In questo caso l’applicazione del dither per la conversione ha peggiorato la qualità audio finale introducendo un rumore di fondo maggiore.
Per questi motivi con sinusoidi, rumori o suoni con banda in frequenza limitata, inferiore alla banda impegnata dal rumore dither, è sempre bene effettuare processamenti senza dither o di comparazione con aggiunta di dither per valutare un effettivo miglioramento del segnale audio grazie alla presenza del dither o un effettivo peggioramento del segnale audio dovuto alla presenza di un rumore di fondo ( per molti impercettibile soprattutto a 24 bit ). Per suoni broadband con valore energetico sopra al rumore di dither l’applicazione di un adeguato dither è fondamentale.
Alcune considerazioni sulle armoniche di un segnale audio dai test effettuati possono essere che, presupponendo l’utilizzo di dither per ottimizzare un segnale con rumore armonico di livello energetico superiore a quello del dither, a 16 bit l’utilizzo del dither migliora sensibilmente la linearità delle armoniche riducendone cosi possibili enfatizzazioni e risonanze, mentre a 24 bit il dither aiuta a controllare e tenere bassa la distorsione armonica ( riducendone significamente la quantità, migliorando il valore THD% ). Dai 32 bit in su il dither è irrilevante e non utile ai fini di un miglioramento qualitativo, anzi il rumore introdotto va solo a peggiore la qualità complessiva finale.
Nei nostri test il dither verrà o meno applicato di conseguenza secondo il più trasparente e minor contributo armonico di conversione.
A livello digitale e software è possibile scegliere se utilizzarlo o meno ( in alcuni casi può essere utile applicare un dither a 24 bit per una conversione a 16 bit se il contributo armonico rimane sopra al valore dul rumore di dither a 24 bit ), mentre a livello di ingressi A/D ed eventuali uscite D/A con conversione di campionamento analogico è sempre presente e non gestibile in quanto parte integrante del circuito convertitore ed in considerazione di un segnale audio a piena banda.
n.b. In futuro spero andranno a realizzare un sistema di dither in grado di rilevare l’effettiva banda di frequenze in cui transita il segnale audio ed applicare ad essa il dither filtrato solo per quel tipo di banda.
Ulteriori pre-test
Utilizzo Dither verso stesso valore di quantizzazione ma diverso campionamento.
E’ stato eseguito anche un test per capire se in fase di conversione del campionamento ma verso uno stesso valore di quantizzazione sia o meno necessario l’utilizzo del dither. Due esempi grafici di conversione a 16 bit considerano un segnale audio tonale di 16 bit 96 Khz convertito a 16 bit 44.1 Khz ( fig. 6 ) ed un segnale audio broadband come il rumore bianco sempre di 16 bit 96 Khz convertito a 16 bit 44.1 Khz ( fig. 7 ).
fig. 6 
fig. 7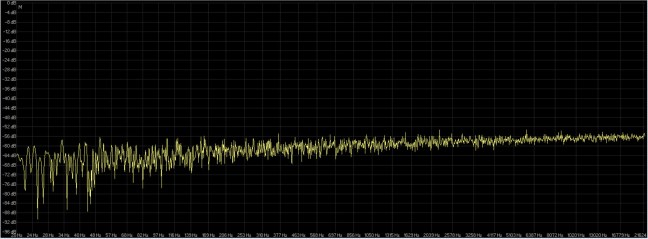
Dai due grafici è facile capire come il dither verso una conversione a stessa quantizzazione non sia necessario, anzi per suoni tonali o con bande limitate in cui il valore armonico è inferiore a quello che va a generare il dither, il rumore del dither stesso produce maggiori alterazioni ed impoverimento della qualità audio, risposta ( giallo ) segnale con dither, risposta ( rosso ) segnale senza dither. Anche in figura 7 si capisce come il dither non sia necessario in quanto la risposta ( giallo ) è il segnale con dither, la risposta ( rosso ) è il segnale senza dither, perfettamente mecciati anche invertendo i fattori di analisi.
In figura 8 abbiamo una controprova a 24 bit, con il segnale di conversione tonale da 24 bit 96 Khz a 24 bit 44.1 Khz, ed in figura 10 un rumore bianco 24 bit 96 Khz convertito a 24 bit 44.1 Khz.
fig. 8 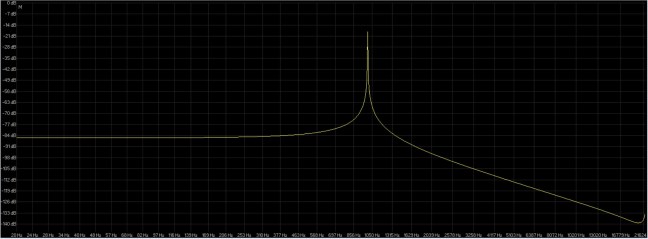
fig. 9 
Dalla figura 8 e 9 si può capire che tanto più alta è la risoluzione di quantizzazione e tanto meno l’utilizzo di dither convertendo a stessa quantizzazione è necessario, quindi conferma il fatto che non serve sia per il tonale o bande limitate che per rumori e segnali broadband.
Downsamplig e Downquantization verso stesso campionamento e quantizzazione partendo da differenti valori.
Un’ultimo test definisce il fatto che a parità di campionamento e quantizzazione di destinazione ( quindi la risoluzione audio che si vuole ottenere ) partire convertendo da un più alto valore di quantizzazione e campionamento migliora sicuramente il file risultante dalla conversione.
In figura 10 un file convertito a 16 bit 44.1 Khz partendo da una risoluzione di 24 bit 48 Khz, in figura 11 lo stesso file a 16 bit 44.1 Khz partendo invece da una risoluzione di 24 bit 192 Khz, mentre in figura 12 lo stesso file a 16 bit 44.1 Khz ma partendo da una risoluzione di 32FP bit 96 Khz.
fig. 10 
fig. 11 
fig. 12 
Come è facile notare in figura 12 quindi il file a 16 bit 44.1 Khz convertito dalla più alta risoluzione sotto test ( 32FP bit 96 Khz ) è quello con il minor contributo armonico, poi seguito dal segnale in figura 11 ( 24 bit 192 Khz ) ed infine dal segnale in figura 10 ( 24 bit – 48 Khz ), se pur tra la figura 10 ed 11 vi siano lievi differenze. Questo conferma il fatto che a risoluzioni più elevate il file originale presenta sempre più linearità nella risposta in frequenza e minor contributo armonico rispetto a risoluzioni più basse ( considerando sempre l’idealità dei casi, ovviamente per uno scarso convertitore e/o generatore si possono avere casi differenti ), per questo anche facendo un downsampling e/o downquantization le varie armoniche e distorsioni introdotte saranno sempre più contenute rispetto a convertire da file con più bassa risoluzione. Tanto più pulito sarà il segnale originale a più alta risoluzione e tanto migliore risulterà la conversione in downsampling o downquantization.
Per comparazione vediamo anche i risultati dell’FFT, in figura 13 la risposta ( giallo ) rappresenta il segnale audio convertito da 24 bit 192 Khz mentre la risposta ( rosso ) il segnale audio convertito da 24 bit 48 Khz.
fig. 13 
E’ possibile notare come i risultati maggiori che confermano un miglioramento nel processo di conversione da una risoluzione più alta, siano in medio alta ed alta frequenza, in cui la conversione da 24 bit 192 Khz mantiene un livello armonico più basso.
n.b. Vi è invece un leggero incremento rispetto alla risoluzione a 24 bit 48 Khz in prossimità della sinusoide tonale, questo molto probabilmente dovuto all’instabilità del SRC che come vedremo non esiste un SRC che lavori ottimamente a tutte le frequenze e quantizzazioni, ma ci sono SRC che lavorano meglio ad un certo tipo di risoluzione ed altri che lavorano meglio ad un’altro tipo di risoluzione.
In figura 14 la comparazione dell’FFT per la conversione da 24 bit – 192 Khz ( rosso ) con l’FFT per la conversione da 32FP bit 96 Khz ( giallo ).
fig. 14
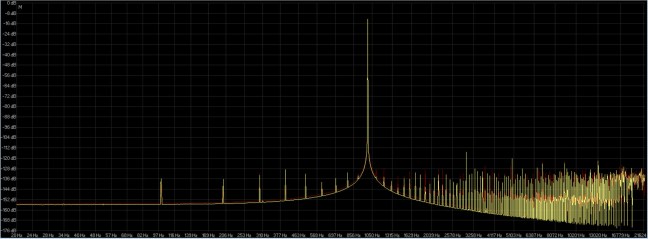
Come ulteriore conferma dal grafico FFT si vede come la conversione a 32FP bit 96 Khz sia armonicamente migliore ( le mantiene più basse ) della conversione a 24 bit 192 Khz, in questo caso anche un po in bassa frequenza.
Per chiarezza come accennato anche in passato in questa serie di articoli ridurre il campionamento porta un risultato qualitativo molto inferiore rispetto a ridurre la quantizzazione, la dimostrazione in figura 15 – 16 – 17.
fig. 15 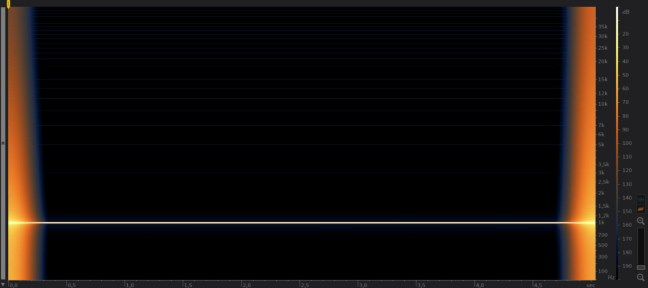
fig. 16 
fig. 17 
In figura 15 il file originale a 32FP bit 96 Khz, in figura 16 un dowsamplig a 32FP bit 44.1 Khz, si nota un gran incremento di armoniche ed un impoverimento della precisione del tono che da entro 0,3 secondi di impulso nel file originale passa ad entro 0,7 secondi, questo significa una peggiore linearità della risposta ed un ingresso di armoniche distorsive nel segnale audio. In figura 17 invece un downquantization a 16 bit 96 Khz, come si nota la precisione dell’impulso rimane entro i 0,3 secondi, mentre le armoniche raggiungo valori energetici più elevati rispetto al downsampling ma sempre in misura più contenuta a segno di un mantenimento della precisone e linearità della risposta ma con un impoverimento della dinamica.
Direi che già dallo spettrogramma è molto chiaro e non c’è bisogno della controprova tramite grafico FFT.
Upsamplig e Upquantization verso stesso campionamento e quantizzazione partendo da differenti valori.
Come aspetto contrario quindi upsampling ( sovracampionamento ) e upquantization ( sovraquantizzazione ) abbiamo alcune rappresentazioni grafiche in figura 18-19-20.
fig. 18 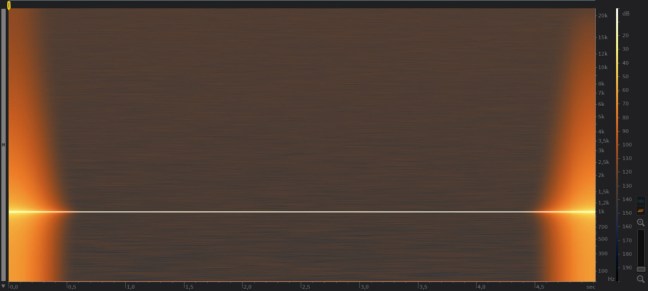
fig. 19 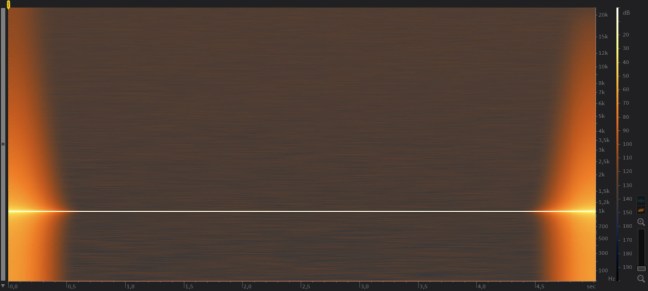
fig. 20 
In figura 18 il file originale a 16 bit 44.1 Khz, in figura 19 il file sovraquantizzato a 32FP bit 44.1 Khz, difficile notare grandi differenze di qualità nella fase di sovraquantizzazione, per cui si può confermare che sovraquantizzare non porta benefici.
Anche il grafico di comparazione FFT in figura 21 dimostra quanto sopra, 16 bit 44.1 Khz ( rosso ) 32FP bit 44.1 Khz ( rosso ).
fig. 21 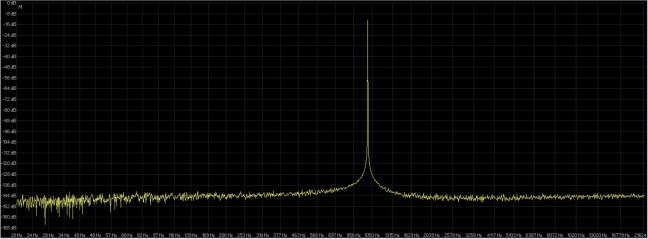
Perfettamente mecciati.
Sovraquantizzare porterà solo benefici in caso poi di dover processare nuovamente il segnale audio, potendo lavorare ad una risoluzione più elevata.
In figura 20 in cui vi è invece un sovracampionamento si visualizzano diversi fattori di diversità, primo di tutti l’aumento dei livelli di distorsione in banda audio ( 20 hz – 20 Khz ).
In figura 22 il grafico FFT della risposta in frequenza del file originale a 16 bit 44.1 Khz e in figura 23 il grafico della risposta in frequenza della conversione a 16 bit 192 Khz.
fig. 22 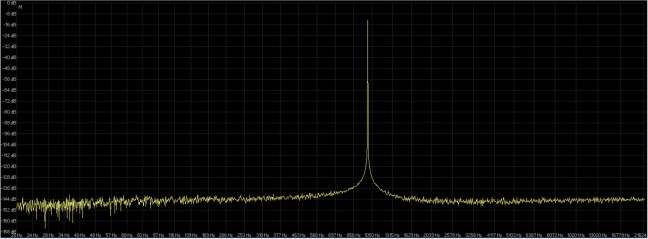
fig. 23 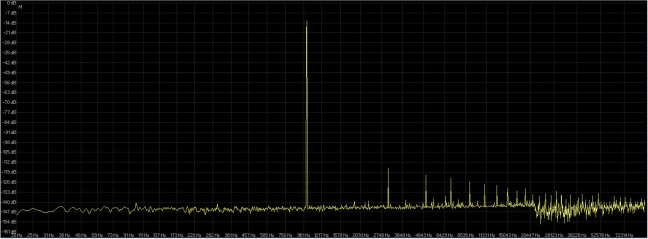
In banda audio 20 hz – 20 Khz la risposta del sovracampionamento è più lineare ( fig. 23 ) ma se andiamo a vedere bene il livello energetico in figura 24 è facile notare come la media sia più alta del file originale, sinonimo di introduzione di distorsioni durante la fase di conversione ( questo perchè un convertitore ideale e trasparente al 100% non esiste, tutti introducono un minimo di ditorsione nella fase di conversione ).
fig. 24 
E’ chiaro dalla figura 24 come il livello di distorsione della conversione a 192 Khz ( giallo ) sia energeticamente più elevato rispetto al file originale a 44.1 Khz ( rosso ) soprattutto in bassa frequenza, leggermente migliore in media frequenza. Anche in medio alta ed alta frequenza come si nota in figura 23 si vede chiaramente come vi siano delle frequenze che tendano a risuonare e prendere valore energetico come riporto anche in figura 25.
fig. 25 
Per cui a livello di armoniche e distorsione sovracampionare non porta benefici.
Di contro però come si vede dalla comparazione delle figure 23 e 24 la precisione del tono è molto superiore per il segnale sovracampionato che rimane stabile e preciso fino anche a – 140 dBFS, mentre il tono del file originale rimane preciso e stabile fino a circa – 120 dBFS, ben 20 dBFS di differenza.
Un’altro fattore che è possibile notare in figura 23 è il livello armonico generato oltre la banda audio udibile che riporto in figura 26, il segnale con campionameno a 44.1 Khz ha generalmente come standard la frequenza di taglio per il filtro anti-alias a circa 22 Khz, se converto il segnale verso campionamenti più elevati come ad esempio 192 Khz la frequenza di taglio del filtro si sposta a 96 Khz per cui aumenterà la banda in cui vi sarà segnale audio prima di essere filtrata con pendenza “x”. Questa banda da 22 Khz a 96 Khz per un segnale originale a 44.1 Khz sarà composta da solo rumore. Per cui tanto migliore è il SRC e tanto più basso sarà questo contributo armonico.
fig. 26 
n.b. Un rumore, audio e tono a 44.1 Khz copre una risposta in frequenza fino a circa 22 Khz, mentre uno a 96 Khz copre una risposta fino a 48 Khz, più si alza la frequenza di campionamento e più un eventuale segnale di test è in grado di coprire una banda più ampia, se invece effettuo un downsampling la banda utile si ridurrà di conseguenza. Da standard è sempre la metà ma alcuni processori SRC sono in grado come visto prima di scegliere e gestire tale frequenza di taglio. Lo stesso discorso vale per qualsiasi convertitore A/D e D/A tanto più è in grado di tenere bassi i livelli di distorsione oltre la banda audio 20 hz – 20 Khz e tanto migliore sarà.
Se sovracampiono e sovraquantizzo insieme ottengo un risultato come quello in figura 27 in cui vi è la risposta in frequenza di un tono a 16 bit 44.1 Khz convertito a 32FP 192 Khz.
fig. 27 
In figura 28 la comparazione con il file originale.
fig. 28 
Non è cambiato molto rispetto a solo sovracampionare per la risposta in bassa e media frequenza e precisione del tono, ma in medio alta e alta come si vede in figura 29 i risultati sono ottenuti in positivo con la riduzione delle risonanze ed un livello di rumore oltre la frequenza di taglio del file originale sovracampionato come visto prima attenuato di circa – 33 dBFS.
fig. 29 
L’importanza delle armoniche oltre la banda audio udibile.
Un esempio di come varia e sia importante il controllo delle armoniche oltre la banda audio udibile per sovracampionamenti è visibile in figura 30.
fig. 30 
In figura 30 la risposta in frequenza ( giallo ) mostra l’andamento di un segnale audio a 16 bit 192 Khz, che come visto precedentemente presenta armoniche oltre il filtro passa basso in quanto il segnale è stato convertito da 16 bit 44.1 Khz a 16 bit 192 Khz. Ma lo stesso sarebbe un eventuale rumore per un segnale registrato o realizzato con risoluzione più alta di 44.1 Khz ( presenterebbe armoniche oltre la banda audio fino alla frequenza di taglio ).
A questo segnale è stato applicata un’equalizzazione attorno alla banda degli 7 Khz, come si nota dalla risposta in frequenza ( rosso ), oltre al boost evidente tra i 5 Khz e 11 Khz vi è un incremento delle distorsioni armoniche in banda audio udible e anche un notevole incremento delle distorsioni in banda audio oltre l’udibile fino alla frequenza di taglio del filtro di campionamento ( questo dovuto alle distorsioni introdotte dal processore, che anche in questo caso non è mai trasparente al 100% ). Tanto più il processamento è verso le basse frequenze e tanto meno verrà interessata dalle distorsioni la banda audio oltre l’udibile.
Tutta questa distorsione compresa quella oltre la banda audio udibile verrà utilizzata in qualsiasi fase di processamento sucessivo e su cui poi il filtro di taglio D/A lavorerà per la conversione finale in analogico sempre più stressato tanto più queste armoniche hanno valore.
Per ridurre questo fenomeno può essere utile utilizzare un filtro passa basso a 20 Khz di alta qualità alla fine della catena di un qualsiasi processamento ( per evitare di sommare filtri e creare maggiori problemi dovuti alla somma delle risonanze di ogni filtro ), il risultato è quello mostrato in figura 31.
fig. 31 
Nel grafico in figura 31 si vede la risposta ( giallo ) in cui è rappresentato l’andamento della risposta in frequenza dopo l’utilizzo di un equalizzatore e la risposta ( rosso ) in cui vi è l’utilizzo del filtro passa basso a 20 Khz dopo il processamento dell’eq. E’ chiaro il lavoro del filtro che mantiene più bassa la distorsione armonica oltre l’audio udibile migliorando qualsiasi prossimo processamento, soprattutto quello di conversione D/A.
Altre Soluzioni.
Una soluzione migliore per il down/upsampling e/o down/upquantization è quella di elevare la risoluzione al massimo possibile con migliore qualità possibile e poi effettuare down verso la risoluzione di interesse se questa è inferiore al massimo possibile.
In figura 32 un esempio comparativo tra la risposta in frequenza di un upsampling/quantization, risposta in frequenza ( giallo ) la conversione da 16 bit 44.1 Khz a 24 bit 44.1 Khz, risposta in frequenza ( rosso ) la conversione da 16 bit 44.1 Khz elevata a 32FP 192 Khz per poi downsampling/quantization a 24 bit 44.1 Khz.
fig. 32
Il risultato è decisamente molto simile anche invertendo i fattori, e anche dall’analisi dello spettrogramma.
Per questo è sempre bene utilizzare la filosofia di utilizzare meno passaggi possibili, quindi quando possibile fare solo upsamplig/quantization verso la risoluzione di interesse.
Se invece la conversione è solo verso downsamplig/quantization, in figura 33 abbiamo la risposta in frequenza comparativa tra due segnali a 16 bit 44.1 Khz in cui la prima risposta ( giallo ) è il segnale convertito partendo da 24 bit 96 Khz, mentre il secondo ( rosso ) è il segnale convertito partendo da 32FP bit 192 Khz.
fig. 33 
Dall’FFT in figura 33 è chiaro come la risposta in frequenza ( giallo ) quindi il downsampling da una più alta risoluzione sia migliore che da una più bassa. Linearità simile in bassa frequenza ma con minor risonanze, estensione dinamica delle armoniche inferiore in medio-alta ed alta ma contributo energetico medio più basso.
Anche lo spettrogramma conferma questa ipotesi.
fig. 34 
fig. 35 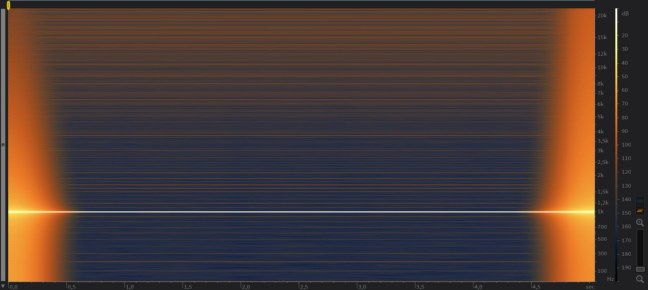
Come si può vedere lo spettrogramma in figura 35 ( conversione da 32FP bit 192 Khz ) presenta un contributo armonico più chiaro quindi di valore energetico più alto rispetto a quello in figura 34 ( conversione da 24 bit 96 Khz ), per cui lo spettrogramma dice il contrario, e cio’è che il downsampling diretto senza passare per un sovracampionamento porta più benefici. A questo punto a chi diamo ragione all’FFT o allo Spettrogramma ? direi all’ascolto finale in quanto che diversi convertitori possono presentare diverse risposte.
Si può dire allora che, in caso di utilizzo di un segnale di test TONALE o NARROWBAND in cui il contributo armonico ha valore e rilevanza durante le fasi di analisi è sempre bene non convertire alcun segnale audio a meno di non dover processare ulteriormente questo segnale per cui si considera sempre un sovracampionamento e/o sovraquantizzazione. Se invece il segnale è un rumore o segnale audio, la precisione di ogni singolo tono che costituisce l’onda complessa cosi generata è molto superiore ai valori di distorsione introdotti durante le fasi di conversione per cui è consigliato sempre sovracampionare e sovraquantizzare insieme, se possibile solo uno è sempre meglio sovracampionare e solo con un passaggio, senza arrivare a risoluzioni superiori per poi regredire.
In caso di dover ridurre valori di quantizzazione e/o campionamento partire sempre dalla più alta risoluzione possibile e se possibile alzare prima la risoluzione al livello massimo possibile con minime distorsioni e poi ridurre al valore desiderato ( come visto da paragonare ad una riduzione diretta, in quanto che dipende molto dal SRC utilizzato ).
n.b. Per salire si va diretti, per scendere si passa dalla risoluzione più alta o si va diretti in base al tipo di SRC utilizzato.
Se sovracampiono, eseguo rendering o bounce oltre i 44.1 Khz e sempre per comparazione ( perchè non è detto che porti sempre buoni risultati soprattutto se non si hanno processori di qualità ) può essere utile dopo qualsiasi processamento o comunque alla fine di una catena di processamenti ( esempio dopo l’utilizzo di una serie di plugin in una sessione di mastering ), ( possibilmente eseguire tramite software in modo da non stressare troppo il circuito analogico-digitale di conversione ) interporre un filtro passa-basso a 2o – 22 Khz, in modo da eliminare eventuali distorsioni di valore fuori dalla banda audio udibile introdotte dal processo di conversione ).
IMPORTANTE
Come vedremo dai vari test per segnali broadband in cui può facilmente rientrare anche un qualsiasi brano audio nel suo valore medio, i vari convertitori SRC non sono perfettamente trasparenti soprattutto nell’offrire in uscita un valore medio energetico trasparente, quindi come quello in ingresso. Ad esempio il valore medio RMS del mix o mastering che abbiamo fatto ad una determinata risoluzione andiamo poi a convertirlo ad un’altra per una qualsiasi necessità di modifica del formato e risoluzione attraverso l’utilizzo di SRC, facendo questo avremo spesso un’attenuazione del valore medio.
Per questo fare sempre un paragone di analisi tra il valore medio ( ma anche di picco ) del segnale in ingresso al SRC e quello in uscita, per porre vari rimedi e relativi boost se necessario, attraverso le impostazioni del convertitore ( se previste ).
Nel prossimo articolo finalmente visualizzeremo e compareremo i risultati delle conversioni dei vari SRC su software.
Altro su Test of Digital Audio Product:
Test of Digital Audio Product – I ( Scelta dei Segnali di Test ed Impostazione Analizzatori )
Test of Digital Audio Product – II ( Comparazione e scelta dei segnali Tonali )
Test of Digital Audio Product – III ( Comparazione e scelta dei Rumori )
Test of Digital Audio Product – IV ( Comparazione di altri Generatori di Tono )
Test of Digital Audio Product – V ( Comparazione di altri Generatori di Rumore )
Test of Digital Audio Product – VII ( Conversione verso 16 bit 44.1 Khz )
Test of Digital Audio Product – VIII ( Conversione verso 16 bit 48 Khz )
Test of Digital Audio Product – IX ( Conversione verso 24 bit 48 Khz )
Test of Digital Audio Product – X ( Conversione verso 24 bit 96 Khz )
Test of Digital Audio Product – XI ( Conversione verso 24 bit 192 Khz )
Test of Digital Audio Product – XII ( Conversione verso 32 bit 192 Khz )
Test of Digital Audio Product – XIII ( Conversione verso 32 bit 384 Khz )
Test of Digital Audio Product – XIV ( Conversione verso 32FP bit – 192 Khz )
Test of Digital Audio Product – XV ( Conversione verso 64FP bit 384 Khz )
Test of Digital Audio Product – XVI ( Audacity Tone and Noise generator Test )
Acquista prodotti iZotope da: Amazon.it – Thomann
Acquista prodotti Steinberg da: Amazon.it – Thomann
Acquista Plugin da: Thomann
Acquista Digital Audio Product dai principali Store
Digital Mixer
![]()
Digital Converter
![]()
Interfacce Audio Digitali
![]()
![]()
Digital Crossover e Management
![]()
Stage Box – Splitter Digitali
![]()
![]()
Audio Router ed Accessori Digitali
![]()
![]()

Un pensiero su “Test of Digital Audio Product – VI”